DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models
Traditional RAG vs. dynamic RAG
In this article, I explore the fundamental concepts explained in the research paper titled “DRAGIN : Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models” by Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. This paper can be accessed here.
Introduction — Lets look at a short story!

Image taken from Unsplash
Large Language models have changed the way we all access information. We are at that point where the way we search has forever changed. Now, instead of finding multiple links and processing the information to answer our questions, we can directly ask the LLM!
However, there are still a number of issues :
To overcome the above issues, Retrieval Augmented Generation (RAG) emerged as a promising solution. The way it works, is by accessing and incorporating the relevant external information needed for the LLM to generate accurate responses.
However with traditional RAG methods, they rely on single-round retrieval, which would mean retrieving external information once, at the start of the information generation. This works well for straightforward tasks, however our needs and requirements from LLMs are getting more complex, multi-step and requiring longer responses.
In these cases, a single-round of retrieval will not work well and mutiple rounds of retrieval need to be conducted. Now when, we talk about retrieving information more than once, the two next questions are :
When to retrieve and What to retrieve? To solve these, a number of RAG methods have been devised :
Fixed Retrieval Methods :
IRCoT (Fixed Sentence RAG) [1] : Retrieval is conducted for each generated query and the latest sentence is used as a query.
RETRO [2] and IC-RALM [3] (Fixed Length RAG) : A sliding window is defined and the retrieval module is triggered every n tokens.
FLARE [4] (Low Confidence RAG) : Retrieval is conducted dynamically, when the LLM’s confidence (the generation probability) on the next token is lower than certain thresholds. So FLARE, is triggering retrieval based on uncertainty.
For determining what to retrieve, the LLMs often restrict themselves to queries based on the last few generated tokens or sentences. These methods of query formulation for retrieval may not work, when the tasks get more complex and the LLM’s information needs span over the entire context!
Finally, moving on to the star of the show : DRAGIN!
DRAGIN (Dynamic Retrieval Augmented Generation based on Information Needs) :
This method is specifically designed to make decisions about when and what to retrieve to cater to the LLM’s information needs. So, it optimizes the process of information retrieval using two frameworks. As the authors explain in their paper, DRAGIN has two key frameworks :
I. RIND (Real-time Information Needs Detection) : When to retrieve ?
It considers the LLM’s uncertainty about its own content, the influence of each token and the semantics of each token.
II. QFS (Query Formulation based on Self-Attention) : What to retrieve?
Query formulation leverages the LLM’s self-attention across the entire context, rather than not just the last few tokens or sentences.
Illustration of the DRAGIN framework
