A comprehensive guide on how to speed up the training of your models with Distributed Data Parallel (DDP)

Image by Author
Introduction
Hi everyone! I am Francois, Research Scientist at Meta. Welcome to this new tutorial part of the series Awesome AI Tutorials.
In this tutorial we are going to demistify a well known technique called DDP to train models on several GPUs at the same time.
During my days at engineering school, I recall leveraging Google Colab’s GPUs for training. However, in the corporate realm, the landscape is different. If you’re part of an organization that’s heavily invested in AI — particularly if you’re within a tech giant — you likely have a wealth of GPU clusters at your disposal.
his session aims to equip you with the knowledge to harness the power of multiple GPUs, enabling swift and efficient training. And guess what? It’s simpler than you might think! Before we proceed, I recommend having a good grasp of PyTorch, including its core components like Datasets, DataLoaders, Optimizers, CUDA, and the training loop.
Initially, I viewed DDP as a complex, nearly unattainable tool, thinking it would require a large team to set up the necessary infrastructure. However, I assure you, DDP is not only intuitive but also concise, requiring just a handful of code lines to implement. Let’s embark on this enlightening journey together!
A high level intuition of DDP
Distributed Data Parallel (DDP) is a straightforward concept once we break it down. Imagine you have a cluster with 4 GPUs at your disposal. With DDP, the same model is loaded onto each GPU, optimizer included. The primary differentiation arises in how we distribute the data.
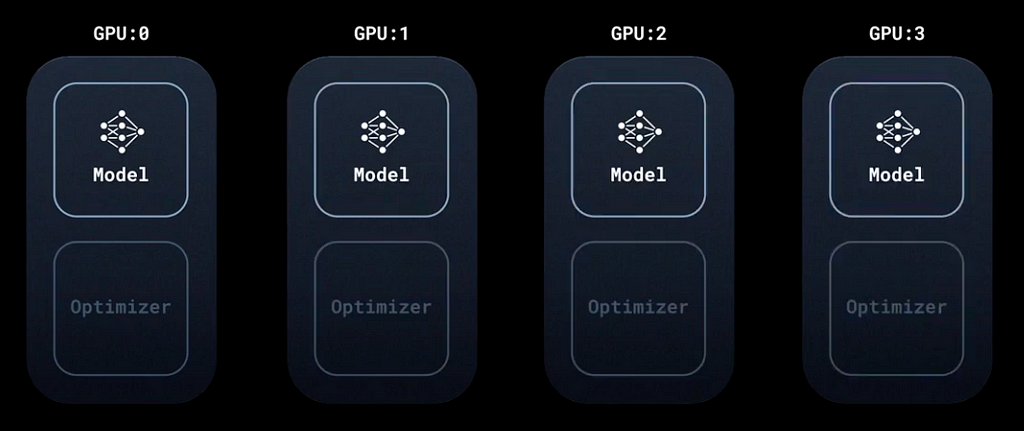
DDP, Image taken from PyTorch tutorial
If you’re acquainted with deep learning, you’ll recall the DataLoader, a tool that segments your dataset into distinct batches. The norm is to fragment the entire dataset into these batches, updating the model post each batch’s computation.
Zooming in further, DDP refines this process by dividing each batch into what we can term as “sub-batches.” Essentially, every model replica processes a segment of the primary batch, resulting in a distinct gradient computation for each GPU.
In DDP we split this batch into sub-batches through a tool called a DistributedSampler, as illustrated on the following drawing:

DDP, Image taken from PyTorch tutorial
Upon the distribution of each sub-batch to individual GPUs, every GPU computes its unique gradient.
