PyTorch Model Performance Analysis and Optimization — Part 6
How to Identify and Analyze Performance Issues in the Backward Pass with PyTorch Profiler, PyTorch Hooks, and TensorBoard

Photo by David Clode on Unsplash
This is the sixth part in our series of posts on the topic of analyzing and optimizing PyTorch models using PyTorch Profiler and TensorBoard. In this post we will tackle one of the more complicated types of performance issues to analyze — a bottleneck in the backward-propagation pass of a training step. We will explain what makes this type of bottleneck especially challenging and propose one way of analyzing it using PyTorch’s built-in support for attaching hooks to different parts of the training step. Many thanks to Yitzhak Levi for his contributions to this post.
Toy Model
To facilitate our discussion, we define a simple Vision Transformer (ViT)-based classification model using the popular timm python module (version 0.9.7). We define the model with the patch_drop_rate flag set to 0.5, which causes the model to randomly drop half of the patches in each training step. The training script is programmed to minimize non-determinsm, using the torch.use_deterministic_algorithms function and the cuBLAS environment variable, CUBLAS_WORKSPACE_CONFIG. Please see the code block below for the full model definition:
import torch, time, os
import torch.optim
import torch.profiler
import torch.utils.data
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset
# use the GPU
device = torch.device("cuda:0")
# configure PyTorch to use reproducible algorithms
torch.manual_seed(0)
os.environ[
"CUBLAS_WORKSPACE_CONFIG"
] = ":4096:8"
torch.use_deterministic_algorithms(True)
# define the ViT-backed classification model
model = VisionTransformer(patch_drop_rate=0.5).cuda(device)
# define the loss function
loss_fn = torch.nn.CrossEntropyLoss()
# define the training optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=[index % 1000], dtype=torch.int64)
return rand_image, label
train_set = FakeDataset()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=128,
num_workers=8, pin_memory=True)
t0 = time.perf_counter()
summ = 0
count = 0
model.train()
# training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/perf')
) as prof:
for step, data in enumerate(train_loader):
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
with torch.profiler.record_function('forward'):
outputs = model(inputs)
loss = loss_fn(outputs, label)
optimizer.zero_grad(set_to_none=True)
with torch.profiler.record_function('backward'):
loss.backward()
with torch.profiler.record_function('optimizer_step'):
optimizer.step()
prof.step()
batch_time = time.perf_counter() - t0
if step > 1: # skip first step
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 500:
break
print(f'average step time: {summ/count}')
We will run our experiments on an Amazon EC2 g5.2xlarge instance (containing an NVIDIA A10G GPU and 8 vCPUs) and using the official AWS PyTorch 2.0 Docker image.
Initial Performance Results
In the image below we capture the performance results as displayed in the TensorBoard plugin Trace View:
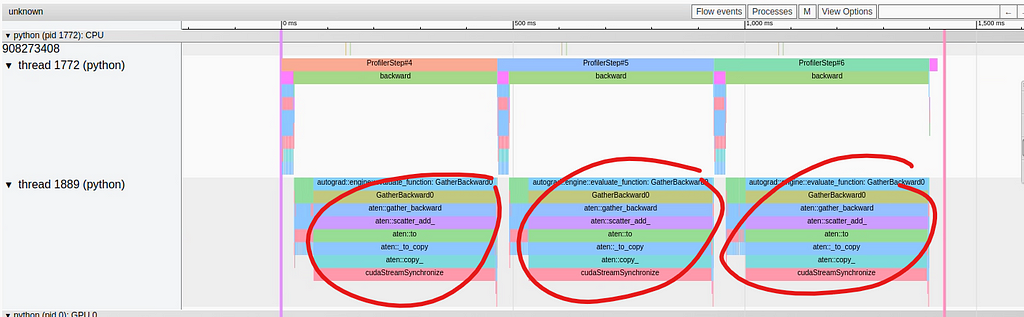
A Bottleneck in the Backward Pass (by Author)
While the operations in the forward pass of the training step are bunched together in the top thread, a performance issue appears to present itself in the backward pass in the bottom thread. There we see that a single operation, GatherBackward, takes up a significant portion of the trace. Taking a closer look, we can see that the underlying operations include “to”, “copy_”, and “cudaStreamSynchronize”. As we saw in part 2 of our series, these operations typically indicate that data is being copied from the host to the device — something that we would like to avoid mid-training-step.
