
Image credit: Adobe Stock.
GenAI Architecture Shifting Toward Interpretive Retrieval-Centric Generation Models
To transition from consumer to business deployment for GenAI, solutions should be built primarily around information external to the model using retrieval-centric generation (RCG).
As generative AI (GenAI) begins deployment throughout industries for a wide range of business usages, companies need models that provide efficiency, accuracy, security, and traceability. The original architecture of ChatGPT-like models has demonstrated a major gap in meeting these key requirements. With early GenAI models, retrieval has been used as an afterthought to address the shortcomings of models that rely on memorized information from parametric memory. Current models have made significant progress on that issue by enhancing the solution platforms with a retrieval-augmented generation (RAG) front-end to allow for extracting information external to the model. Perhaps it’s time to further rethink the architecture of generative AI and move from RAG systems where retrieval is an addendum to retrieval-centric generation (RCG) models built around retrieval as the core access to information.
Retrieval-centric generation models can be defined as a generative AI solution designed for systems where the vast majority of data resides outside the model parametric memory and is mostly not seen in pre-training or fine-tuning. With RCG, the primary role of the GenAI model is to interpret rich retrieved information from a company’s indexed data corpus or other curated content. Rather than memorizing data, the model focuses on fine-tuning for targeted constructs, relationships, and functionality. The quality of data in generated output is expected to approach 100% accuracy and timeliness. The ability to properly interpret and use large amounts of data not seen in pre-training requires increased abstraction of the model and the use of schemas as a key cognitive capability to identify complex patterns and relationships in information. These new requirements of retrieval coupled with automated learning of schemata will lead to further evolution in the pre-training and fine-tuning of large language models (LLMs).
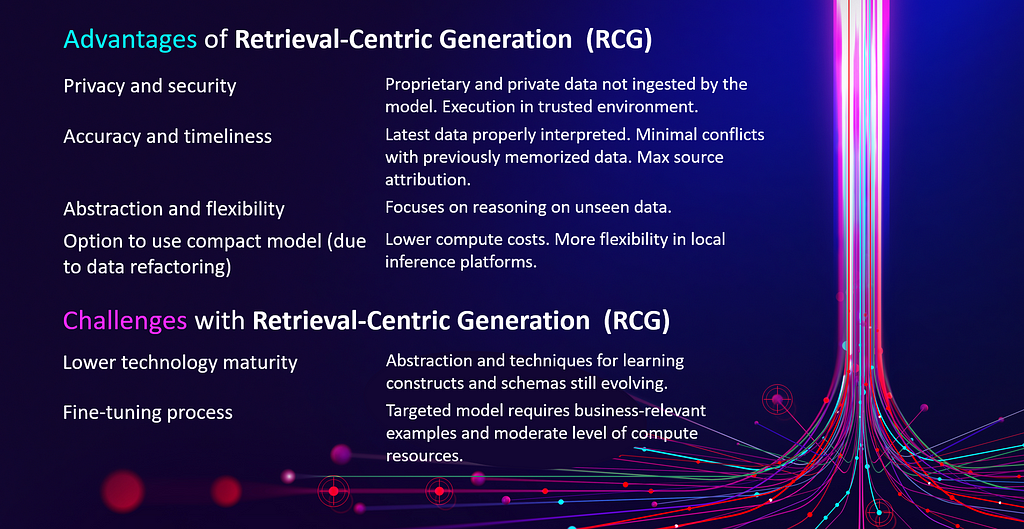
Figure 1. Advantages and challenges of retrieval-centric generation (RCG) versus retrieval-augmented generation (RAG). Image credit: Intel Labs.
Substantially reducing the use of memorized data from the parametric memory in GenAI models and instead relying on verifiable indexed sources will improve provenance and play an important role in enhancing accuracy and performance. The prevalent assumption in GenAI architectures up to now has been that more data in the model is better. Based on this currently predominant structure, it is expected that most tokens and concepts have been ingested and cross-mapped so that models can generate better answers from their parametric memory. However, in the common business scenario, the large majority of data utilized for the generated output is expected to come from retrieved inputs. We’re now observing that having more data in the model while relying on retrieved knowledge causes conflicts of information, or inclusion of data that can’t be traced or verified with its source. As I outlined in my last blog, Survival of the Fittest, smaller, nimble targeted models designed to use RCG don’t need to store as much data in parametric memory.
