Prompt engineering is undoubtedly the most critical skill in developing an LLM-native application, as crafting the right prompts can significantly impact your application’s performance and reliability.
Over the past two years, I’ve been helping organizations build and deploy dozens of LLM applications for real-world use cases. This experience gave me valuable insights into effective prompting techniques.
This article, informed by the LLM Triangle Principles, presents eight practical tips for prompt engineering to level up your LLM prompting game.

(Generated with Midjourney)
Throughout this article, we'll use the “Landing Page Generator” example to demonstrate how each tip can be applied to enhance a real-world LLM application.
Start by defining the objective for each agent or prompt. Stick to one cognitive process type per agent, such as: conceptualizing a landing page, selecting components, or generating content for specific sections.
Having clear boundaries maintains focus and clarity in your LLM interactions, aligning with the Engineering Techniques apex of the LLM Triangle Principle.
For example, avoid combining different cognitive processes in the same prompt, which might yield suboptimal results. Instead, break these into separate, focused agents:
def generate_landing_page_concept(input_data: LandingPageInput) -> LandingPageConcept:
"""
Generate a landing page concept based on the input data.
This function focuses on the creative process of conceptualizing the landing page.
"""
pass
def select_landing_page_components(concept: LandingPageConcept) -> List[LandingPageComponent]:
"""
Select appropriate components for the landing page based on the concept.
This function is responsible only for choosing components,
not for generating their content or layout.
"""
pass
def generate_component_content(component: LandingPageComponent, concept: LandingPageConcept) -> ComponentContent:
"""
Generate content for a specific landing page component.
This function focuses on creating appropriate content based on the component type and overall concept.
"""
pass
By defining clear boundaries for each agent, we can ensure that each step in our workflow is tailored to a specific mental task. This will improve the quality of outputs and make it easier to debug and refine.
2. Specify Input/Output Clearly
Define clear input and output structures to reflect the objectives and create explicit data models. This practice touches on the LLM Triangle Principles' Engineering Techniques and Contextual Data apexes.
class LandingPageInput(BaseModel):
brand: str
product_desc: str
campaign_desc: str
cta_message: str
target_audience: str
unique_selling_points: List[str]
class LandingPageConcept(BaseModel):
campaign_desc_reflection: str
campaign_motivation: str
campaign_narrative: str
campaign_title_types: List[str]
campaign_title: str
tone_and_style: List[str]
These Pydantic models define the structure of our input and output data and define clear boundaries and expectations for the agent.
3. Implement Guardrails
Place validations to ensure the quality and moderation of the LLM outputs. Pydantic is excellent for implementing these guardrails, and we can utilize its native features for that.
class LandingPageConcept(BaseModel):
campaign_narrative: str = Field(..., min_length=50) # native validations
tone_and_style: List[str] = Field(..., min_items=2) # native validations
# ...rest of the fields... #
@field_validator("campaign_narrative")
@classmethod
def validate_campaign_narrative(cls, v):
"""Validate the campaign narrative against the content policy, using another AI model."""
response = client.moderations.create(input=v)
if response.results[0].flagged:
raise ValueError("The provided text violates the content policy.")
return v
In this example, ensuring the quality of our application by defining two types of validators:
Structure your LLM workflow to mimic human cognitive processes by breaking down complex tasks into smaller steps that follow a logical sequence. To do that, follow the SOP (Standard Operating Procedure) guiding principle of the LLM Triangle Principles.
In our example, we expect the model to return LandingPageConcept as a result. By asking the model to output certain fields, we guide the LLM similar to how a human marketer or designer might approach creating a landing page concept.
class LandingPageConcept(BaseModel):
campaign_desc_reflection: str # Encourages analysis of the campaign description
campaign_motivation: str # Prompts thinking about the 'why' behind the campaign
campaign_narrative: str # Guides creation of a cohesive story for the landing page
campaign_title_types: List[str]# Promotes brainstorming different title approaches
campaign_title: str # The final decision on the title
tone_and_style: List[str] # Defines the overall feel of the landing page
The LandingPageConcept structure encourages the LLM to follow a human-like reasoning process, mirroring the subtle mental leaps (implicit cognition "jumps") that an expert would make instinctively, just as we modeled in our SOP.