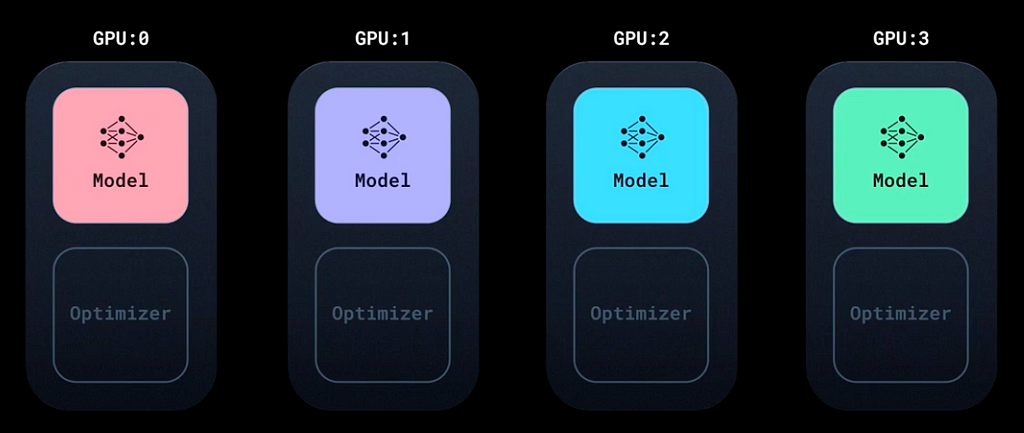
DDP, Image taken from PyTorch tutorial
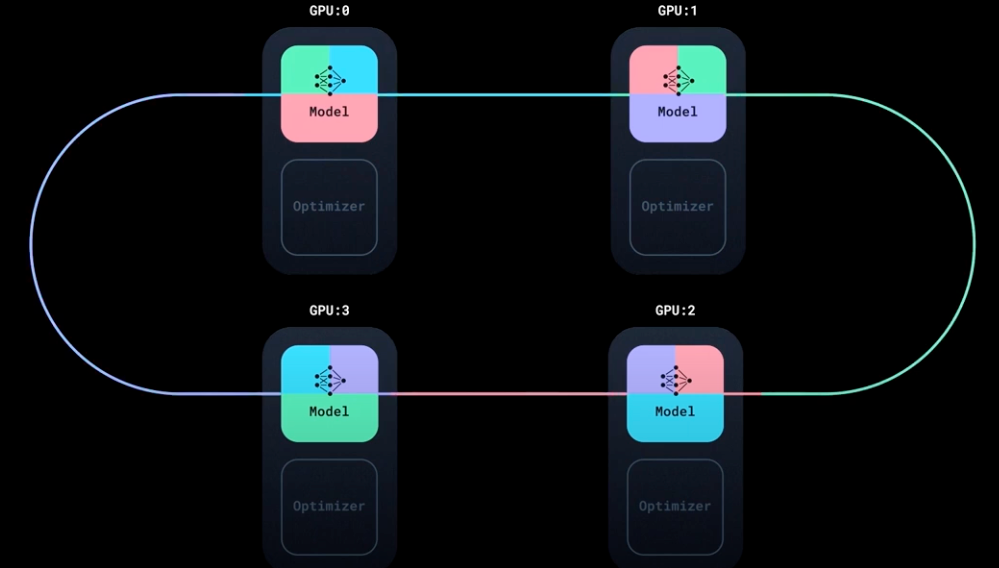
DDP, Image taken from PyTorch tutorial
Glossary on terms, nodes and ranks
Before diving into the code, it’s crucial to understand the vocabulary we’ll be using frequently. Let’s demystify these terms:
To put things into perspective, if you’re working with just one machine, things are more straightforward as the local rank equates to the global rank.
To clarify this with an image:

Local rank, image from tutorial

Local rank, image from tutorial
Understanding DDP Limitations:
Distributed Data Parallel (DDP) has been transformative in many deep learning workflows, but it’s essential to understand its boundaries.
The crux of DDP’s limitation lies in its memory consumption. With DDP, each GPU loads a replica of the model, the optimizer, and its respective batch of data. GPU memories typically range from a few GB to 80GB for the high end GPUs.
For smaller models, this isn’t an issue. However, when venturing into the realm of Large Language Models (LLMs) or architectures akin to GPT, the confines of a single GPU’s memory might be inadequate.
In Computer Vision, while there’s a plethora of lightweight models, challenges arise when increasing batch sizes, especially in scenarios involving 3D imagery or Object Detection tasks.
Enter Fully Sharded Data Parallel (FSDP). This method extends the benefits of DDP by not only distributing data but also dispersing the model and optimizer states across GPU memories. While this sounds advantageous, FSDP increases inter-GPU communication, potentially slowing down training.