In business settings where the data will come primarily from retrieval, the targeted system needs to excel in interpreting unseen relevant information to meet company requirements. In addition, the prevalence of large vector databases and an increase in context window size (for example, OpenAI has recently increased the context window in GPT-4 Turbo from 32K to 128K) are shifting models toward reasoning and the interpretation of unseen complex data. Models now require intelligence to turn broad data into effective knowledge by utilizing a combination of sophisticated retrieval and fine-tuning. As models become retrieval-centric, cognitive competencies for creating and utilizing schemas will take center stage.
Consumer Versus Business Uses of GenAI
After a decade of rapid growth in AI model size and complexity, 2023 marks a shift in focus to efficiency and the targeted application of generative AI. The transition from a consumer focus to business usage is one of the key factors driving this change on three levels: quality of data, source of data, and targeted uses.
● Quality of data: When generating content and analysis for companies, 95% accuracy is insufficient. Businesses need near or at full accuracy. Fine-tuning for high performance on specific tasks and managing the quality of data used are both required for ensuring quality of output. Furthermore, data needs to be traceable and verifiable. Provenance matters, and retrieval is central for determining the source of content.
● Source of data: The vast majority of the data in business applications is expected to be curated from trusted external sources as well as proprietary business/enterprise data, including information about products, resources, customers, supply chain, internal operations, and more. Retrieval is central to accessing the latest and broadest set of proprietary data not pre-trained in the model. Models large and small can have problems with provenance when using data from their own internal memory versus verifiable, traceable data extracted from business sources. If the data conflicts, it can confuse the model.
● Targeted usages: The constructs and functions of models for companies tend to be specialized on a set of usages and types of data. When GenAI functionality is deployed in a specific workflow or business application, it is unlikely to require all-in-one functionality. And since the data will come primarily from retrieval, the targeted system needs to excel in interpreting relevant information unseen by the model in particular ways required by the company.
For example, if a financial or healthcare company pursues a GenAI model to improve its services, it will focus on a family of functions that are needed for their intended use. They have the option to pre-train a model from scratch and try to include all their proprietary information. However, such an effort is likely to be expensive, require deep expertise, and prone to fall behind quickly as the technology evolves and the company data continuously changes. Furthermore, it will need to rely on retrieval anyway for access to the latest concrete information. A more effective path is to take an existing pre-trained base model (like Meta’s Llama 2) and customize it through fine-tuning and indexing for retrieval. Fine-tuning uses just a small fraction of the information and tasks to refine the behavior of the model, but the extensive business proprietary information itself can be indexed and be available for retrieval as needed. As the base model gets updated with the latest GenAI technology, refreshing the target model should be a relatively straightforward process of repeating the fine-tuning flow.
Shift to Retrieval-Centric Generation: Architecting Around Indexed Information Extraction
Meta AI and university collaborators introduced retrieval-augmented generation in 2021 to address issues of provenance and updating world knowledge in LLMs. Researchers used RAG as a general-purpose approach to add non-parametric memory to pre-trained, parametric-memory generation models. The non-parametric memory used a Wikipedia dense vector index accessed by a pre-trained retriever. In a compact model with less memorized data, there is a strong emphasis on the breadth and quality of the indexed data referenced by the vector database because the model cannot rely on memorized information for business needs. Both RAG and RCG can use the same retriever approach by pulling relevant knowledge from a curated corpora on-the-fly during inference time (see Figure 2). They differ in the way the GenAI system places its information as well as in the interpretation expectations of previously unseen data. With RAG, the model itself is a major source of information, and it’s aided by retrieved data. In contrast, with RCG the vast majority of data resides outside the model parametric memory, making the interpretation of unseen data the model’s primary role.