To illustrate the above frameworks, the paper uses an example query about the ‘brief introduction to Einstein’.
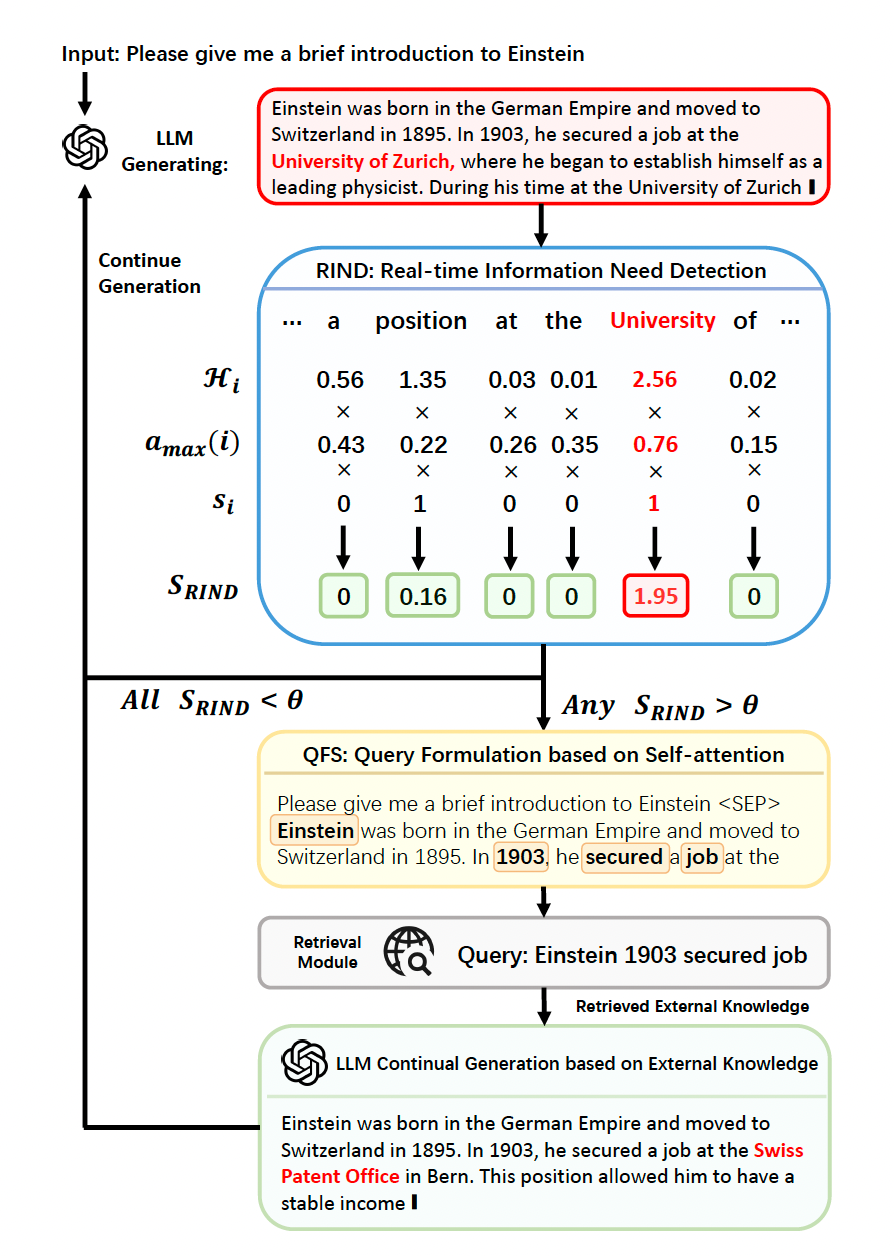
Figure 1 : An illustration of the DRAGIN framework, taken from the research paper
Explanation :
Input is Provided: The system is queried to provide some introduction about Einstein.
Processing Starts: The system begins generating a response based on what it knows. It uses the RIND module to decide if it has enough information or if it needs to look things up.
Checking for Required Information (RIND): The system breaks down the query into smaller parts (tokens), like “position,” “at,” “University,” etc. It checks which parts (tokens) need more information. For example, “university” might need additional data because it’s not specific enough.
Triggering Retrieval: If a token like “university” is considered to be important and unclear, the system triggers retrieval to gather external information about it. In this case, it looks up relevant data about Einstein and universities.
Formulating the Query (QFS): The system uses its self attention mechanism to determine which words are most relevant for forming a precise query. For example, it might pick “Einstein,” “1903,” and “secured a job” as the key parts.
These keywords are used to craft a query, such as “Einstein 1903 secured a job,” which is sent to an external source for information.
Retrieving and Adding Information: The external source provides the required details. For example, it might return, “In 1903, Einstein secured a job at the Swiss Patent Office.” The system incorporates this new information into the response.
Continuing Generation: With the new details, the system continues generating a more complete and accurate response.For example, it might now say, “In 1903, Einstein secured a job at the Swiss Patent Office. This allowed him to have a stable income.”
Repeating the Process: If more requirements are identified, the process repeats: checking, retrieving, and integrating information until the response is complete and accurate. This process ensures that the system can dynamically fill in gaps in its knowledge and provide detailed, accurate answers by combining what it knows with retrieved external information.
Detailed Methodology about RAG
The frameworks mentioned in the paper are:
A. Real-time Information Needs Detection (RIND) : Retrieval is triggered based on uncertainty of tokens, influence on other tokens and semantic significance of each token.
i. The uncertainty of each token generated by the LLM, is quantified. This is done by calculating the entropy of the token’s probability distribution across the vocabulary. Consider an output sequence T = {t1,t2,…tn}, with each ti representing an individual token at the position i. For any token ti, the entropy is calculated as follows :
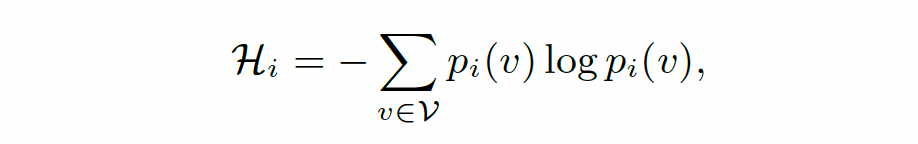
where pi(v) denotes the probability of generating the token v over all the tokens in the vocabulary.
ii. The influence of each token on subsequent tokens, is done by leveraging the self-attention scores. For a token t, the max attention value is identified
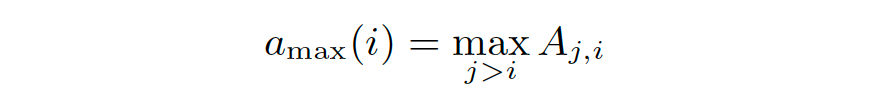
iii. The semantic contribution of each token ti, a binary indicator is employed. This filters out stop words.