At this point you will naturally being asking: Why is this happening? And what part of our model definition is causing it? The GatherBackward trace hints that a torch.gather operation may be involved, but where is it coming from and why is it causing a synchronization event?
In our previous posts (e.g., here), we advocated using labeled torch.profiler.record_function context managers in order to pinpoint the source of a performance issue. The problem here is that the performance issue occurs in the backward pass which we do not have control over! In particular, we do not have the ability to wrap individual operations in the backward pass with context managers. In theory, one could identify the problematic model operation through an in-depth analysis of the trace view and by matching each segment in the backward pass with its corresponding operation in the forward pass. However, not only can this be quite tedious, but it also requires an intimate knowledge of all of the low-level operations of the model training-step. The advantage to using torch.profiler.record_function labels was that it allowed us to easily zone in on the problematic portions of our model. Ideally, we would like to be able to retain the same capability even in the case of performance issues in the backward pass. In the next section we will describe how this can be achieved using PyTorch hooks.
Performance Analysis with PyTorch Backward Hooks
Although PyTorch does not allow you to wrap individual backward-pass operations, it does allow you to prepend and/or append custom functionality using its hook support. PyTorch supports registering hooks to both torch.Tensors and torch.nn.Modules. Although the technique we will propose in this post will rely on registering backward hooks to modules, tensor-hook registering can be similarly used to either replace or augment the module-based method.
In the code block below we define a wrapper function that takes a module and registers both a full_backward_hook and a full_backward_pre_hook (although in practice one should suffice). Each hook is programmed to simply add a message to the captured profiling trace using the torch.profiler.record_function function. The backward_pre_hook is programmed to print a “before” message and the backward_hook an “after” message. An optional details string is appended to distinguish between multiple instances of the same module type.
def backward_hook_wrapper(module, details=None):
# define register_full_backward_pre_hook function
def bwd_pre_hook_print(self, output):
message = f'before backward of {module.__class__.__qualname__}'
if details:
message = f'{message}: {details}'
with torch.profiler.record_function(message):
return output
# define register_full_backward_hook function
def bwd_hook_print(self, input, output):
message = f'after backward of {module.__class__.__qualname__}'
if details:
message = f'{message}: {details}'
with torch.profiler.record_function(message):
return input
# register hooks
module.register_full_backward_pre_hook(bwd_pre_hook_print)
module.register_full_backward_hook(bwd_hook_print)
return module
Using the backward_hook_wrapper function, we can begin the work of locating the source of our performance issue. We start by wrapping just the model and loss-function as in the code block below:
model = backward_hook_wrapper(model)
loss_fn = backward_hook_wrapper(loss_fn)
Using the search box of the TensorBoard plugin Trace View, we can identify the locations of our “before” and “after” messages and deduce where the backward propagation of the model and loss start and end. This enables us to conclude that the performance issue occurs in the backward pass of the model. The next step is to wrap the Vision Tranformer’s internal modules with our backward_hook_wrapper function:
model.patch_embed = backward_hook_wrapper(model.patch_embed)
model.pos_drop = backward_hook_wrapper(model.pos_drop)
model.patch_drop = backward_hook_wrapper(model.patch_drop)
model.norm_pre = backward_hook_wrapper(model.norm_pre)
model.blocks = backward_hook_wrapper(model.blocks)
model.norm = backward_hook_wrapper(model.norm)
model.fc_norm = backward_hook_wrapper(model.fc_norm)
model.head_drop = backward_hook_wrapper(model.head_drop)
In the code block above, we specified each of the internal modules. An alternative way to wrap all of model’s first-level modules is to iterate over its named_children:
for submodule in model.named_children():
submodule = backward_hook_wrapper(submodule)
The image capture below shows the presence of the “before backward of PatchDropout” message right before the problematic GatherBackward operation:

Identifying the Source of the Problematic Backward Operation in the Trace View (by Author)
Our profiling analysis has indicated that the source of the performance problem is the PathDropout module. Examining the forward function of the module, we can indeed see a call to torch.gather.