In Summary:
If you go on PyTorch’s website, there are actually options: DP and DDP. But I only mention this so you don’t get lost or confused: Just use DDP, it’s faster and not limited to a single node.

Comparison from Pytorch tutorial
Code Walkthrough:
Implementing distributed deep learning is simpler than you might think. The beauty lies in the fact that you won’t be bogged down with manual GPU configurations or the intricacies of gradient distribution.
You will find all the template and script on:
GitHub - FrancoisPorcher/awesome-ai-tutorials: The best collection of AI tutorials to make you a boss of Data Science!
Here’s a breakdown of the steps we’ll be taking:
First let’s define a vanilla code that loads a dataset, create a model and train it end to end on a single GPU. This will be our starting point:
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
class WineDataset(Dataset):
def __init__(self, data, targets):
self.data = data
self.targets = targets
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return torch.tensor(self.data[idx], dtype=torch.float), torch.tensor(self.targets[idx], dtype=torch.long)
class SimpleNN(torch.nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = torch.nn.Linear(13, 64)
self.fc2 = torch.nn.Linear(64, 3)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
class Trainer():
def __init__(self, model, train_data, optimizer, gpu_id, save_every):
self.model = model
self.train_data = train_data
self.optimizer = optimizer
self.gpu_id = gpu_id
self.save_every = save_every
self.losses = []
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
return loss.item()
def _run_epoch(self, epoch):
total_loss = 0.0
num_batches = len(self.train_data)
for source, targets in self.train_data:
source = source.to(self.gpu_id)
targets = targets.to(self.gpu_id)
loss = self._run_batch(source, targets)
total_loss += loss
avg_loss = total_loss / num_batches
self.losses.append(avg_loss)
print(f"Epoch {epoch}, Loss: {avg_loss:.4f}")
def _save_checkpoint(self, epoch):
checkpoint = self.model.state_dict()
PATH = f"model_{epoch}.pt"
torch.save(checkpoint, PATH)
print(f"Epoch {epoch} | Model saved to {PATH}")
def train(self, max_epochs):
self.model.train()
for epoch in range(max_epochs):
self._run_epoch(epoch)
if epoch % self.save_every == 0:
self._save_checkpoint(epoch)
def load_train_objs():
wine_data = load_wine()
X = wine_data.data
y = wine_data.target
# Normalize and split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
train_set = WineDataset(X_train, y_train)
test_set = WineDataset(X_test, y_test)
print("Sample from dataset:")
sample_data, sample_target = train_set[0]
print(f"Data: {sample_data}")
print(f"Target: {sample_target}")
model = SimpleNN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
return train_set, model, optimizer
def prepare_dataloader(dataset, batch_size):
return DataLoader(dataset, batch_size=batch_size, pin_memory=True, shuffle=True)
def main(device, total_epochs, save_every, batch_size):
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size)
trainer = Trainer(model, train_data, optimizer, device, save_every)
trainer.train(total_epochs)
main(device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu"), total_epochs=100, save_every=50, batch_size=32)
Training on several GPUs, 1 Node
Now we are going to use all the GPUs in a single node with the following steps:
For the libraries, we need this:
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
Then we need to setup each process. For example if we have 8 GPUs on 1 Node, we will call the following functions 8 times, one for each GPU and with the right local_rank:
def ddp_setup(rank, world_size):
"""
Set up the distributed environment.
Args:
rank: The rank of the current process. Unique identifier for each process in the distributed training.
world_size: Total number of processes participating in the distributed training.
"""
# Address of the main node. Since we are doing single-node training, it's set to localhost.
os.environ["MASTER_ADDR"] = "localhost"
# Port on which the master node is expected to listen for communications from workers.
os.environ["MASTER_PORT"] = "12355"
# Initialize the process group.
# 'backend' specifies the communication backend to be used, "nccl" is optimized for GPU training.
init_process_group(backend="nccl", rank=rank, world_size=world_size)
# Set the current CUDA device to the specified device (identified by rank).
# This ensures that each process uses a different GPU in a multi-GPU setup.
torch.cuda.set_device(rank)
A few explanations on the function:
Then we need to slightly change the Trainer class. We are simply going to wrap the model with the DDP function:
class Trainer():
def __init__(self, model, train_data, optimizer, gpu_id, save_every):
self.model = model.to(gpu_id)
self.train_data = train_data
self.optimizer = optimizer
self.gpu_id = gpu_id
self.save_every = save_every
self.losses = []
# This changes
self.model = DDP(self.model, device_ids=[gpu_id])
The rest of the Trainer class is the same, amazing!