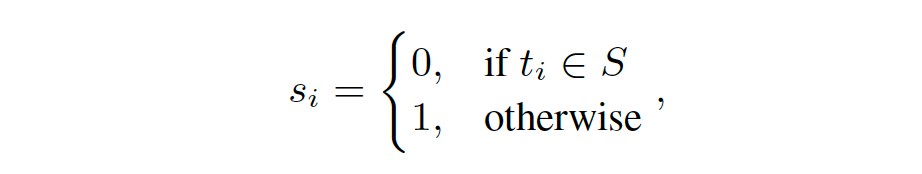
Combining the uncertainty, significance and semantics, RIND computes a score and if this is greater than a pre-defined threshold then retrieval is triggered.
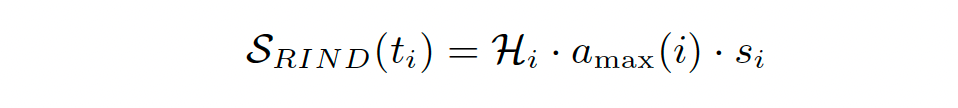
B. Query Formulation based on Self-Attention (QFS)
Once retrieval is triggered, the next step is to formulate an efficient query from external databases for the continued generation of LLMs. In the existing dynamic RAG frameworks, queries are formulated using the last sentence or last tokens generated by the LLM. This narrow scope doesn’t capture the need for real-time information needs. It examines the full context.
Suppose RIND identifies the token ti at position i, requires external knowledge and triggers retrieval.
Step 1: Extracts the attention scores of the last transformer layer for each token ti.
Step 2: Sorts the attention scores in descending order, to identify the top n scores. (This is basically, identifying the most important tokens).
Step 3: Finds the words corresponding to these tokens from the vocabulary and arranges them in their original order. (This brings back the structure of the language form the attention scores and tokens).
Step 4 : Construct the query Qi using the words associated with these top n tokens.
C. Continue Generation after Retrieval
Once RIND has identified the position i, at which external knowledge is needed and QFS creates the query, Qi to extract the information using an off-the-shelf retrieval model (e.g. BM25).
It finds the relevant information in documents Di1, Di2 and Di3. It integrates the relevant information at position i, by truncating the LLM’s output. This retrieved knowledge is integrated using the following designed prompt template.

Designed prompt template used to integrate externally retrieved information.
Limitations
As the paper states, the primary limitations of this paper is the reliance on the self-attention mechanisms for both the Real-time Information Needs Detection (RIND) and Query Formulation based on Self-Attention (QFS). While self-attention scores are available for all source LLMs, it is not applicable for certain APIs that do not provide access to self-attention scores.
A point worth considering is the impact on inference time latency and cost: in the paper, the authors point out that these are only marginally more since an imperfect token sub-sequence is rapidly detected, and further generation is interrupted until remediation.
Conclusion
The DRAGIN framework allows us to look to move a few steps ahead of the traditional RAG framework. It allows us to perform multiple retrievals, based on the information needs of generation. It is an optimized framework for multiple retrievals!
Our needs and requirements from LLMs are becoming larger and more complex, and in such cases where we want to retrieve information accurately, with just the right number of retrievals.
Thank you so much for reading and for a more detailed explanation of the research paper, please watch my video!
References :
[1] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. arXiv preprint arXiv:2212.10509.
[2] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. 2022.
[3] Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented language models. arXiv preprint arXiv:2302.00083.
[4] Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983.

DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Traditional RAG vs. dynamic RAG
In this article, I explore the fundamental concepts explained in the research paper titled “DRAGIN : Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language Models” by Weihang Su, Yichen Tang, Qingyao Ai, Zhijing Wu, and Yiqun Liu. This paper can be accessed here.
Introduction — Lets look at a short story!
Imagine you’re working on a problem. At the very beginning, you get only one chance to ask your professor for guidance. This means it’s important to understand the entire scope of the problem upfront. If it’s a simple problem, that might be fine — you ask your question, get clarity, and move forward.
