An introduction to a methodology for creating production-ready, extensible & highly optimized AI workflows

Credit: Google Gemini, prompt by the Author
Intro
In the last decade, I carried with me a deep question in the back of my mind in every project I’ve worked on:
I wanted to know — is there an elegant way to build production-ready code in an iterative way? A codebase that is extensible, optimized, maintainable & reproducible?
And if so — where does this secret lie? Who owns the knowledge to this dark art?
I searched intensively for an answer over the course of many years — reading articles, watching tutorials and trying out different methodologies and frameworks. But I couldn’t find a satisfying answer. Every time I thought I was getting close to a solution, something was still missing.
After about 10 years of trial and error, with a focused effort in the last two years, I think I’ve finally found a satisfying answer to my long-standing quest. This post is the beginning of my journey of sharing what I’ve found.
My research has led me to identify 5 key pillars that form the foundation of what I call a hyper-optimized AI workflow. In the post I will shortly introduce each of them — giving you an overview of what’s to come.
I want to emphasize that each of the pillars that I will present is grounded in practical methods and tools, which I’ll elaborate on in future posts. If you’re already curious to see them in action, feel free to check out this video from Hamilton’s meetup where I present them live:
Note: Throughout this post and series, I’ll use the terms Artificial Intelligence (AI), Machine Learning (ML), and Data Science (DS) interchangeably. The concepts we’ll discuss apply equally to all these fields.
Now, let’s explore each pillar.
1 — Metric-Based Optimization
In every AI project there is a certain goal we want to achieve, and ideally — a set of metrics we want to optimize.
These metrics can include:
We can choose one metric as our “north star” or create an aggregate metric. For example:
There’s a wonderful short video by Andrew Ng. where here explains about the topic of a Single Number Evaluation Metric.
Once we have an agreed-upon metric to optimize and a set of constraints to meet, our goal is to build a workflow that maximizes this metric while satisfying our constraints.
2 — Interactive Developer Experience
In the world of Data Science and AI development — interactivity is key.
As AI Engineers (or whatever title we Data Scientists go by these days), we need to build code that works bug-free across different scenarios.
Unlike traditional software engineering, our role extends beyond writing code that “just” works. A significant aspect of our work involves examining the data and inspecting our models’ outputs and the results of various processing steps.
The most common environment for this kind of interactive exploration is Jupyter Notebooks.
Working within a notebook allows us to test different implementations, experiment with new APIs and inspect the intermediate results of our workflows and make decisions based on our observations. This is the core of the second pillar.
However, As much as we enjoy these benefits in our day-to-day work, notebooks can sometimes contain notoriously bad code that can only be executed in a non-trivial order.
In addition, some exploratory parts of the notebook might not be relevant for production settings, making it unclear how these can effectively be shipped to production.
3 — Production-Ready Code
“Production-Ready” can mean different things in different contexts. For one organization, it might mean serving results within a specified time frame. For another, it could refer to the service’s uptime (SLA). And yet for another, it might mean the code, model, or workflow has undergone sufficient testing to ensure reliability.
These are all important aspects of shipping reliable products, and the specific requirements may vary from place to place. Since my exploration is focused on the “meta” aspect of building AI workflows, I want to discuss a common denominator across these definitions: wrapping our workflow as a serviceable API and deploying it to an environment where it can be queried by external applications or users.
This means we need to have a way to abstract the complexity of our codebase into a clearly defined interface that can be used across various use-cases. Let’s consider an example:
Imagine a complex RAG (Retrieval-Augmented Generation) system over PDF files that we’ve developed. It may contain 10 different parts, each consisting of hundreds of lines of code.
However, we can still wrap them into a simple API with just two main functions:
This abstraction allows users to:
By providing this clean interface, we’ve effectively hidden the complexities and implementation details of our workflow.
Having a systematic way to convert arbitrarily complex workflows into deployable APIs is our third pillar.
In addition, we would ideally want to establish a methodology that ensures that our iterative, daily work stays in sync with our production code.
This means if we make a change to our workflow — fixing a bug, adding a new implementation, or even tweaking a configuration — we should be able to deploy these changes to our production environment with just a click of a button.
4 — Modular & Extensible Code
Another crucial aspect of our methodology is maintaining a Modular & Extensible codebase.
This means that we can add new implementations and test them against existing ones that occupy the same logical step without modifying our existing code or overwriting other configurations.