Now we have to change the dataloader, because remember, we have to split the batch on each GPU:
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True,
shuffle=False,
sampler=DistributedSampler(dataset)
)
Now we can modify the main function, that will be called for each process (so 8 times in our case):
def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):
"""
Main training function for distributed data parallel (DDP) setup.
Args:
rank (int): The rank of the current process (0 <= rank < world_size). Each process is assigned a unique rank.
world_size (int): Total number of processes involved in the distributed training.
save_every (int): Frequency of model checkpoint saving, in terms of epochs.
total_epochs (int): Total number of epochs for training.
batch_size (int): Number of samples processed in one iteration (forward and backward pass).
"""
# Set up the distributed environment, including setting the master address, port, and backend.
ddp_setup(rank, world_size)
# Load the necessary training objects - dataset, model, and optimizer.
dataset, model, optimizer = load_train_objs()
# Prepare the data loader for distributed training. It partitions the dataset across the processes and handles shuffling.
train_data = prepare_dataloader(dataset, batch_size)
# Initialize the trainer instance with the loaded model, data, and other configurations.
trainer = Trainer(model, train_data, optimizer, rank, save_every)
# Train the model for the specified number of epochs.
trainer.train(total_epochs)
# Cleanup the distributed environment after training is complete.
destroy_process_group()
And finally, when executing the script, we will have to launch the 8 processes. This is done with the mp.spawn() function:
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')
parser.add_argument('save_every', type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
args = parser.parse_args()
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)
Ultimate Step: Training on several nodes
If you have made it so far congratulations! The Ultimate step is be able to recruit all the GPUs available on different nodes. But if you understood what we have done so far, this is very easy.
The key distinction when scaling across multiple nodes is the shift from local_rank to global_rank. This is imperative because every process requires a unique identifier. For instance, if you're working with two nodes, each with 8 GPUs, both processes 0 and 9 would have a local_rank of 0.
The global_rank is given by the very intuitive formula:
global_rank = node_rank * world_size_per_node + local_rank
So first let’w modify the ddp_setup function:
def ddp_setup(local_rank, world_size_per_node, node_rank):
os.environ["MASTER_ADDR"] = "MASTER_NODE_IP" # <-- Replace with your master node IP
os.environ["MASTER_PORT"] = "12355"
global_rank = node_rank * world_size_per_node + local_rank
init_process_group(backend="nccl", rank=global_rank, world_size=world_size_per_node*torch.cuda.device_count())
torch.cuda.set_device(local_rank)
And we have to adjust the main function which now takes the wold_size_per_node in argument:
def main(local_rank: int, world_size_per_node: int, save_every: int, total_epochs: int, batch_size: int, node_rank: int):
ddp_setup(local_rank, world_size_per_node, node_rank)
# ... (rest of the main function)
And finally we adjust the mp.spawn() function with the world_size_per_node as well:
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')
parser.add_argument('save_every', type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
parser.add_argument('--node_rank', default=0, type=int, help='The rank of the node in multi-node training')
args = parser.parse_args()
world_size_per_node = torch.cuda.device_count()
mp.spawn(main, args=(world_size_per_node, args.save_every, args.total_epochs, args.batch_size, args.node_rank), nprocs=world_size_per_node)
Using a cluster (SLURM)
You are now ready to send the training to the cluster. I’ts very simple you just have to call the number of nodes you want.
