PyTorch Native FP8 Data Types
Accelerating PyTorch Training Workloads with FP8 — Part 2

Photo by Alex Lion on Unsplash
As the presence of AI-based applications becomes more and more ubiquitous in our daily lives, the challenge of optimizing their runtime performance increases. Reducing the number of bits that are used to represent floating-point types is a common technique that can accelerate AI applications and reduce their memory footprint. And indeed, many modern-day AI hardware accelerators include dedicated support for 8-bit floating point representations. In a previous post, we discussed the potential (and risks) of training with FP8 and demonstrated it in practice on an H100-based training instance using PyTorch and Transformer Engine (TE), a dedicated library for accelerating Transformer models on NVIDIA GPUs. Naturally, it was only a matter of time until PyTorch introduced native support for FP8 data types. In this post we will review the current capabilities and demonstrate their use on another FP8-supporting AI chip, the NVIDIA L4 GPU. More specifically, we will run our experiments on a Google Cloud g2-standard-16 VM (with a single L4 GPU), a dedicated deep learning VM image, and PyTorch 2.3.0.
Importantly, as of the time of this writing the PyTorch-native FP8 support is highly experimental. Its use is not recommended for the faint-of-heart or fault-intolerant. This post is intended primarily for early adopters — anybody who (like us) is obsessed with AI model performance optimization and the potential goodness of this new technology. Keep in mind that the APIs we refer may undergo revision by the time you read this post.
Our focus will be on the potential impact that using FP8 can have on the runtime performance of AI applications. To learn about the algorithmic implications, we refer the reader to dedicated tutorials on the topic (such as here and here).
Many thanks to Yitzhak Levi for his contributions to this post.
PyTorch Native Float8 Types
As of version 2.2, PyTorch includes “limited support” for the torch.float8_e4m3fn and torch.float8_e5m2 data types (with 3 and 2 mantissa bits, respectively) both of which are implementations of types specified in the FP8 Formats for Deep Learning paper. In the snippet of code below we display the properties and dynamic range of the new types compared to the legacy floating bit types:
import torch
from tabulate import tabulate
f32_type = torch.float32
bf16_type = torch.bfloat16
e4m3_type = torch.float8_e4m3fn
e5m2_type = torch.float8_e5m2
# collect finfo for each type
table = []
for dtype in [f32_type, bf16_type, e4m3_type, e5m2_type]:
numbits = 32 if dtype == f32_type else 16 if dtype == bf16_type else 8
info = torch.finfo(dtype)
table.append([info.dtype, numbits, info.max,
info.min, info.smallest_normal, info.eps])
headers = ['data type', 'bits', 'max', 'min', 'smallest normal', 'eps']
print(tabulate(table, headers=headers))
'''
Output:
data type bits max min smallest normal eps
------------- ---- ----------- ------------ --------------- -----------
float32 32 3.40282e+38 -3.40282e+38 1.17549e-38 1.19209e-07
bfloat16 16 3.38953e+38 -3.38953e+38 1.17549e-38 0.0078125
float8_e4m3fn 8 448 -448 0.015625 0.125
float8_e5m2 8 57344 -57344 6.10352e-05 0.25
'''
We can create FP8 tensors by specifying the dtype in the tensor initialization function as demonstrated below:
device="cuda"
e4m3 = torch.tensor(1., device=device, dtype=e4m3_type)
e5m2 = torch.tensor(1., device=device, dtype=e5m2_type)
We can also cast legacy types to FP8. In the code block below we generate a random tensor of floats and compare the results of casting them into four different floating-point types:
x = torch.randn(2, 2, device=device, dtype=f32_type)
x_bf16 = x.to(bf16_type)
x_e4m3 = x.to(e4m3_type)
x_e5m2 = x.to(e5m2_type)
print(tabulate([[‘float32’, *x.cpu().flatten().tolist()],
[‘bfloat16’, *x_bf16.cpu().flatten().tolist()],
[‘float8_e4m3fn’, *x_e4m3.cpu().flatten().tolist()],
[‘float8_e5m2’, *x_e5m2.cpu().flatten().tolist()]],
headers=[‘data type’, ‘x1’, ‘x2’, ‘x3’, ‘x4’]))
'''
The sample output demonstrates the dynamic range of the different types:
data type x1 x2 x3 x4
------------- -------------- -------------- -------------- --------------
float32 2.073093891143 -0.78251332044 -0.47084918620 -1.32557279110
bfloat16 2.078125 -0.78125 -0.4707031 -1.328125
float8_e4m3fn 2.0 -0.8125 -0.46875 -1.375
float8_e5m2 2.0 -0.75 -0.5 -1.25
------------- -------------- -------------- -------------- --------------
'''
Although creating FP8 tensors is easy enough, you may quickly find that performing some basic arithmetic operations on FP8 tensors is not supported (in PyTorch 2.3.0, as of the time of this writing). The one (arguably most important) exception is FP8 matrix multiplication, which is supported via the dedicated torch._scaled_mm function. Demonstrated in the code block below, this function receives two FP8 tensors (of identical type) and their associated scaling factors, as well as an optional bias tensor:
output, output_amax = torch._scaled_mm(
torch.randn(16,16, device=device).to(e4m3_type),
torch.randn(16,16, device=device).to(e4m3_type).t(),
bias=torch.randn(16, device=device).to(bf16_type),
out_dtype=e4m3_type,
scale_a=torch.tensor(1.0, device=device),
scale_b=torch.tensor(1.0, device=device)
)
To get a better feel for the current API capabilities and usage modes, you can take a look at the API test script in the PyTorch repository.