4.2 Breaking complex processes into multiple steps/agents
For complex tasks, break the process down into various steps, each handled by a separate LLM call or "agent":
async def generate_landing_page(input_data: LandingPageInput) -> LandingPageOutput:
# Step 1: Conceptualize the campaign
concept = await generate_concept(input_data)
# Step 2: Select appropriate components
selected_components = await select_components(concept)
# Step 3: Generate content for each selected component
component_contents = {
component: await generate_component_content(input_data, concept, component)
for component in selected_components
}
# Step 4: Compose the final HTML
html = await compose_html(concept, component_contents)
return LandingPageOutput(concept, selected_components, component_contents, html)
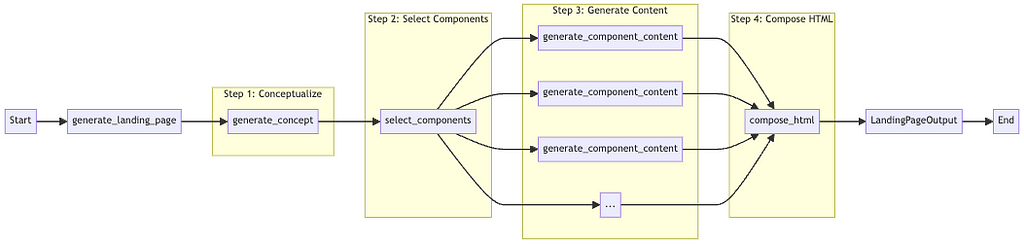
Illustration of the multi-agent process code. (Image by author)
This multi-agent approach aligns with how humans tackle complex problems — by breaking them into smaller parts.
5. Leverage Structured Data (YAML)
YAML is a popular human-friendly data serialization format. It’s designed to be easily readable by humans while still being easy for machines to parse — which makes it classic for LLM usage.
I found YAML is particularly effective for LLM interactions and yields much better results across different models. It focuses the token processing on valuable content rather than syntax.
YAML is also much more portable across different LLM providers and allows you to maintain a structured output format.
async def generate_component_content(input_data: LandingPageInput, concept: LandingPageConcept,component: LandingPageComponent) -> ComponentContent:
few_shots = {
LandingPageComponent.HERO: {
"input": LandingPageInput(
brand="Mustacher",
product_desc="Luxurious mustache cream for grooming and styling",
# ... rest of the input data ...
),
"concept": LandingPageConcept(
campaign_title="Celebrate Dad's Dash of Distinction",
tone_and_style=["Warm", "Slightly humorous", "Nostalgic"]
# ... rest of the concept ...
),
"output": ComponentContent(
motivation="The hero section captures attention and communicates the core value proposition.",
content={
"headline": "Honor Dad's Distinction",
"subheadline": "The Art of Mustache Care",
"cta_button": "Shop Now"
}
)
},
# Add more component examples as needed
}
sys = "Craft landing page component content. Respond in YAML with motivation and content structure as shown."
messages = [{"role": "system", "content": sys}]
messages.extend([
message for example in few_shots.values() for message in [
{"role": "user", "content": to_yaml({"input": example["input"], "concept": example["concept"], "component": component.value})},
{"role": "assistant", "content": to_yaml(example["output"])}
]
])
messages.append({"role": "user", "content": to_yaml({"input": input_data, "concept": concept, "component": component.value})})
response = await client.chat.completions.create(model="gpt-4o", messages=messages)
raw_content = yaml.safe_load(sanitize_code_block(response.choices[0].message.content))
return ComponentContent(**raw_content)
Notice how we're using few-shot examples to "show, don't tell" the expected YAML format. This approach is more effective than explicit instructions in prompt for the output structure.
6. Craft Your Contextual Data
Carefully consider how to model and present data to the LLM. This tip is central to the Contextual Data apex of the LLM Triangle Principles.
Don’t throw away all the data you have on the model. Instead, inform the model with the pieces of information that are relevant to the objective you defined.
async def select_components(concept: LandingPageConcept) -> List[LandingPageComponent]:
sys_template = jinja_env.from_string("""
Your task is to select the most appropriate components for a landing page based on the provided concept.
Choose from the following components:
{% for component in components %}
- {{ component.value }}
{% endfor %}
You MUST respond ONLY in a valid YAML list of selected components.