Here is a template for the SLURM script:
#!/bin/bash
#SBATCH --job-name=DDPTraining # Name of the job
#SBATCH --nodes=$1 # Number of nodes specified by the user
#SBATCH --ntasks-per-node=1 # Ensure only one task runs per node
#SBATCH --cpus-per-task=1 # Number of CPU cores per task
#SBATCH --gres=gpu:1 # Number of GPUs per node
#SBATCH --time=01:00:00 # Time limit hrs:min:sec (1 hour in this example)
#SBATCH --mem=4GB # Memory limit per GPU
#SBATCH --output=training_%j.log # Output and error log name (%j expands to jobId)
#SBATCH --partition=gpu # Specify the partition or queue
srun python3 your_python_script.py --total_epochs 10 --save_every 2 --batch_size 32 --node_rank $SLURM_NODEID
And now you can launch training from the terminal with the command
sbatch train_net.sh 2 # for using 2 nodes
Congratulations, you’ve made it!
Thanks for reading! Before you go:
For more awesome tutorials, check my compilation of AI tutorials on Github
GitHub - FrancoisPorcher/awesome-ai-tutorials: The best collection of AI tutorials to make you a boss of Data Science!
You should get my articles in your inbox. Subscribe here.
If you want to have access to premium articles on Medium, you only need a membership for $5 a month. If you sign up with my link, you support me with a part of your fee without additional costs.

A comprehensive guide of Distributed Data Parallel (DDP) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Image by Author
Introduction
Hi everyone! I am Francois, Research Scientist at Meta. Welcome to this new tutorial part of the series Awesome AI Tutorials.
In this tutorial we are going to demistify a well known technique called DDP to train models on several GPUs at the same time.
During my days at engineering school, I recall leveraging Google Colab’s GPUs for training. However, in the corporate realm, the landscape is different. If you’re part of an organization that’s heavily invested in AI — particularly if you’re within a tech giant — you likely have a wealth of GPU clusters at your disposal.
his session aims to equip you with the knowledge to harness the power of multiple GPUs, enabling swift and efficient training. And guess what? It’s simpler than you might think! Before we proceed, I recommend having a good grasp of PyTorch, including its core components like Datasets, DataLoaders, Optimizers, CUDA, and the training loop.
Initially, I viewed DDP as a complex, nearly unattainable tool, thinking it would require a large team to set up the necessary infrastructure. However, I assure you, DDP is not only intuitive but also concise, requiring just a handful of code lines to implement. Let’s embark on this enlightening journey together!
A high level intuition of DDP
Distributed Data Parallel (DDP) is a straightforward concept once we break it down. Imagine you have a cluster with 4 GPUs at your disposal. With DDP, the same model is loaded onto each GPU, optimizer included. The primary differentiation arises in how we distribute the data.
DDP, Image taken from PyTorch tutorial
If you’re acquainted with deep learning, you’ll recall the DataLoader, a tool that segments your dataset into distinct batches. The norm is to fragment the entire dataset into these batches, updating the model post each batch’s computation.
Zooming in further, DDP refines this process by dividing each batch into what we can term as “sub-batches.” Essentially, every model replica processes a segment of the primary batch, resulting in a distinct gradient computation for each GPU.
In DDP we split this batch into sub-batches through a tool called a DistributedSampler, as illustrated on the following drawing:
DDP, Image taken from PyTorch tutorial
Upon the distribution of each sub-batch to individual GPUs, every GPU computes its unique gradient.
DDP, Image taken from PyTorch tutorial
- Now comes the DDP magic. Before updating the model parameters, the gradients calculated on each GPU need to be aggregated so that every GPU has the average gradient computed over the entire batch of data.
- This is done by taking the gradients from all GPUs and averaging them. For instance, if you have 4 GPUs, the average gradient for a particular model parameter is the sum of the gradients for that parameter on each of the 4 GPUs divided by 4.
- DDP uses the NCCL or Gloo backend (NCCL is optimized for NVIDIA GPUs, Gloo is more general) to efficiently communicate and average gradients across GPUs.
DDP, Image taken from PyTorch tutorial
Glossary on terms, nodes and ranks
Before diving into the code, it’s crucial to understand the vocabulary we’ll be using frequently. Let’s demystify these terms:
- Node: Think of a node as a powerful machine equipped with multiple GPUs. When we speak of a cluster, it’s not just a bunch of GPUs thrown together. Instead, they’re organized into groups or “nodes.” For instance, a node might house 8 GPUs.
- Master Node: In a multi-node environment, one node typically takes charge. This “master node” handles tasks like synchronization, initiating model copies, overseeing model loading, and managing log entries. Without a master node, each GPU would independently generate logs, leading to chaos.