Contrary to the FP8 support in the Transformer Engine library that we demonstrated in our previous post, the PyTorch natives enable the explicit definition and use of FP8 data types. This provides advanced developers with much greater flexibility in designing and implementing custom FP8 algorithms. However, as discussed in our previous post, successful FP8 ML model training often requires some creative acrobatics; many users will desire a high-level API that automatically applies battle-tested scaling and type conversion schemes to their existing AI model training algorithms. While not (as of the time of this writing) part of the official PyTorch library, such functionality is offered via the float8_experimental library.
Training with in Native PyTorch with FP8
In this section, we will demonstrate the use of the float8_experimental library on a simple Vision Transformer (ViT-Huge) backed classification model with 632 million parameters (using version 1.0.3 of the popular timm Python package). Please see the documentation for instructions on installing the float8_experimental library. We set the ViT backbone to use average global pooling to avoid some kinks in the current offering (e.g., see here). In the code block below, we demonstrate FP8 training with the delayed scaling strategy on a randomly generated dataset. We include controls for toggling the floating point type, using torch.compile mode, and setting the batch size.
import torch
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset, DataLoader
import os
import time
#float8 imports
from float8_experimental import config
from float8_experimental.float8_linear import Float8Linear
from float8_experimental.float8_linear_utils import (
swap_linear_with_float8_linear,
sync_float8_amax_and_scale_history
)
#float8 configuration (see documentation)
config.enable_amax_init = False
config.enable_pre_and_post_forward = False
# model configuration controls:
fp8_type = True # toggle to change floating-point precision
compile_model = True # toggle to enable model compilation
batch_size = 32 if fp8_type else 16 # control batch size
device = torch.device('cuda')
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 256, 256], dtype=torch.float32)
label = torch.tensor(data=[index % 1024], dtype=torch.int64)
return rand_image, label
# get data loader
def get_data(batch_size):
ds = FakeDataset()
return DataLoader(
ds,
batch_size=batch_size,
num_workers=os.cpu_count(),
pin_memory=True
)
# define the timm model
def get_model():
model = VisionTransformer(
class_token=False,
global_pool="avg",
img_size=256,
embed_dim=1280,
num_classes=1024,
depth=32,
num_heads=16
)
if fp8_type:
swap_linear_with_float8_linear(model, Float8Linear)
return model
# define the training step
def train_step(inputs, label, model, optimizer, criterion):
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
if fp8_type:
sync_float8_amax_and_scale_history(model)
optimizer.step()
model = get_model()
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.CrossEntropyLoss()
train_loader = get_data(batch_size)
# copy the model to the GPU
model = model.to(device)
if compile_model:
# compile model
model = torch.compile(model)
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(train_loader):
# copy data to GPU
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
# train step
train_step(inputs, label, model, optimizer, criterion)
# capture step time
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 50:
break
print(f'average step time: {summ / count}')
The first thing we note is that the use of the lower precision data type frees up GPU memory which enables us to double the batch size. The table below summarizes the performance results (as measured by the average step time) when training with a variety of configuration settings. As suggested in the documentation, the torch.compile FP8 experiment was run using a nightly version of PyTorch (specifically version torch-2.4.0.dev20240520+cu121).