It should be noted that many current RAG solutions rely on flows like LangChain or Haystack for concatenating a front-end retrieval with an independent vector store to a GenAI model that was not pre-trained with retrieval. These solutions provide an environment for indexing data sources, model choice, and model behavioral training. Other approaches, such as REALM by Google Research, experiment with end-to-end pre-training with integrated retrieval. Currently, OpenAI is optimizing its retrieval GenAI path rather than leaving it to the ecosystem to create the flow for ChatGPT. The company recently released Assistants API, which retrieves proprietary domain data, product information, or user documents external to the model.
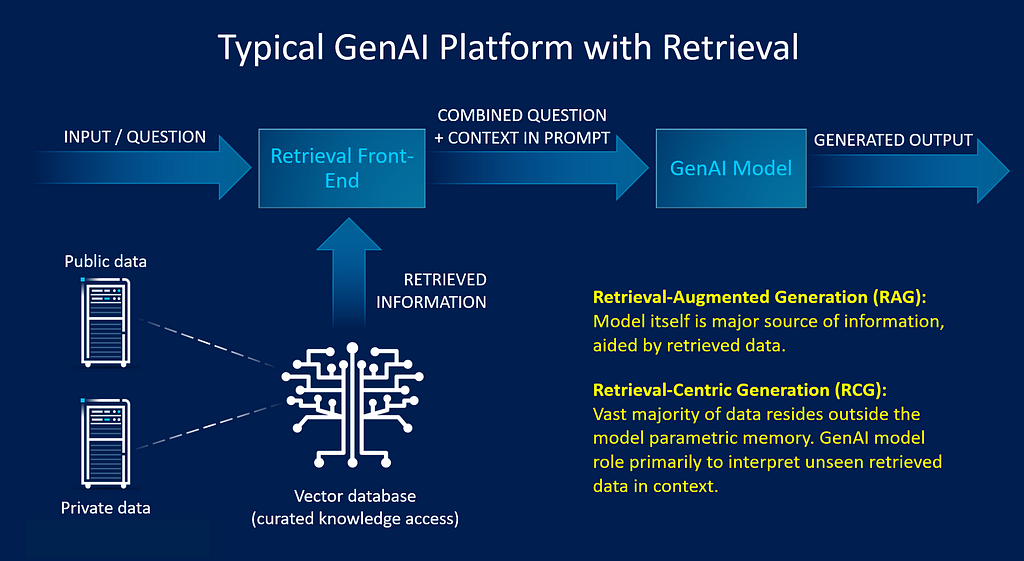
Figure 2. Both RCG and RAG retrieve public and private data during inference, but they differ in how they place and interpret unseen data. Image credit: Intel Labs.
In other examples, fast retriever models like Intel Labs’ fastRAG use pre-trained small foundation models to extract requested information from a knowledge base without any additional training, providing a more sustainable solution. Built as an extension to the open-source Haystack GenAI framework, fastRAG uses a retriever model to generate conversational answers by retrieving current documents from an external knowledge base. In addition, a team of researchers from Meta recently published a paper introducing Retrieval-Augmented Dual Instruction Tuning (RA-DIT), “a lightweight fine-tuning methodology that provides a third option by retrofitting any large language model with retrieval capabilities.”
The shift from RAG to RCG models challenges the role of information in training. Rather than being both the repository of information as well as the interpreter of information in response to a prompt, with RCG the model’s functionality shifts to primarily be an in-context interpreter of retrieved (usually business-curated) information. This may require a modified approach to pre-training and fine-tuning because the current objectives used to train language models may not be suitable for this type of learning. RCG requires different abilities from the model such as longer context, interpretability of data, curation of data, and other new challenges.
There are still rather few examples of RCG systems in academia or industry. In one instance, researchers from Kioxia Corporation created the open-source SimplyRetrieve, which uses an RCG architecture to boost the performance of LLMs by separating context interpretation and knowledge memorization. Implemented on a Wizard-Vicuna-13B model, researchers found that RCG answered a query about an organization’s factory location accurately. In contrast, RAG attempted to integrate the retrieved knowledge base with Wizard-Vicuna’s knowledge of the organization. This resulted in partially erroneous information or hallucinations. This is only one example — RAG and retrieval-off generation (ROG) may offer correct responses in other situations.