- Local Rank: The term “rank” can be likened to an ID or a position. The local rank refers to the position or ID of a GPU within its specific node (or machine). It’s “local” because it’s confined to that particular machine.
- Global Rank: Taking a broader perspective, the global rank identifies a GPU across all available nodes. It’s a unique identifier irrespective of the machine.
- World Size: At its core, this is a count of all GPUs available to you across all nodes. Simply, it’s the product of the number of nodes and the number of GPUs in each node.
To put things into perspective, if you’re working with just one machine, things are more straightforward as the local rank equates to the global rank.
To clarify this with an image:
Local rank, image from tutorial
Local rank, image from tutorial
Understanding DDP Limitations:
Distributed Data Parallel (DDP) has been transformative in many deep learning workflows, but it’s essential to understand its boundaries.
The crux of DDP’s limitation lies in its memory consumption. With DDP, each GPU loads a replica of the model, the optimizer, and its respective batch of data. GPU memories typically range from a few GB to 80GB for the high end GPUs.
For smaller models, this isn’t an issue. However, when venturing into the realm of Large Language Models (LLMs) or architectures akin to GPT, the confines of a single GPU’s memory might be inadequate.
In Computer Vision, while there’s a plethora of lightweight models, challenges arise when increasing batch sizes, especially in scenarios involving 3D imagery or Object Detection tasks.
Enter Fully Sharded Data Parallel (FSDP). This method extends the benefits of DDP by not only distributing data but also dispersing the model and optimizer states across GPU memories. While this sounds advantageous, FSDP increases inter-GPU communication, potentially slowing down training.
In Summary:
- If your model and its corresponding batch comfortably fit within a GPU’s memory, DDP is your best bet owing to its speed.
- For mammoth-sized models demanding more memory, FSDP is a more fitting choice. However, bear in mind its trade-off: you’re sacrificing speed for memory.
If you go on PyTorch’s website, there are actually options: DP and DDP. But I only mention this so you don’t get lost or confused: Just use DDP, it’s faster and not limited to a single node.
Comparison from Pytorch tutorial
Code Walkthrough:
Implementing distributed deep learning is simpler than you might think. The beauty lies in the fact that you won’t be bogged down with manual GPU configurations or the intricacies of gradient distribution.
You will find all the template and script on:
GitHub - FrancoisPorcher/awesome-ai-tutorials: The best collection of AI tutorials to make you a boss of Data Science!
Here’s a breakdown of the steps we’ll be taking:
- Process Initialization: This involves designating the master node, specifying the port, and setting up the world_size.
- Distributed DataLoader Setup: Crucial to this step is the partitioning of each batch across the available GPUs. We’ll ensure that the data is evenly spread without any overlap.
- Model Training/Testing: In essence, this step remains largely unchanged from the single GPU process.
First let’s define a vanilla code that loads a dataset, create a model and train it end to end on a single GPU. This will be our starting point:
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
class WineDataset(Dataset):
def __init__(self, data, targets):
self.data = data
self.targets = targets
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return torch.tensor(self.data[idx], dtype=torch.float), torch.tensor(self.targets[idx], dtype=torch.long)
class SimpleNN(torch.nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = torch.nn.Linear(13, 64)
self.fc2 = torch.nn.Linear(64, 3)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
class Trainer():
def __init__(self, model, train_data, optimizer, gpu_id, save_every):
self.model = model
self.train_data = train_data
self.optimizer = optimizer
self.gpu_id = gpu_id
self.save_every = save_every
self.losses = []
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
return loss.item()
def _run_epoch(self, epoch):
total_loss = 0.0
num_batches = len(self.train_data)
for source, targets in self.train_data:
source = source.to(self.gpu_id)
targets = targets.to(self.gpu_id)
loss = self._run_batch(source, targets)
total_loss += loss
avg_loss = total_loss / num_batches
self.losses.append(avg_loss)
print(f"Epoch {epoch}, Loss: {avg_loss:.4f}")
def _save_checkpoint(self, epoch):
checkpoint = self.model.state_dict()
PATH = f"model_{epoch}.pt"
torch.save(checkpoint, PATH)
print(f"Epoch {epoch} | Model saved to {PATH}")
def train(self, max_epochs):
self.model.train()
for epoch in range(max_epochs):
self._run_epoch(epoch)
if epoch % self.save_every == 0:
self._save_checkpoint(epoch)
def load_train_objs():
wine_data = load_wine()
X = wine_data.data
y = wine_data.target
# Normalize and split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler().fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
train_set = WineDataset(X_train, y_train)
test_set = WineDataset(X_test, y_test)
print("Sample from dataset:")
sample_data, sample_target = train_set[0]
print(f"Data: {sample_data}")
print(f"Target: {sample_target}")
model = SimpleNN()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
return train_set, model, optimizer
def prepare_dataloader(dataset, batch_size):
return DataLoader(dataset, batch_size=batch_size, pin_memory=True, shuffle=True)
def main(device, total_epochs, save_every, batch_size):
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size)
trainer = Trainer(model, train_data, optimizer, device, save_every)
trainer.train(total_epochs)
main(device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu"), total_epochs=100, save_every=50, batch_size=32)
Training on several GPUs, 1 Node
Now we are going to use all the GPUs in a single node with the following steps:
- Import Necessary Libraries for distributed training.