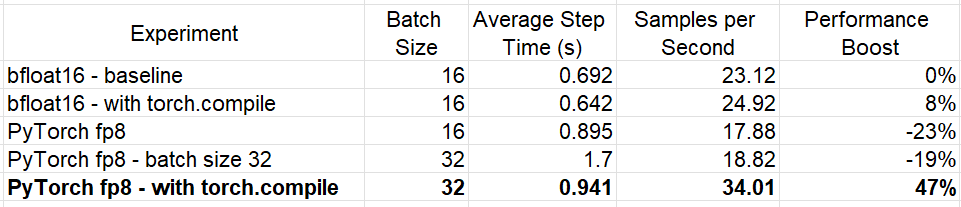
Experiment Results (By Author)
As the results demonstrate, the use of FP8 linear layers increases the performance of our toy model by 47%(!!) over our baseline experiment, but only when it is combined with the use of torch.compile. Naturally, the results will vary based on the definition and size of the model.
Comparison to Transformer Engine
For the sake of comparison, we implement the same training sequence using the Transformer Engine (TE) library (version 1.6). Although TE includes its own optimized TransformerLayer (as demonstrated in our previous post), we manually overwrite the torch.nn.Linear layer with the TE Linear layer in order to limit our comparative evaluation to just the FP8 linear support. In the code block below, we implement a simple linear layer swapping utility (use at your own risk!!) and apply it to our ViT model. We also include the training step function required for FP8 training using TE:
import transformer_engine.pytorch as te
# swap all linear layers with te.Linear
def simple_swap(model):
for submodule_name, submodule in model.named_modules():
if isinstance(submodule, torch.nn.Linear):
print(submodule_name)
path_in_state_dict = submodule_name.split('.')
current_module = model
# traverse to leaf module
leaf_path = path_in_state_dict[:-1]
leaf_name = path_in_state_dict[-1]
for child_name in leaf_path:
current_module = getattr(current_module, child_name)
# perform a swap
old_leaf = getattr(current_module, leaf_name)
new_leaf = te.Linear(old_leaf.in_features,
old_leaf.out_features,
old_leaf.bias is not None)
setattr(current_module, leaf_name, new_leaf)
def get_model():
model = VisionTransformer(
class_token=False,
global_pool="avg",
img_size=256,
embed_dim=1280,
num_classes=1024,
depth=32,
num_heads=16
)
simple_swap(model)
return model
def train_step(inputs, label, model, optimizer, criterion):
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
with te.fp8_autocast(enabled=True):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
The results of the TE experiments are captured below:
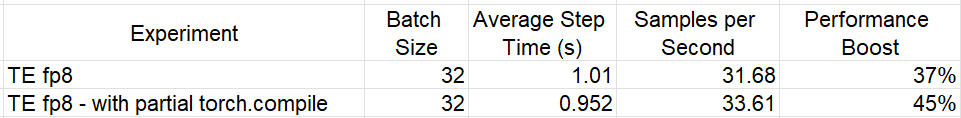
While the uncompiled TE FP8 model performs significantly better than our previous FP8 model, the compiled PyTorch FP8 model still provides the best results. Importantly, as of the time of this writing, TE FP8 modules do not support model compilation. Thus, applying torch.compile will result in “partial compilation”, i.e. it will include multiple graph breaks (every time FP8 is used).
We intentionally limited our tests to just the linear layers of our toy model. Unsurprisingly, applying the full power of TE to our model, as demonstrated in our previous post, would have resulted in a 72% boost (compared to our baseline experiment).
For a more detailed comparison between the TE and PyTorch-native FP8 operators, covering a wide range of matrix sizes, we recommend following this github issue.
Conclusions
Although still in its early days with clear room for improvement both in terms of API coverage and performance, we have succeeded in demonstrating some of the potential advantages of the PyTorch native FP8 support. First, the ability to explicitly declare and operate on FP8 tensors will enable developers much greater freedom in customizing FP8-based algorithms. Second, the built-in support for JIT-compilation facilitates greater potential for runtime optimization. A third advantage (not demonstrated here) is the ability to support a greater range of FP8-supporting devices. This is contrary to TE which is developed by NVIDIA and heavily tailored to their GPUs.
Summary
The ever-increasing size of AI models necessitates advanced techniques and algorithms for both reducing memory footprint and boosting runtime performance. Using the FP8 data type on dedicated HW accelerators offers the ability to achieve both. Although our focus has been on model training, the implications are no less important on model inference, where the time that it takes to load a large model into memory and run it, can have a decisive impact on a user’s experience.