In the case of our toy model, we needed just two iterations of analysis in order to zone in on the source of the performance issue. In practice, it is likely that additional iterations of this method may be required.
Note that PyTorch includes the torch.nn.modules.module.register_module_full_backward_hook function that will — in a single call — append a hook to all of the modules in the training step. Although this may be sufficient in simple cases (such as our toy example), it does not enable one to distinguish between different instances of the same module type.
Now that we know the source of the performance issue, we can get to work on trying to fix it.
Optimization Proposal: Use Indexing Instead of Gather Wherever Possible
Now that we know that the source of the issue is in the torch.gather operation of the DropPatches module, we can research what the trigger of the lengthy host-device synchronization event might be. Our investigation takes us back to the documentation of the torch.use_deterministic_algorithms function which informs us that, when called on a CUDA tensor that requires grad, torch.gather exhibits nondeterministic behavior, unless torch.use_deterministic_algorithms is called with mode set to True. In other words, by configuring our script to use deterministic algorithms, we modified the default behavior of the torch.gather backward pass. As it turns out, it is precisely this change that causes the need for a sync event. Indeed, if we remove this configuration, the performance issue disappears! The question is, can we maintain the algorithm determinism without needing to pay a performance penalty.
In the code block below we propose an alternative implementation of the PathDropout module forward function that produces the same output using torch.Tensor indexing instead of torch.gather. The modified lines of code have been highlighted.
from timm.layers import PatchDropout
class MyPatchDropout(PatchDropout):
def forward(self, x):
prefix_tokens = x[:, :self.num_prefix_tokens]
x = x[:, self.num_prefix_tokens:]
B = x.shape[0]
L = x.shape[1]
num_keep = max(1, int(L * (1. - self.prob)))
keep_indices = torch.argsort(torch.randn(B, L, device=x.device),
dim=-1)[:, :num_keep]
# The following three lines were modified from the original
# to use PyTorch indexing rather than torch.gather
stride = L * torch.unsqueeze(torch.arange(B, device=x.device), 1)
keep_indices = (stride + keep_indices).flatten()
x = x.reshape(B * L, -1)[keep_indices].view(B, num_keep, -1)
x = torch.cat((prefix_tokens, x), dim=1)
return x
model.patch_drop = MyPatchDropout(
prob = model.patch_drop.prob,
num_prefix_tokens = model.patch_drop.num_prefix_tokens
)
In the image below we capture the Trace View following the above change:
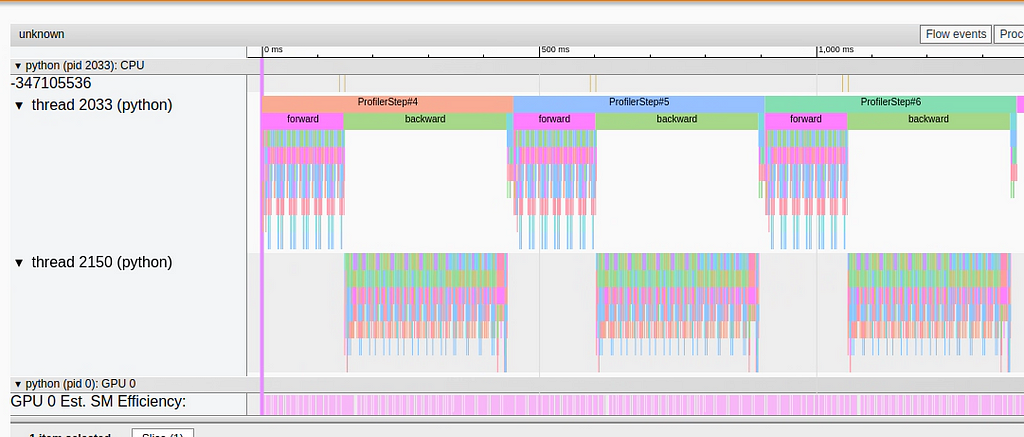
Trace View Following Optimization (by Author)
We can clearly see that the lengthy synchronization event is no longer present.
In the case of our toy model, we were fortunate enough that the way in which the torch.gather operation was used allowed it to be replaced with PyTorch indexing. Naturally, this is not always the case; other usages of torch.gather may not have an equivalent implementation based on indexing.