- Initialize the Distributed Environment: (especially the MASTER_ADDR and MASTER_PORT
- Wrap Model with DDP using the DistributedDataParallel wrapper.
- Use Distributed Sampler to ensure that the dataset is divided across the GPUs in a distributed manner.
- Adjust the Main Function to spawn multiple processes for multi-GPU training.
For the libraries, we need this:
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
Then we need to setup each process. For example if we have 8 GPUs on 1 Node, we will call the following functions 8 times, one for each GPU and with the right local_rank:
def ddp_setup(rank, world_size):
"""
Set up the distributed environment.
Args:
rank: The rank of the current process. Unique identifier for each process in the distributed training.
world_size: Total number of processes participating in the distributed training.
"""
# Address of the main node. Since we are doing single-node training, it's set to localhost.
os.environ["MASTER_ADDR"] = "localhost"
# Port on which the master node is expected to listen for communications from workers.
os.environ["MASTER_PORT"] = "12355"
# Initialize the process group.
# 'backend' specifies the communication backend to be used, "nccl" is optimized for GPU training.
init_process_group(backend="nccl", rank=rank, world_size=world_size)
# Set the current CUDA device to the specified device (identified by rank).
# This ensures that each process uses a different GPU in a multi-GPU setup.
torch.cuda.set_device(rank)
A few explanations on the function:
- MASTER_ADDR is the hostname of the machine on whith the master (or the rank 0 process) is running. Here it’s localhost
- MASTER_PORT: Specifies the port on which the master is listening for connections from workers or other processes. 12355 is arbitrary. You can choose any unused port number as long as it’s not being used by another service on your system and is allowed by your firewall rules.
- torch.cuda.set_device(rank): This ensure that each process uses its corresponding GPU
Then we need to slightly change the Trainer class. We are simply going to wrap the model with the DDP function:
class Trainer():
def __init__(self, model, train_data, optimizer, gpu_id, save_every):
self.model = model.to(gpu_id)
self.train_data = train_data
self.optimizer = optimizer
self.gpu_id = gpu_id
self.save_every = save_every
self.losses = []
# This changes
self.model = DDP(self.model, device_ids=[gpu_id])
The rest of the Trainer class is the same, amazing!
Now we have to change the dataloader, because remember, we have to split the batch on each GPU:
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True,
shuffle=False,
sampler=DistributedSampler(dataset)
)
Now we can modify the main function, that will be called for each process (so 8 times in our case):
def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):
"""
Main training function for distributed data parallel (DDP) setup.
Args:
rank (int): The rank of the current process (0 <= rank < world_size). Each process is assigned a unique rank.
world_size (int): Total number of processes involved in the distributed training.
save_every (int): Frequency of model checkpoint saving, in terms of epochs.
total_epochs (int): Total number of epochs for training.
batch_size (int): Number of samples processed in one iteration (forward and backward pass).