""")
sys = sys_template.render(components=LandingPageComponent)
prompt = jinja_env.from_string("""
Campaign title: "{{ concept.campaign_title }}"
Campaign narrative: "{{ concept.campaign_narrative }}"
Tone and style attributes: {{ concept.tone_and_style | join(', ') }}
""")
messages = [{"role": "system", "content": sys}] + few_shots + [
{"role": "user", "content": prompt.render(concept=concept)}]
response = await client.chat.completions.create(model="gpt-4", messages=messages)
selected_components = yaml.safe_load(response.choices[0].message.content)
return [LandingPageComponent(component) for component in selected_components]
In this example, we're using Jinja templates to dynamically compose our prompts. This creates focused and relevant contexts for each LLM interaction elegantly.
Few-shot learning is a must-have technique in prompt engineering. Providing the LLM with relevant examples significantly improves its understanding of the task.
Notice that in both approaches we discuss below, we reuse our Pydantic models for the few-shots — this trick ensures consistency between the examples and our actual task! Unfortunately, I learned it the hard way.
6.1.1 Examples Few-Shot Learning
Take a look at the few_shots dictionary in section 5. In this approach:
Examples are added to the messages list as separate user and assistant messages, followed by the actual user input.
messages.extend([
message for example in few_shots for message in [
{"role": "user", "content": to_yaml(example["input"])},
{"role": "assistant", "content": to_yaml(example["output"])}
]
])
# then we can add the user prompt
messages.append({"role": "user", "content": to_yaml(input_data)})
By placing the examples as messages, we align with the training methodology of instruction models. It allows the model to see multiple “example interactions” before processing the user input — helping it understand the expected input-output pattern.
As your application grows, you can add more few-shots to cover more use-cases. For even more advanced applications, consider implementing dynamic few-shot selection, where the most relevant examples are chosen based on the current input.
6.1.2 Task-Specific Few-Shot Learning
This method uses examples directly related to the current task within the prompt itself. For instance, this prompt template is used for generating additional unique selling points:
Generate {{ num_points }} more unique selling points for our {{ brand }} {{ product_desc }}, following this style:
{% for point in existing_points %}
- {{ point }}
{% endfor %}
This provides targeted guidance for specific content generation tasks by including the examples directly in the prompt rather than as separate messages.
7. KISS — Keep It Simple, Stupid
While fancy prompt engineering techniques like “Tree of Thoughts” or “Graph of Thoughts” are intriguing, especially for research, I found them quite impractical and often overkill for production. For real applications, focus on designing a proper LLM architecture(aka workflow engineering).
This extends to the use of agents in your LLM applications. It's crucial to understand the distinction between standard agents and autonomous agents:
While autonomous agents offer flexibility and quicker development, they can also introduce unpredictability and debugging challenges. Use autonomous agents carefully — only when the benefits clearly outweigh the potential loss of control and increased complexity.

(Generated with Midjourney)
8. Iterate, Iterate, Iterate!
Continuous experimentation is vital to improving your LLM-native applications. Don't be intimidated by the idea of experiments — they can be as small as tweaking a prompt. As outlined in "Building LLM Apps: A Clear Step-by-Step Guide," it's crucial to establish a baseline and track improvements against it.
Another great trick is to try your prompts on a weaker model than the one you aim to use in production(such as open-source 8B models) — an “okay” performing prompt on a smaller model will perform much better on a larger model.
Conclusion
These eight tips provide a solid foundation for effective prompt engineering in LLM-native applications. By applying these tips in your prompts, you'll be able to create more reliable, efficient, and scalable LLM-native applications.
Remember, the goal isn't to create the most complex system but to build something that works in the real world. Keep experimenting, learning, and building — the possibilities are endless.
If you find this article helpful, please give it a few claps 👏 on Medium and share it with your fellow AI enthusiasts. Your support means the world to me! 🌍
Let's keep the conversation going — feel free to reach out via email or connect on LinkedIn 🤝
Special thanks to Liron Izhaki Allerhand and Yam Peleg; this article is based on insights from our conversations.

8 Practical Prompt Engineering Tips for Better LLM Apps was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Over the past two years, I’ve been helping organizations build and deploy dozens of LLM applications for real-world use cases. This experience gave me valuable insights into effective prompting techniques.