Results
In the table below we compare the performance results of training our toy model in different scenarios:
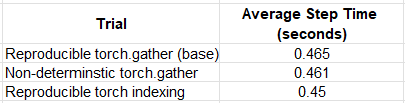
Optimization Results (by Author)
In the case of our toy example, the optimization had a modest, though measurable, impact — a performance boost of ~2%. Interestingly, torch indexing in the reproducible mode performed better than the default (non-deterministic) torch.gather. Based on these findings, it might be a good idea to evaluate the option of using indexing rather than torch.gather, whenever possible.
Summary
Despite PyTorch’s (justified) reputation for being easy to debug and trace, torch.autograd remains a bit of an enigma and analyzing the backward pass of a training step can be quite difficult. To address this challenge, PyTorch includes support for inserting hooks at different stages of the backward propagation. In this post, we have shown how PyTorch backward hooks, along with torch.profiler.record_function, can be used in an iterative process in order to identify the source of performance issues in the backward pass. We applied this technique to a simple ViT model and learned about some of the nuances of the torch.gather operation.
In this post we have covered a very specific type of performance bottleneck. Be sure to check out our other posts on medium which cover a wide variety of topics pertaining to performance analysis and performance optimization of machine learning workloads.

PyTorch Model Performance Analysis and Optimization — Part 6 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
How to Identify and Analyze Performance Issues in the Backward Pass with PyTorch Profiler, PyTorch Hooks, and TensorBoard
Photo by David Clode on Unsplash
This is the sixth part in our series of posts on the topic of analyzing and optimizing PyTorch models using PyTorch Profiler and TensorBoard. In this post we will tackle one of the more complicated types of performance issues to analyze — a bottleneck in the backward-propagation pass of a training step. We will explain what makes this type of bottleneck especially challenging and propose one way of analyzing it using PyTorch’s built-in support for attaching hooks to different parts of the training step. Many thanks to Yitzhak Levi for his contributions to this post.
Toy Model
To facilitate our discussion, we define a simple Vision Transformer (ViT)-based classification model using the popular timm python module (version 0.9.7). We define the model with the patch_drop_rate flag set to 0.5, which causes the model to randomly drop half of the patches in each training step. The training script is programmed to minimize non-determinsm, using the torch.use_deterministic_algorithms function and the cuBLAS environment variable, CUBLAS_WORKSPACE_CONFIG. Please see the code block below for the full model definition:
import torch, time, os
import torch.optim
import torch.profiler
import torch.utils.data
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset
# use the GPU
device = torch.device("cuda:0")
# configure PyTorch to use reproducible algorithms
torch.manual_seed(0)
os.environ[
"CUBLAS_WORKSPACE_CONFIG"
] = ":4096:8"
torch.use_deterministic_algorithms(True)
# define the ViT-backed classification model
model = VisionTransformer(patch_drop_rate=0.5).cuda(device)
# define the loss function
loss_fn = torch.nn.CrossEntropyLoss()
# define the training optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 224, 224], dtype=torch.float32)
label = torch.tensor(data=[index % 1000], dtype=torch.int64)
return rand_image, label
train_set = FakeDataset()
train_loader = torch.utils.data.DataLoader(train_set, batch_size=128,
num_workers=8, pin_memory=True)
t0 = time.perf_counter()
summ = 0
count = 0
model.train()
# training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('/tmp/perf')
) as prof:
for step, data in enumerate(train_loader):
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
with torch.profiler.record_function('forward'):
outputs = model(inputs)
loss = loss_fn(outputs, label)
optimizer.zero_grad(set_to_none=True)
with torch.profiler.record_function('backward'):
loss.backward()
with torch.profiler.record_function('optimizer_step'):
optimizer.step()
prof.step()
batch_time = time.perf_counter() - t0
if step > 1: # skip first step
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 500:
break
print(f'average step time: {summ/count}')
We will run our experiments on an Amazon EC2 g5.2xlarge instance (containing an NVIDIA A10G GPU and 8 vCPUs) and using the official AWS PyTorch 2.0 Docker image.