Now, imagine that the problem is much more complex. The more you dive into it, the more questions you have! Unfortunately, you can’t go back to your professor because all your questions had to be asked at the start. This makes solving the problem much harder.
But what if, instead, you were allowed to go back to your professor every time you discovered a new question that expanded the scope of the problem? This approach lets you navigate the complexity iteratively, asking for guidance whenever the problem evolves. That is the essence of DRAGIN (Dynamic RAG) over Traditional RAG.
And given how complex and multi-dimensional our tasks, problems, and worlds have become, the need for this dynamic approach is greater than ever!
Image taken from Unsplash
Large Language models have changed the way we all access information. We are at that point where the way we search has forever changed. Now, instead of finding multiple links and processing the information to answer our questions, we can directly ask the LLM!
However, there are still a number of issues :
- Hallucinations : Generating fabricated information
- Datedness/Staleness : Inability to incorporate up to date information
- Proprietary Information : Inaccessibility to specialised knowledge
To overcome the above issues, Retrieval Augmented Generation (RAG) emerged as a promising solution. The way it works, is by accessing and incorporating the relevant external information needed for the LLM to generate accurate responses.
However with traditional RAG methods, they rely on single-round retrieval, which would mean retrieving external information once, at the start of the information generation. This works well for straightforward tasks, however our needs and requirements from LLMs are getting more complex, multi-step and requiring longer responses.
In these cases, a single-round of retrieval will not work well and mutiple rounds of retrieval need to be conducted. Now when, we talk about retrieving information more than once, the two next questions are :
When to retrieve and What to retrieve? To solve these, a number of RAG methods have been devised :
Fixed Retrieval Methods :
IRCoT (Fixed Sentence RAG) [1] : Retrieval is conducted for each generated query and the latest sentence is used as a query.
RETRO [2] and IC-RALM [3] (Fixed Length RAG) : A sliding window is defined and the retrieval module is triggered every n tokens.
But aren’t we retrieving too often and hence retrieving information that may be unnecessary ? This would introduce noise and could jeopardize the quality of the LLM’s outputs, which defeats the original purpose of improving accuracy. These rules are still static and we need to think of dynamic ways of retrieval.
Dynamic Retrieval Methods :FLARE [4] (Low Confidence RAG) : Retrieval is conducted dynamically, when the LLM’s confidence (the generation probability) on the next token is lower than certain thresholds. So FLARE, is triggering retrieval based on uncertainty.
For determining what to retrieve, the LLMs often restrict themselves to queries based on the last few generated tokens or sentences. These methods of query formulation for retrieval may not work, when the tasks get more complex and the LLM’s information needs span over the entire context!
Finally, moving on to the star of the show : DRAGIN!
DRAGIN (Dynamic Retrieval Augmented Generation based on Information Needs) :
This method is specifically designed to make decisions about when and what to retrieve to cater to the LLM’s information needs. So, it optimizes the process of information retrieval using two frameworks. As the authors explain in their paper, DRAGIN has two key frameworks :
I. RIND (Real-time Information Needs Detection) : When to retrieve ?
It considers the LLM’s uncertainty about its own content, the influence of each token and the semantics of each token.
II. QFS (Query Formulation based on Self-Attention) : What to retrieve?
Query formulation leverages the LLM’s self-attention across the entire context, rather than not just the last few tokens or sentences.
Illustration of the DRAGIN framework
To illustrate the above frameworks, the paper uses an example query about the ‘brief introduction to Einstein’.
Figure 1 : An illustration of the DRAGIN framework, taken from the research paper
Explanation :
Input is Provided: The system is queried to provide some introduction about Einstein.
Processing Starts: The system begins generating a response based on what it knows. It uses the RIND module to decide if it has enough information or if it needs to look things up.
Checking for Required Information (RIND): The system breaks down the query into smaller parts (tokens), like “position,” “at,” “University,” etc. It checks which parts (tokens) need more information. For example, “university” might need additional data because it’s not specific enough.
Triggering Retrieval: If a token like “university” is considered to be important and unclear, the system triggers retrieval to gather external information about it. In this case, it looks up relevant data about Einstein and universities.
Formulating the Query (QFS): The system uses its self attention mechanism to determine which words are most relevant for forming a precise query. For example, it might pick “Einstein,” “1903,” and “secured a job” as the key parts.
These keywords are used to craft a query, such as “Einstein 1903 secured a job,” which is sent to an external source for information.