Figure 3. Comparison of retrieval-centric generation (RCG), retrieval-augmented generation (RAG), and retrieval-off generation (ROG). Correct responses are shown in blue while hallucinations are shown in red. Image credit: Kioxia Corporation.
In a way, transitioning from RAG to RCG can be likened to the difference in programming when using constants (RAG) and variables (RCG). When an AI model answers a question about a convertible Ford Mustang, a large model will be familiar with many of the car’s related details, such as year of introduction and engine specs. The large model can also add some recently retrieved updates, but it will respond primarily based on specific internal known terms or constants. However, when a model is deployed at an electric vehicle company preparing its next car release, the model requires reasoning and complex interpretation since most all the data will be unseen. The model will need to understand how to use the type of information, such as values for variables, to make sense of the data.
Schema: Generalization and Abstraction as a Competency During Inference
Much of the information retrieved in business settings (business organization and people, products and services, internal processes, and assets) would not have been seen by the corresponding GenAI model during pre-training and likely be just sampled during fine-tuning. This implies that the transformer architecture is not placing “known” words or terms (i.e., previously ingested by the model) as part of its generated output. Instead, the architecture is required to place unseen terms within proper in-context interpretation. This is somewhat similar to how in-context learning already enables some new reasoning capabilities in LLMs without additional training.
With this change, further improvements in generalization and abstraction are becoming a necessity. A key competency that needs to be enhanced is the ability to use learned schemas when interpreting and using unseen terms or tokens encountered at inference time through prompts. A schema in cognitive science “describes a pattern of thought or behavior that organizes categories of information and the relationships among them.” Mental schema “can be described as a mental structure, a framework representing some aspect of the world.” Similarly, in GenAI models schema is an essential abstraction mechanism required for proper interpretation of unseen tokens, terms, and data. Models today already display a fair grasp of emerging schema construction and interpretation, otherwise they would not be able to perform generative tasks on complex unseen prompt context data as well as they do. As the model retrieves previously unseen information, it needs to identify the best matching schema for the data. This allows the model to interpret the unseen data through knowledge related to the schema, not just explicit information incorporated in the context. It’s important to note that in this discussion I am referring to neural network models that learn and abstract the schema as an emergent capability, rather than the class of solutions that rely on an explicit schema represented in a knowledge graph and referenced during inference time.
Looking through the lens of the three types of model capabilities (cognitive competencies, functional skills, and information access), abstraction and schema usage belongs squarely in the cognitive competencies category. In particular, small models should be able to perform comparably to much larger ones (given the appropriate retrieved data) if they hone the skill to construct and use schema in interpreting data. It is to be expected that curriculum-based pre-training related to schemas will boost cognitive competencies in models. This includes the models’ ability to construct a variety of schemas, identify the appropriate schemas to use based on the generative process, and insert/utilize the information with the schema construct to create the best outcome.
For example, researchers showed how current LLMs can learn basic schemas using the Hypotheses-to-Theories (HtT) framework. Researchers found that an LLM can be used to generate rules that it then follows to solve numerical and relational reasoning problems. The rules discovered by GPT-4 could be viewed as a detailed schema for comprehending family relationships (see Figure 4). Future schemas of family relationships can be even more concise and powerful.

Figure 4. Using the CLUTRR dataset for relational reasoning, the Hypotheses-to-Theories framework prompts GPT-4 to generate schema-like rules for the LLM to follow when answering test questions. Image credit: Zhu et al.
Applying this to a simple business case, a GenAI model could use a schema for understanding the structure of a company’s supply chain. For instance, knowing that “B is a supplier of A” and “C is a supplier of B” implies that “C is a tier-two supplier of A” would be important when analyzing documents for potential supply chain risks.