Initial Performance Results
In the image below we capture the performance results as displayed in the TensorBoard plugin Trace View:
A Bottleneck in the Backward Pass (by Author)
While the operations in the forward pass of the training step are bunched together in the top thread, a performance issue appears to present itself in the backward pass in the bottom thread. There we see that a single operation, GatherBackward, takes up a significant portion of the trace. Taking a closer look, we can see that the underlying operations include “to”, “copy_”, and “cudaStreamSynchronize”. As we saw in part 2 of our series, these operations typically indicate that data is being copied from the host to the device — something that we would like to avoid mid-training-step.
At this point you will naturally being asking: Why is this happening? And what part of our model definition is causing it? The GatherBackward trace hints that a torch.gather operation may be involved, but where is it coming from and why is it causing a synchronization event?
In our previous posts (e.g., here), we advocated using labeled torch.profiler.record_function context managers in order to pinpoint the source of a performance issue. The problem here is that the performance issue occurs in the backward pass which we do not have control over! In particular, we do not have the ability to wrap individual operations in the backward pass with context managers. In theory, one could identify the problematic model operation through an in-depth analysis of the trace view and by matching each segment in the backward pass with its corresponding operation in the forward pass. However, not only can this be quite tedious, but it also requires an intimate knowledge of all of the low-level operations of the model training-step. The advantage to using torch.profiler.record_function labels was that it allowed us to easily zone in on the problematic portions of our model. Ideally, we would like to be able to retain the same capability even in the case of performance issues in the backward pass. In the next section we will describe how this can be achieved using PyTorch hooks.
Performance Analysis with PyTorch Backward Hooks
Although PyTorch does not allow you to wrap individual backward-pass operations, it does allow you to prepend and/or append custom functionality using its hook support. PyTorch supports registering hooks to both torch.Tensors and torch.nn.Modules. Although the technique we will propose in this post will rely on registering backward hooks to modules, tensor-hook registering can be similarly used to either replace or augment the module-based method.
In the code block below we define a wrapper function that takes a module and registers both a full_backward_hook and a full_backward_pre_hook (although in practice one should suffice). Each hook is programmed to simply add a message to the captured profiling trace using the torch.profiler.record_function function. The backward_pre_hook is programmed to print a “before” message and the backward_hook an “after” message. An optional details string is appended to distinguish between multiple instances of the same module type.
def backward_hook_wrapper(module, details=None):
# define register_full_backward_pre_hook function
def bwd_pre_hook_print(self, output):
message = f'before backward of {module.__class__.__qualname__}'
if details:
message = f'{message}: {details}'
with torch.profiler.record_function(message):
return output
# define register_full_backward_hook function
def bwd_hook_print(self, input, output):
message = f'after backward of {module.__class__.__qualname__}'
if details:
message = f'{message}: {details}'
with torch.profiler.record_function(message):
return input
# register hooks
module.register_full_backward_pre_hook(bwd_pre_hook_print)
module.register_full_backward_hook(bwd_hook_print)
return module
Using the backward_hook_wrapper function, we can begin the work of locating the source of our performance issue. We start by wrapping just the model and loss-function as in the code block below:
model = backward_hook_wrapper(model)
loss_fn = backward_hook_wrapper(loss_fn)
Using the search box of the TensorBoard plugin Trace View, we can identify the locations of our “before” and “after” messages and deduce where the backward propagation of the model and loss start and end. This enables us to conclude that the performance issue occurs in the backward pass of the model. The next step is to wrap the Vision Tranformer’s internal modules with our backward_hook_wrapper function:
model.patch_embed = backward_hook_wrapper(model.patch_embed)
model.pos_drop = backward_hook_wrapper(model.pos_drop)
model.patch_drop = backward_hook_wrapper(model.patch_drop)
model.norm_pre = backward_hook_wrapper(model.norm_pre)
model.blocks = backward_hook_wrapper(model.blocks)
model.norm = backward_hook_wrapper(model.norm)
model.fc_norm = backward_hook_wrapper(model.fc_norm)
model.head_drop = backward_hook_wrapper(model.head_drop)
In the code block above, we specified each of the internal modules. An alternative way to wrap all of model’s first-level modules is to iterate over its named_children:
for submodule in model.named_children():
submodule = backward_hook_wrapper(submodule)
The image capture below shows the presence of the “before backward of PatchDropout” message right before the problematic GatherBackward operation:
Identifying the Source of the Problematic Backward Operation in the Trace View (by Author)
Our profiling analysis has indicated that the source of the performance problem is the PathDropout module. Examining the forward function of the module, we can indeed see a call to torch.gather.