This article, informed by the LLM Triangle Principles, presents eight practical tips for prompt engineering to level up your LLM prompting game.
“LLM-Native apps are 10% sophisticated model, and 90% experimenting data-driven engineering work.”
(Generated with Midjourney)
Throughout this article, we'll use the “Landing Page Generator” example to demonstrate how each tip can be applied to enhance a real-world LLM application.
You can also check out the full script of Landing Page Generator example, for a complete lookout.
Note: This is a simplified, non-production example created to illustrate these tips. The code and prompts are intentionally basic to highlight the concepts discussed.
1. Define Clear Cognitive Process BoundariesNote: This is a simplified, non-production example created to illustrate these tips. The code and prompts are intentionally basic to highlight the concepts discussed.
Start by defining the objective for each agent or prompt. Stick to one cognitive process type per agent, such as: conceptualizing a landing page, selecting components, or generating content for specific sections.
Having clear boundaries maintains focus and clarity in your LLM interactions, aligning with the Engineering Techniques apex of the LLM Triangle Principle.
“Each step in our flow is a standalone process that must occur to achieve our task.”
For example, avoid combining different cognitive processes in the same prompt, which might yield suboptimal results. Instead, break these into separate, focused agents:
def generate_landing_page_concept(input_data: LandingPageInput) -> LandingPageConcept:
"""
Generate a landing page concept based on the input data.
This function focuses on the creative process of conceptualizing the landing page.
"""
pass
def select_landing_page_components(concept: LandingPageConcept) -> List[LandingPageComponent]:
"""
Select appropriate components for the landing page based on the concept.
This function is responsible only for choosing components,
not for generating their content or layout.
"""
pass
def generate_component_content(component: LandingPageComponent, concept: LandingPageConcept) -> ComponentContent:
"""
Generate content for a specific landing page component.
This function focuses on creating appropriate content based on the component type and overall concept.
"""
pass
By defining clear boundaries for each agent, we can ensure that each step in our workflow is tailored to a specific mental task. This will improve the quality of outputs and make it easier to debug and refine.
2. Specify Input/Output Clearly
Define clear input and output structures to reflect the objectives and create explicit data models. This practice touches on the LLM Triangle Principles' Engineering Techniques and Contextual Data apexes.
class LandingPageInput(BaseModel):
brand: str
product_desc: str
campaign_desc: str
cta_message: str
target_audience: str
unique_selling_points: List[str]
class LandingPageConcept(BaseModel):
campaign_desc_reflection: str
campaign_motivation: str
campaign_narrative: str
campaign_title_types: List[str]
campaign_title: str
tone_and_style: List[str]
These Pydantic models define the structure of our input and output data and define clear boundaries and expectations for the agent.
3. Implement Guardrails
Place validations to ensure the quality and moderation of the LLM outputs. Pydantic is excellent for implementing these guardrails, and we can utilize its native features for that.
class LandingPageConcept(BaseModel):
campaign_narrative: str = Field(..., min_length=50) # native validations
tone_and_style: List[str] = Field(..., min_items=2) # native validations
# ...rest of the fields... #
@field_validator("campaign_narrative")
@classmethod
def validate_campaign_narrative(cls, v):
"""Validate the campaign narrative against the content policy, using another AI model."""
response = client.moderations.create(input=v)
if response.results[0].flagged:
raise ValueError("The provided text violates the content policy.")
return v
In this example, ensuring the quality of our application by defining two types of validators:
- Using Pydanitc’s Field to define simple validations, such as a minimum of 2 tone/style attributes, or a minimum of 50 characters in the narrative
- Using a custom field_validator that ensures the generated narrative is complying with our content moderation policy (using AI)
Structure your LLM workflow to mimic human cognitive processes by breaking down complex tasks into smaller steps that follow a logical sequence. To do that, follow the SOP (Standard Operating Procedure) guiding principle of the LLM Triangle Principles.
“Without an SOP, even the most powerful LLM will fail to deliver consistently high-quality results.”