In a more complex case such as teaching a GenAI model the variations and nuances of documenting a patient’s visit to a healthcare provider, an emergent schema established during pre-training or fine-tuning would provide a structure for understanding retrieved information for generating reports or supporting the healthcare team’s questions and answers. The schema could emerge in the model within a broader training/fine-tuning on patient care cases, which include appointments as well as other complex elements like tests and procedures. As the GenAI model is exposed to all the examples, it should create the expertise to interpret partial patient data that will be provided during inference. The model’s understanding of the process, relationships, and variations will allow it to properly interpret previously unseen patient cases without requiring the process information in the prompt. In contrast, it should not try to memorize particular patient information it is exposed to during pre-training or fine-tuning. Such memorization would be counterproductive because patients’ information continuously changes. The model needs to learn the constructs rather than the particular cases. Such a setup would also minimize potential privacy concerns.
Summary
As GenAI is deployed at scale in businesses across all industries, there is a distinct shift to reliance on high quality proprietary information as well as requirements for traceability and verifiability. These key requirements along with the pressure on cost efficiency and focused application are driving the need for small, targeted GenAI models that are designed to interpret local data, mostly unseen during the pre-training process. Retrieval-centric systems require elevating some cognitive competencies that can be mastered by deep learning GenAI models, such as constructing and identifying appropriate schemas to use. By using RCG and guiding the pre-training and fine-tuning process to create generalizations and abstractions that reflect cognitive constructs, GenAI can make a leap in its ability to comprehend schemas and make sense of unseen data from retrieval. Refined abstraction (such as schema-based reasoning) and highly efficient cognitive competencies seem to be the next frontier.
Learn More: GenAI Series
Survival of the Fittest: Compact Generative AI Models Are the Future for Cost-Effective AI at Scale
References
- Gillis, A. S. (2023, October 5). retrieval-augmented generation. Enterprise AI. https://www.techtarget.com/searchenterpriseai/definition/retrieval-augmented-generation
- Singer, G. (2023, July 28). Survival of the fittest: Compact generative AI models are the future for Cost-Effective AI at scale. Medium. https://towardsdatascience.com/surv...e-for-cost-effective-ai-at-scale-6bbdc138f618
- New models and developer products announced at DevDay. (n.d.). https://openai.com/blog/new-models-and-developer-products-announced-at-devday
- Meta AI. (n.d.). Introducing Llama 2. https://ai.meta.com/llama/
- Lewis, P. (2020, May 22). Retrieval-Augmented Generation for Knowledge-Intensive NLP tasks. arXiv.org. https://arxiv.org/abs/2005.11401
- LangChain. (n.d.). https://www.langchain.com
- Haystack. (n.d.). Haystack. https://haystack.deepset.ai/
- Guu, K. (2020, February 10). REALM: Retrieval-Augmented Language Model Pre-Training. arXiv.org. https://arxiv.org/abs/2002.08909
- Intel Labs. (n.d.). GitHub — Intel Labs/FastRAG: Efficient Retrieval Augmentation and Generation Framework. GitHub. https://github.com/IntelLabs/fastRAG
- Fleischer, D. (2023, August 20). Open Domain Q&A using Dense Retrievers in fastRAG — Daniel Fleischer — Medium. View: https://medium.com/@daniel.fleischer/open-domain-q-a-using-dense-retrievers-in-fastrag-65f60e7e9d1e
- Lin, X. V. (2023, October 2). RA-DIT: Retrieval-Augmented Dual Instruction Tuning. arXiv.org. https://arxiv.org/abs/2310.01352
- Ng, Y. (2023, August 8). SimplyRetrieve: a private and lightweight Retrieval-Centric generative AI tool. arXiv.org. https://arxiv.org/abs/2308.03983
- Wikipedia contributors. (2023, September 27). Schema (psychology). Wikipedia. https://en.wikipedia.org/wiki/Schema_(psychology)
- Wikipedia contributors. (2023a, August 31). Mental model. Wikipedia. https://en.wikipedia.org/wiki/Mental_schema
- Zhu, Z. (2023, October 10). Large Language Models can Learn Rules. arXiv.org. https://arxiv.org/abs/2310.07064
Knowledge Retrieval Takes Center Stage was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.