The newly defined PyTorch-native FP8 data types and operators that we experimented with in this post, are certain to facilitate and accelerate the adoption of this important technology. We look forward to seeing how this native support evolves and matures.
For more tools and techniques for AI model optimization, be sure to check out some of our other posts.

PyTorch Native FP8 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Accelerating PyTorch Training Workloads with FP8 — Part 2
Photo by Alex Lion on Unsplash
As the presence of AI-based applications becomes more and more ubiquitous in our daily lives, the challenge of optimizing their runtime performance increases. Reducing the number of bits that are used to represent floating-point types is a common technique that can accelerate AI applications and reduce their memory footprint. And indeed, many modern-day AI hardware accelerators include dedicated support for 8-bit floating point representations. In a previous post, we discussed the potential (and risks) of training with FP8 and demonstrated it in practice on an H100-based training instance using PyTorch and Transformer Engine (TE), a dedicated library for accelerating Transformer models on NVIDIA GPUs. Naturally, it was only a matter of time until PyTorch introduced native support for FP8 data types. In this post we will review the current capabilities and demonstrate their use on another FP8-supporting AI chip, the NVIDIA L4 GPU. More specifically, we will run our experiments on a Google Cloud g2-standard-16 VM (with a single L4 GPU), a dedicated deep learning VM image, and PyTorch 2.3.0.
Importantly, as of the time of this writing the PyTorch-native FP8 support is highly experimental. Its use is not recommended for the faint-of-heart or fault-intolerant. This post is intended primarily for early adopters — anybody who (like us) is obsessed with AI model performance optimization and the potential goodness of this new technology. Keep in mind that the APIs we refer may undergo revision by the time you read this post.
Our focus will be on the potential impact that using FP8 can have on the runtime performance of AI applications. To learn about the algorithmic implications, we refer the reader to dedicated tutorials on the topic (such as here and here).
Many thanks to Yitzhak Levi for his contributions to this post.
PyTorch Native Float8 Types
As of version 2.2, PyTorch includes “limited support” for the torch.float8_e4m3fn and torch.float8_e5m2 data types (with 3 and 2 mantissa bits, respectively) both of which are implementations of types specified in the FP8 Formats for Deep Learning paper. In the snippet of code below we display the properties and dynamic range of the new types compared to the legacy floating bit types:
import torch
from tabulate import tabulate
f32_type = torch.float32
bf16_type = torch.bfloat16
e4m3_type = torch.float8_e4m3fn
e5m2_type = torch.float8_e5m2
# collect finfo for each type
table = []
for dtype in [f32_type, bf16_type, e4m3_type, e5m2_type]:
numbits = 32 if dtype == f32_type else 16 if dtype == bf16_type else 8
info = torch.finfo(dtype)
table.append([info.dtype, numbits, info.max,
info.min, info.smallest_normal, info.eps])
headers = ['data type', 'bits', 'max', 'min', 'smallest normal', 'eps']
print(tabulate(table, headers=headers))
'''
Output:
data type bits max min smallest normal eps
------------- ---- ----------- ------------ --------------- -----------
float32 32 3.40282e+38 -3.40282e+38 1.17549e-38 1.19209e-07
bfloat16 16 3.38953e+38 -3.38953e+38 1.17549e-38 0.0078125
float8_e4m3fn 8 448 -448 0.015625 0.125
float8_e5m2 8 57344 -57344 6.10352e-05 0.25
'''
We can create FP8 tensors by specifying the dtype in the tensor initialization function as demonstrated below:
device="cuda"
e4m3 = torch.tensor(1., device=device, dtype=e4m3_type)
e5m2 = torch.tensor(1., device=device, dtype=e5m2_type)
We can also cast legacy types to FP8. In the code block below we generate a random tensor of floats and compare the results of casting them into four different floating-point types:
x = torch.randn(2, 2, device=device, dtype=f32_type)
x_bf16 = x.to(bf16_type)
x_e4m3 = x.to(e4m3_type)
x_e5m2 = x.to(e5m2_type)
print(tabulate([[‘float32’, *x.cpu().flatten().tolist()],
[‘bfloat16’, *x_bf16.cpu().flatten().tolist()],
[‘float8_e4m3fn’, *x_e4m3.cpu().flatten().tolist()],
[‘float8_e5m2’, *x_e5m2.cpu().flatten().tolist()]],
headers=[‘data type’, ‘x1’, ‘x2’, ‘x3’, ‘x4’]))
'''
The sample output demonstrates the dynamic range of the different types:
data type x1 x2 x3 x4
------------- -------------- -------------- -------------- --------------
float32 2.073093891143 -0.78251332044 -0.47084918620 -1.32557279110
bfloat16 2.078125 -0.78125 -0.4707031 -1.328125
float8_e4m3fn 2.0 -0.8125 -0.46875 -1.375
float8_e5m2 2.0 -0.75 -0.5 -1.25
------------- -------------- -------------- -------------- --------------
'''