In the case of our toy model, we needed just two iterations of analysis in order to zone in on the source of the performance issue. In practice, it is likely that additional iterations of this method may be required.
Note that PyTorch includes the torch.nn.modules.module.register_module_full_backward_hook function that will — in a single call — append a hook to all of the modules in the training step. Although this may be sufficient in simple cases (such as our toy example), it does not enable one to distinguish between different instances of the same module type.
Now that we know the source of the performance issue, we can get to work on trying to fix it.
Optimization Proposal: Use Indexing Instead of Gather Wherever Possible
Now that we know that the source of the issue is in the torch.gather operation of the DropPatches module, we can research what the trigger of the lengthy host-device synchronization event might be. Our investigation takes us back to the documentation of the torch.use_deterministic_algorithms function which informs us that, when called on a CUDA tensor that requires grad, torch.gather exhibits nondeterministic behavior, unless torch.use_deterministic_algorithms is called with mode set to True. In other words, by configuring our script to use deterministic algorithms, we modified the default behavior of the torch.gather backward pass. As it turns out, it is precisely this change that causes the need for a sync event. Indeed, if we remove this configuration, the performance issue disappears! The question is, can we maintain the algorithm determinism without needing to pay a performance penalty.
In the code block below we propose an alternative implementation of the PathDropout module forward function that produces the same output using torch.Tensor indexing instead of torch.gather. The modified lines of code have been highlighted.
from timm.layers import PatchDropout
class MyPatchDropout(PatchDropout):
def forward(self, x):
prefix_tokens = x[:, :self.num_prefix_tokens]
x = x[:, self.num_prefix_tokens:]
B = x.shape[0]
L = x.shape[1]
num_keep = max(1, int(L * (1. - self.prob)))
keep_indices = torch.argsort(torch.randn(B, L, device=x.device),
dim=-1)[:, :num_keep]
# The following three lines were modified from the original
# to use PyTorch indexing rather than torch.gather
stride = L * torch.unsqueeze(torch.arange(B, device=x.device), 1)
keep_indices = (stride + keep_indices).flatten()
x = x.reshape(B * L, -1)[keep_indices].view(B, num_keep, -1)
x = torch.cat((prefix_tokens, x), dim=1)
return x
model.patch_drop = MyPatchDropout(
prob = model.patch_drop.prob,
num_prefix_tokens = model.patch_drop.num_prefix_tokens
)
In the image below we capture the Trace View following the above change:
Trace View Following Optimization (by Author)
We can clearly see that the lengthy synchronization event is no longer present.
In the case of our toy model, we were fortunate enough that the way in which the torch.gather operation was used allowed it to be replaced with PyTorch indexing. Naturally, this is not always the case; other usages of torch.gather may not have an equivalent implementation based on indexing.
Results
In the table below we compare the performance results of training our toy model in different scenarios:
Optimization Results (by Author)
In the case of our toy example, the optimization had a modest, though measurable, impact — a performance boost of ~2%. Interestingly, torch indexing in the reproducible mode performed better than the default (non-deterministic) torch.gather. Based on these findings, it might be a good idea to evaluate the option of using indexing rather than torch.gather, whenever possible.
Summary
Despite PyTorch’s (justified) reputation for being easy to debug and trace, torch.autograd remains a bit of an enigma and analyzing the backward pass of a training step can be quite difficult. To address this challenge, PyTorch includes support for inserting hooks at different stages of the backward propagation. In this post, we have shown how PyTorch backward hooks, along with torch.profiler.record_function, can be used in an iterative process in order to identify the source of performance issues in the backward pass. We applied this technique to a simple ViT model and learned about some of the nuances of the torch.gather operation.
In this post we have covered a very specific type of performance bottleneck. Be sure to check out our other posts on medium which cover a wide variety of topics pertaining to performance analysis and performance optimization of machine learning workloads.
PyTorch Model Performance Analysis and Optimization — Part 6 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.