4.1 Capture hidden implicit cognition jumpsIn our example, we expect the model to return LandingPageConcept as a result. By asking the model to output certain fields, we guide the LLM similar to how a human marketer or designer might approach creating a landing page concept.
class LandingPageConcept(BaseModel):
campaign_desc_reflection: str # Encourages analysis of the campaign description
campaign_motivation: str # Prompts thinking about the 'why' behind the campaign
campaign_narrative: str # Guides creation of a cohesive story for the landing page
campaign_title_types: List[str]# Promotes brainstorming different title approaches
campaign_title: str # The final decision on the title
tone_and_style: List[str] # Defines the overall feel of the landing page
The LandingPageConcept structure encourages the LLM to follow a human-like reasoning process, mirroring the subtle mental leaps (implicit cognition "jumps") that an expert would make instinctively, just as we modeled in our SOP.
4.2 Breaking complex processes into multiple steps/agents
For complex tasks, break the process down into various steps, each handled by a separate LLM call or "agent":
async def generate_landing_page(input_data: LandingPageInput) -> LandingPageOutput:
# Step 1: Conceptualize the campaign
concept = await generate_concept(input_data)
# Step 2: Select appropriate components
selected_components = await select_components(concept)
# Step 3: Generate content for each selected component
component_contents = {
component: await generate_component_content(input_data, concept, component)
for component in selected_components
}
# Step 4: Compose the final HTML
html = await compose_html(concept, component_contents)
return LandingPageOutput(concept, selected_components, component_contents, html)
Illustration of the multi-agent process code. (Image by author)
This multi-agent approach aligns with how humans tackle complex problems — by breaking them into smaller parts.
5. Leverage Structured Data (YAML)
YAML is a popular human-friendly data serialization format. It’s designed to be easily readable by humans while still being easy for machines to parse — which makes it classic for LLM usage.
I found YAML is particularly effective for LLM interactions and yields much better results across different models. It focuses the token processing on valuable content rather than syntax.
YAML is also much more portable across different LLM providers and allows you to maintain a structured output format.
async def generate_component_content(input_data: LandingPageInput, concept: LandingPageConcept,component: LandingPageComponent) -> ComponentContent:
few_shots = {
LandingPageComponent.HERO: {
"input": LandingPageInput(
brand="Mustacher",
product_desc="Luxurious mustache cream for grooming and styling",
# ... rest of the input data ...
),
"concept": LandingPageConcept(
campaign_title="Celebrate Dad's Dash of Distinction",
tone_and_style=["Warm", "Slightly humorous", "Nostalgic"]
# ... rest of the concept ...
),
"output": ComponentContent(
motivation="The hero section captures attention and communicates the core value proposition.",
content={
"headline": "Honor Dad's Distinction",
"subheadline": "The Art of Mustache Care",
"cta_button": "Shop Now"
}
)
},
# Add more component examples as needed
}
sys = "Craft landing page component content. Respond in YAML with motivation and content structure as shown."
messages = [{"role": "system", "content": sys}]
messages.extend([
message for example in few_shots.values() for message in [
{"role": "user", "content": to_yaml({"input": example["input"], "concept": example["concept"], "component": component.value})},
{"role": "assistant", "content": to_yaml(example["output"])}
]
])
messages.append({"role": "user", "content": to_yaml({"input": input_data, "concept": concept, "component": component.value})})
response = await client.chat.completions.create(model="gpt-4o", messages=messages)
raw_content = yaml.safe_load(sanitize_code_block(response.choices[0].message.content))
return ComponentContent(**raw_content)
Notice how we're using few-shot examples to "show, don't tell" the expected YAML format. This approach is more effective than explicit instructions in prompt for the output structure.
6. Craft Your Contextual Data
Carefully consider how to model and present data to the LLM. This tip is central to the Contextual Data apex of the LLM Triangle Principles.
“Even the most powerful model requires relevant and well-structured contextual data to shine.”
Don’t throw away all the data you have on the model. Instead, inform the model with the pieces of information that are relevant to the objective you defined.
async def select_components(concept: LandingPageConcept) -> List[LandingPageComponent]:
sys_template = jinja_env.from_string("""
Your task is to select the most appropriate components for a landing page based on the provided concept.
Choose from the following components:
{% for component in components %}
- {{ component.value }}
{% endfor %}
You MUST respond ONLY in a valid YAML list of selected components.