Although creating FP8 tensors is easy enough, you may quickly find that performing some basic arithmetic operations on FP8 tensors is not supported (in PyTorch 2.3.0, as of the time of this writing). The one (arguably most important) exception is FP8 matrix multiplication, which is supported via the dedicated torch._scaled_mm function. Demonstrated in the code block below, this function receives two FP8 tensors (of identical type) and their associated scaling factors, as well as an optional bias tensor:
output, output_amax = torch._scaled_mm(
torch.randn(16,16, device=device).to(e4m3_type),
torch.randn(16,16, device=device).to(e4m3_type).t(),
bias=torch.randn(16, device=device).to(bf16_type),
out_dtype=e4m3_type,
scale_a=torch.tensor(1.0, device=device),
scale_b=torch.tensor(1.0, device=device)
)
To get a better feel for the current API capabilities and usage modes, you can take a look at the API test script in the PyTorch repository.
Contrary to the FP8 support in the Transformer Engine library that we demonstrated in our previous post, the PyTorch natives enable the explicit definition and use of FP8 data types. This provides advanced developers with much greater flexibility in designing and implementing custom FP8 algorithms. However, as discussed in our previous post, successful FP8 ML model training often requires some creative acrobatics; many users will desire a high-level API that automatically applies battle-tested scaling and type conversion schemes to their existing AI model training algorithms. While not (as of the time of this writing) part of the official PyTorch library, such functionality is offered via the float8_experimental library.
Training with in Native PyTorch with FP8
In this section, we will demonstrate the use of the float8_experimental library on a simple Vision Transformer (ViT-Huge) backed classification model with 632 million parameters (using version 1.0.3 of the popular timm Python package). Please see the documentation for instructions on installing the float8_experimental library. We set the ViT backbone to use average global pooling to avoid some kinks in the current offering (e.g., see here). In the code block below, we demonstrate FP8 training with the delayed scaling strategy on a randomly generated dataset. We include controls for toggling the floating point type, using torch.compile mode, and setting the batch size.
import torch
from timm.models.vision_transformer import VisionTransformer
from torch.utils.data import Dataset, DataLoader
import os
import time
#float8 imports
from float8_experimental import config
from float8_experimental.float8_linear import Float8Linear
from float8_experimental.float8_linear_utils import (
swap_linear_with_float8_linear,
sync_float8_amax_and_scale_history
)
#float8 configuration (see documentation)
config.enable_amax_init = False
config.enable_pre_and_post_forward = False
# model configuration controls:
fp8_type = True # toggle to change floating-point precision
compile_model = True # toggle to enable model compilation
batch_size = 32 if fp8_type else 16 # control batch size
device = torch.device('cuda')
# use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
rand_image = torch.randn([3, 256, 256], dtype=torch.float32)
label = torch.tensor(data=[index % 1024], dtype=torch.int64)
return rand_image, label
# get data loader
def get_data(batch_size):
ds = FakeDataset()
return DataLoader(
ds,
batch_size=batch_size,
num_workers=os.cpu_count(),
pin_memory=True
)
# define the timm model
def get_model():
model = VisionTransformer(
class_token=False,
global_pool="avg",
img_size=256,
embed_dim=1280,
num_classes=1024,
depth=32,
num_heads=16
)
if fp8_type:
swap_linear_with_float8_linear(model, Float8Linear)
return model
# define the training step
def train_step(inputs, label, model, optimizer, criterion):
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
if fp8_type:
sync_float8_amax_and_scale_history(model)
optimizer.step()
model = get_model()
optimizer = torch.optim.Adam(model.parameters())
criterion = torch.nn.CrossEntropyLoss()
train_loader = get_data(batch_size)
# copy the model to the GPU
model = model.to(device)
if compile_model:
# compile model
model = torch.compile(model)
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(train_loader):
# copy data to GPU
inputs = data[0].to(device=device, non_blocking=True)
label = data[1].squeeze(-1).to(device=device, non_blocking=True)
# train step
train_step(inputs, label, model, optimizer, criterion)
# capture step time
batch_time = time.perf_counter() - t0
if step > 10: # skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step > 50:
break
print(f'average step time: {summ / count}')
The first thing we note is that the use of the lower precision data type frees up GPU memory which enables us to double the batch size. The table below summarizes the performance results (as measured by the average step time) when training with a variety of configuration settings. As suggested in the documentation, the torch.compile FP8 experiment was run using a nightly version of PyTorch (specifically version torch-2.4.0.dev20240520+cu121).