"""
# Set up the distributed environment, including setting the master address, port, and backend.
ddp_setup(rank, world_size)
# Load the necessary training objects - dataset, model, and optimizer.
dataset, model, optimizer = load_train_objs()
# Prepare the data loader for distributed training. It partitions the dataset across the processes and handles shuffling.
train_data = prepare_dataloader(dataset, batch_size)
# Initialize the trainer instance with the loaded model, data, and other configurations.
trainer = Trainer(model, train_data, optimizer, rank, save_every)
# Train the model for the specified number of epochs.
trainer.train(total_epochs)
# Cleanup the distributed environment after training is complete.
destroy_process_group()
And finally, when executing the script, we will have to launch the 8 processes. This is done with the mp.spawn() function:
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')
parser.add_argument('save_every', type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
args = parser.parse_args()
world_size = torch.cuda.device_count()
mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)
Ultimate Step: Training on several nodes
If you have made it so far congratulations! The Ultimate step is be able to recruit all the GPUs available on different nodes. But if you understood what we have done so far, this is very easy.
The key distinction when scaling across multiple nodes is the shift from local_rank to global_rank. This is imperative because every process requires a unique identifier. For instance, if you're working with two nodes, each with 8 GPUs, both processes 0 and 9 would have a local_rank of 0.
The global_rank is given by the very intuitive formula:
global_rank = node_rank * world_size_per_node + local_rank
So first let’w modify the ddp_setup function:
def ddp_setup(local_rank, world_size_per_node, node_rank):
os.environ["MASTER_ADDR"] = "MASTER_NODE_IP" # <-- Replace with your master node IP
os.environ["MASTER_PORT"] = "12355"
global_rank = node_rank * world_size_per_node + local_rank
init_process_group(backend="nccl", rank=global_rank, world_size=world_size_per_node*torch.cuda.device_count())
torch.cuda.set_device(local_rank)
And we have to adjust the main function which now takes the wold_size_per_node in argument:
def main(local_rank: int, world_size_per_node: int, save_every: int, total_epochs: int, batch_size: int, node_rank: int):
ddp_setup(local_rank, world_size_per_node, node_rank)
# ... (rest of the main function)
And finally we adjust the mp.spawn() function with the world_size_per_node as well:
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')
parser.add_argument('save_every', type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
parser.add_argument('--node_rank', default=0, type=int, help='The rank of the node in multi-node training')
args = parser.parse_args()
world_size_per_node = torch.cuda.device_count()
mp.spawn(main, args=(world_size_per_node, args.save_every, args.total_epochs, args.batch_size, args.node_rank), nprocs=world_size_per_node)
Using a cluster (SLURM)
You are now ready to send the training to the cluster. I’ts very simple you just have to call the number of nodes you want.
Here is a template for the SLURM script:
#!/bin/bash
#SBATCH --job-name=DDPTraining # Name of the job
#SBATCH --nodes=$1 # Number of nodes specified by the user
#SBATCH --ntasks-per-node=1 # Ensure only one task runs per node
#SBATCH --cpus-per-task=1 # Number of CPU cores per task
#SBATCH --gres=gpu:1 # Number of GPUs per node
#SBATCH --time=01:00:00 # Time limit hrs:min:sec (1 hour in this example)
#SBATCH --mem=4GB # Memory limit per GPU
#SBATCH --output=training_%j.log # Output and error log name (%j expands to jobId)
#SBATCH --partition=gpu # Specify the partition or queue
srun python3 your_python_script.py --total_epochs 10 --save_every 2 --batch_size 32 --node_rank $SLURM_NODEID
And now you can launch training from the terminal with the command
sbatch train_net.sh 2 # for using 2 nodes
Congratulations, you’ve made it!
Thanks for reading! Before you go:
For more awesome tutorials, check my compilation of AI tutorials on Github
GitHub - FrancoisPorcher/awesome-ai-tutorials: The best collection of AI tutorials to make you a boss of Data Science!
You should get my articles in your inbox. Subscribe here.
If you want to have access to premium articles on Medium, you only need a membership for $5 a month. If you sign up with my link, you support me with a part of your fee without additional costs.
If you found this article insightful and beneficial, please consider following me and leaving a clap for more in-depth content! Your support helps me continue producing content that aids our collective understanding.
ReferencesA comprehensive guide of Distributed Data Parallel (DDP) was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.