""")
sys = sys_template.render(components=LandingPageComponent)
prompt = jinja_env.from_string("""
Campaign title: "{{ concept.campaign_title }}"
Campaign narrative: "{{ concept.campaign_narrative }}"
Tone and style attributes: {{ concept.tone_and_style | join(', ') }}
""")
messages = [{"role": "system", "content": sys}] + few_shots + [
{"role": "user", "content": prompt.render(concept=concept)}]
response = await client.chat.completions.create(model="gpt-4", messages=messages)
selected_components = yaml.safe_load(response.choices[0].message.content)
return [LandingPageComponent(component) for component in selected_components]
In this example, we're using Jinja templates to dynamically compose our prompts. This creates focused and relevant contexts for each LLM interaction elegantly.
“Data fuels the engine of LLM-native applications. A strategic design of contextual data unlocks their true potential.”
6.1 Harness the power of few-shot learningFew-shot learning is a must-have technique in prompt engineering. Providing the LLM with relevant examples significantly improves its understanding of the task.
Notice that in both approaches we discuss below, we reuse our Pydantic models for the few-shots — this trick ensures consistency between the examples and our actual task! Unfortunately, I learned it the hard way.
6.1.1 Examples Few-Shot Learning
Take a look at the few_shots dictionary in section 5. In this approach:
Examples are added to the messages list as separate user and assistant messages, followed by the actual user input.
messages.extend([
message for example in few_shots for message in [
{"role": "user", "content": to_yaml(example["input"])},
{"role": "assistant", "content": to_yaml(example["output"])}
]
])
# then we can add the user prompt
messages.append({"role": "user", "content": to_yaml(input_data)})
By placing the examples as messages, we align with the training methodology of instruction models. It allows the model to see multiple “example interactions” before processing the user input — helping it understand the expected input-output pattern.
As your application grows, you can add more few-shots to cover more use-cases. For even more advanced applications, consider implementing dynamic few-shot selection, where the most relevant examples are chosen based on the current input.
6.1.2 Task-Specific Few-Shot Learning
This method uses examples directly related to the current task within the prompt itself. For instance, this prompt template is used for generating additional unique selling points:
Generate {{ num_points }} more unique selling points for our {{ brand }} {{ product_desc }}, following this style:
{% for point in existing_points %}
- {{ point }}
{% endfor %}
This provides targeted guidance for specific content generation tasks by including the examples directly in the prompt rather than as separate messages.
7. KISS — Keep It Simple, Stupid
While fancy prompt engineering techniques like “Tree of Thoughts” or “Graph of Thoughts” are intriguing, especially for research, I found them quite impractical and often overkill for production. For real applications, focus on designing a proper LLM architecture(aka workflow engineering).
This extends to the use of agents in your LLM applications. It's crucial to understand the distinction between standard agents and autonomous agents:
Agents: “Take me from A → B by doing XYZ.”
Autonomous Agents:“Take me from A → B by doing something, I don’t care how.”
While autonomous agents offer flexibility and quicker development, they can also introduce unpredictability and debugging challenges. Use autonomous agents carefully — only when the benefits clearly outweigh the potential loss of control and increased complexity.
(Generated with Midjourney)
8. Iterate, Iterate, Iterate!
Continuous experimentation is vital to improving your LLM-native applications. Don't be intimidated by the idea of experiments — they can be as small as tweaking a prompt. As outlined in "Building LLM Apps: A Clear Step-by-Step Guide," it's crucial to establish a baseline and track improvements against it.
Like everything else in “AI,” LLM-native apps require a research and experimentation mindset.
Another great trick is to try your prompts on a weaker model than the one you aim to use in production(such as open-source 8B models) — an “okay” performing prompt on a smaller model will perform much better on a larger model.
Conclusion
These eight tips provide a solid foundation for effective prompt engineering in LLM-native applications. By applying these tips in your prompts, you'll be able to create more reliable, efficient, and scalable LLM-native applications.
Remember, the goal isn't to create the most complex system but to build something that works in the real world. Keep experimenting, learning, and building — the possibilities are endless.
If you find this article helpful, please give it a few claps 👏 on Medium and share it with your fellow AI enthusiasts. Your support means the world to me! 🌍
Let's keep the conversation going — feel free to reach out via email or connect on LinkedIn 🤝
Special thanks to Liron Izhaki Allerhand and Yam Peleg; this article is based on insights from our conversations.
8 Practical Prompt Engineering Tips for Better LLM Apps was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.