Experiment Results (By Author)
As the results demonstrate, the use of FP8 linear layers increases the performance of our toy model by 47%(!!) over our baseline experiment, but only when it is combined with the use of torch.compile. Naturally, the results will vary based on the definition and size of the model.
Comparison to Transformer Engine
For the sake of comparison, we implement the same training sequence using the Transformer Engine (TE) library (version 1.6). Although TE includes its own optimized TransformerLayer (as demonstrated in our previous post), we manually overwrite the torch.nn.Linear layer with the TE Linear layer in order to limit our comparative evaluation to just the FP8 linear support. In the code block below, we implement a simple linear layer swapping utility (use at your own risk!!) and apply it to our ViT model. We also include the training step function required for FP8 training using TE:
import transformer_engine.pytorch as te
# swap all linear layers with te.Linear
def simple_swap(model):
for submodule_name, submodule in model.named_modules():
if isinstance(submodule, torch.nn.Linear):
print(submodule_name)
path_in_state_dict = submodule_name.split('.')
current_module = model
# traverse to leaf module
leaf_path = path_in_state_dict[:-1]
leaf_name = path_in_state_dict[-1]
for child_name in leaf_path:
current_module = getattr(current_module, child_name)
# perform a swap
old_leaf = getattr(current_module, leaf_name)
new_leaf = te.Linear(old_leaf.in_features,
old_leaf.out_features,
old_leaf.bias is not None)
setattr(current_module, leaf_name, new_leaf)
def get_model():
model = VisionTransformer(
class_token=False,
global_pool="avg",
img_size=256,
embed_dim=1280,
num_classes=1024,
depth=32,
num_heads=16
)
simple_swap(model)
return model
def train_step(inputs, label, model, optimizer, criterion):
with torch.autocast(device_type='cuda', dtype=torch.bfloat16):
with te.fp8_autocast(enabled=True):
outputs = model(inputs)
loss = criterion(outputs, label)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
The results of the TE experiments are captured below:
While the uncompiled TE FP8 model performs significantly better than our previous FP8 model, the compiled PyTorch FP8 model still provides the best results. Importantly, as of the time of this writing, TE FP8 modules do not support model compilation. Thus, applying torch.compile will result in “partial compilation”, i.e. it will include multiple graph breaks (every time FP8 is used).
We intentionally limited our tests to just the linear layers of our toy model. Unsurprisingly, applying the full power of TE to our model, as demonstrated in our previous post, would have resulted in a 72% boost (compared to our baseline experiment).
For a more detailed comparison between the TE and PyTorch-native FP8 operators, covering a wide range of matrix sizes, we recommend following this github issue.
Conclusions
Although still in its early days with clear room for improvement both in terms of API coverage and performance, we have succeeded in demonstrating some of the potential advantages of the PyTorch native FP8 support. First, the ability to explicitly declare and operate on FP8 tensors will enable developers much greater freedom in customizing FP8-based algorithms. Second, the built-in support for JIT-compilation facilitates greater potential for runtime optimization. A third advantage (not demonstrated here) is the ability to support a greater range of FP8-supporting devices. This is contrary to TE which is developed by NVIDIA and heavily tailored to their GPUs.
Summary
The ever-increasing size of AI models necessitates advanced techniques and algorithms for both reducing memory footprint and boosting runtime performance. Using the FP8 data type on dedicated HW accelerators offers the ability to achieve both. Although our focus has been on model training, the implications are no less important on model inference, where the time that it takes to load a large model into memory and run it, can have a decisive impact on a user’s experience.
The newly defined PyTorch-native FP8 data types and operators that we experimented with in this post, are certain to facilitate and accelerate the adoption of this important technology. We look forward to seeing how this native support evolves and matures.
For more tools and techniques for AI model optimization, be sure to check out some of our other posts.
PyTorch Native FP8 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.