Retrieving and Adding Information: The external source provides the required details. For example, it might return, “In 1903, Einstein secured a job at the Swiss Patent Office.” The system incorporates this new information into the response.
Continuing Generation: With the new details, the system continues generating a more complete and accurate response.For example, it might now say, “In 1903, Einstein secured a job at the Swiss Patent Office. This allowed him to have a stable income.”
Repeating the Process: If more requirements are identified, the process repeats: checking, retrieving, and integrating information until the response is complete and accurate. This process ensures that the system can dynamically fill in gaps in its knowledge and provide detailed, accurate answers by combining what it knows with retrieved external information.
Detailed Methodology about RAG
The frameworks mentioned in the paper are:
A. Real-time Information Needs Detection (RIND) : Retrieval is triggered based on uncertainty of tokens, influence on other tokens and semantic significance of each token.
i. The uncertainty of each token generated by the LLM, is quantified. This is done by calculating the entropy of the token’s probability distribution across the vocabulary. Consider an output sequence T = {t1,t2,…tn}, with each ti representing an individual token at the position i. For any token ti, the entropy is calculated as follows :
where pi(v) denotes the probability of generating the token v over all the tokens in the vocabulary.
ii. The influence of each token on subsequent tokens, is done by leveraging the self-attention scores. For a token t, the max attention value is identified
iii. The semantic contribution of each token ti, a binary indicator is employed. This filters out stop words.
Combining the uncertainty, significance and semantics, RIND computes a score and if this is greater than a pre-defined threshold then retrieval is triggered.
B. Query Formulation based on Self-Attention (QFS)
Once retrieval is triggered, the next step is to formulate an efficient query from external databases for the continued generation of LLMs. In the existing dynamic RAG frameworks, queries are formulated using the last sentence or last tokens generated by the LLM. This narrow scope doesn’t capture the need for real-time information needs. It examines the full context.
Suppose RIND identifies the token ti at position i, requires external knowledge and triggers retrieval.
Since the token ti was generated based on based on the knowledge of all the preceding tokens, it only makes sense to look at the entire content generated, until now, to formulate a query. It uses the following steps:
Step 1: Extracts the attention scores of the last transformer layer for each token ti.
Step 2: Sorts the attention scores in descending order, to identify the top n scores. (This is basically, identifying the most important tokens).
Step 3: Finds the words corresponding to these tokens from the vocabulary and arranges them in their original order. (This brings back the structure of the language form the attention scores and tokens).
Step 4 : Construct the query Qi using the words associated with these top n tokens.
C. Continue Generation after Retrieval
Once RIND has identified the position i, at which external knowledge is needed and QFS creates the query, Qi to extract the information using an off-the-shelf retrieval model (e.g. BM25).
It finds the relevant information in documents Di1, Di2 and Di3. It integrates the relevant information at position i, by truncating the LLM’s output. This retrieved knowledge is integrated using the following designed prompt template.
Designed prompt template used to integrate externally retrieved information.
Limitations
As the paper states, the primary limitations of this paper is the reliance on the self-attention mechanisms for both the Real-time Information Needs Detection (RIND) and Query Formulation based on Self-Attention (QFS). While self-attention scores are available for all source LLMs, it is not applicable for certain APIs that do not provide access to self-attention scores.
A point worth considering is the impact on inference time latency and cost: in the paper, the authors point out that these are only marginally more since an imperfect token sub-sequence is rapidly detected, and further generation is interrupted until remediation.
Conclusion
The DRAGIN framework allows us to look to move a few steps ahead of the traditional RAG framework. It allows us to perform multiple retrievals, based on the information needs of generation. It is an optimized framework for multiple retrievals!
Our needs and requirements from LLMs are becoming larger and more complex, and in such cases where we want to retrieve information accurately, with just the right number of retrievals.
To conclude, DRAGIN :
Strikes the perfect balance for the number of retrievals.
Produces highly context-aware queries for retrievals.
Generates content from the LLMs with better accuracy!
Produces highly context-aware queries for retrievals.
Generates content from the LLMs with better accuracy!
Thank you so much for reading and for a more detailed explanation of the research paper, please watch my video!
References :
[1] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. arXiv preprint arXiv:2212.10509.
[2] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. 2022.
[3] Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented language models. arXiv preprint arXiv:2302.00083.
[4] Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. arXiv preprint arXiv:2305.06983.
DRAGIN: Dynamic Retrieval Augmented Generation based on the Information Needs of Large Language… was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.