This approach aligns with the open-closed principle, where our code is open for extension but closed for modification. It allows us to:
Let’s look at a toy example:
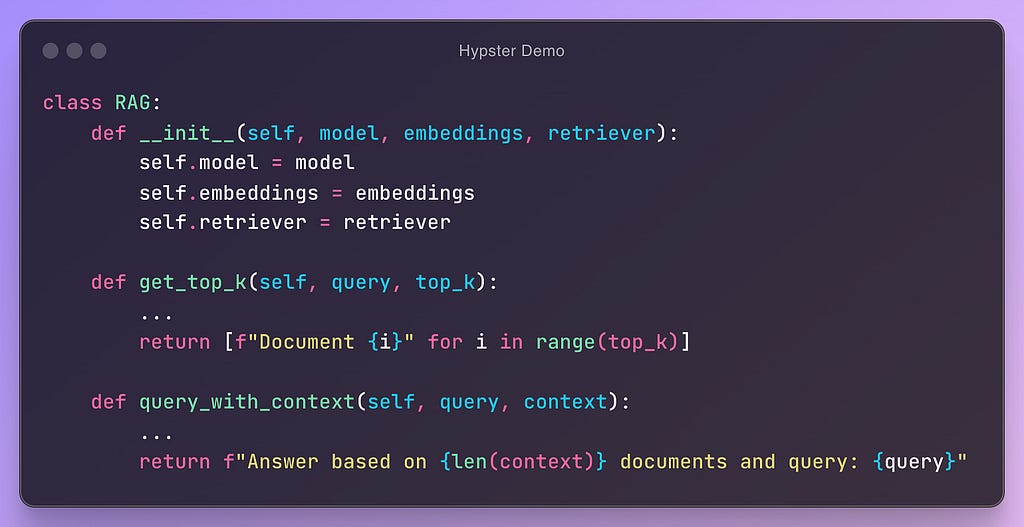
Image by the Author
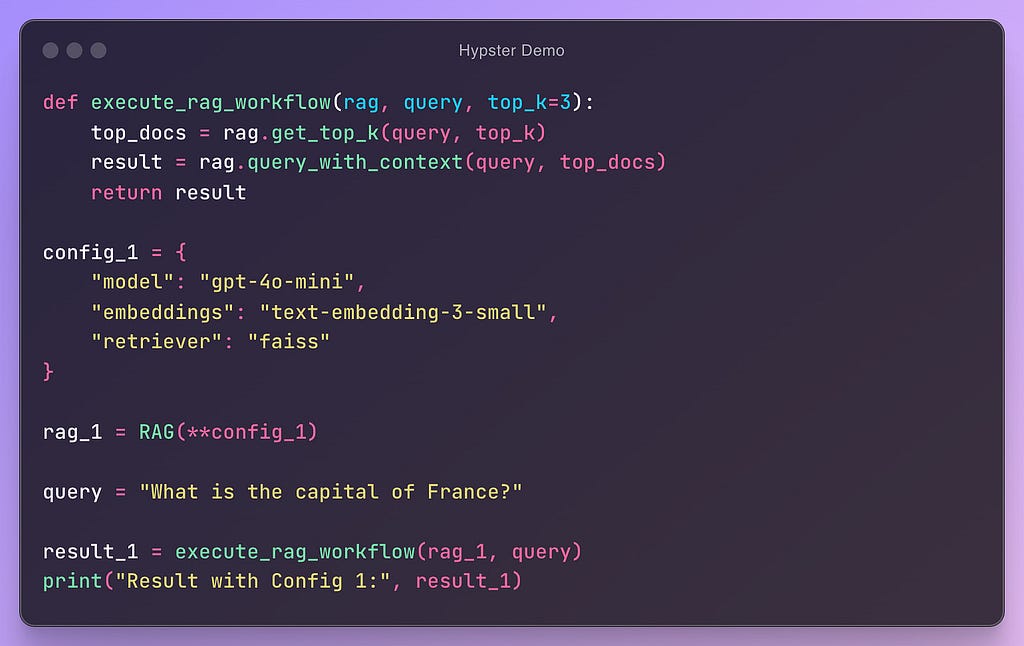
Image by the Author
In this example, we can see a (pseudo) code that is modular and configurable. In this way, we can easily add new configurations and test their performance:
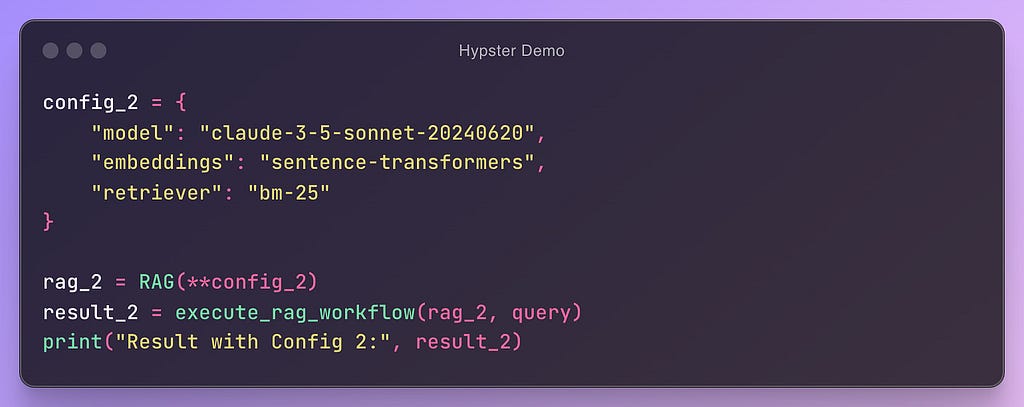
Image by the Author
Once our code consists of multiple competing implementations & configurations, we enter a state that I like to call a “superposition of workflows”. In this state we can instantiate and execute a workflow using a specific set of configurations.
5 — Hierarchical & Visual Structures
What if we take modularity and extensibility a step further? What if we apply this approach to entire sections of our workflow?
So now, instead of configuring this LLM or that retriever, we can configure our whole preprocessing, training, or evaluation steps.
Let’s look at an example:
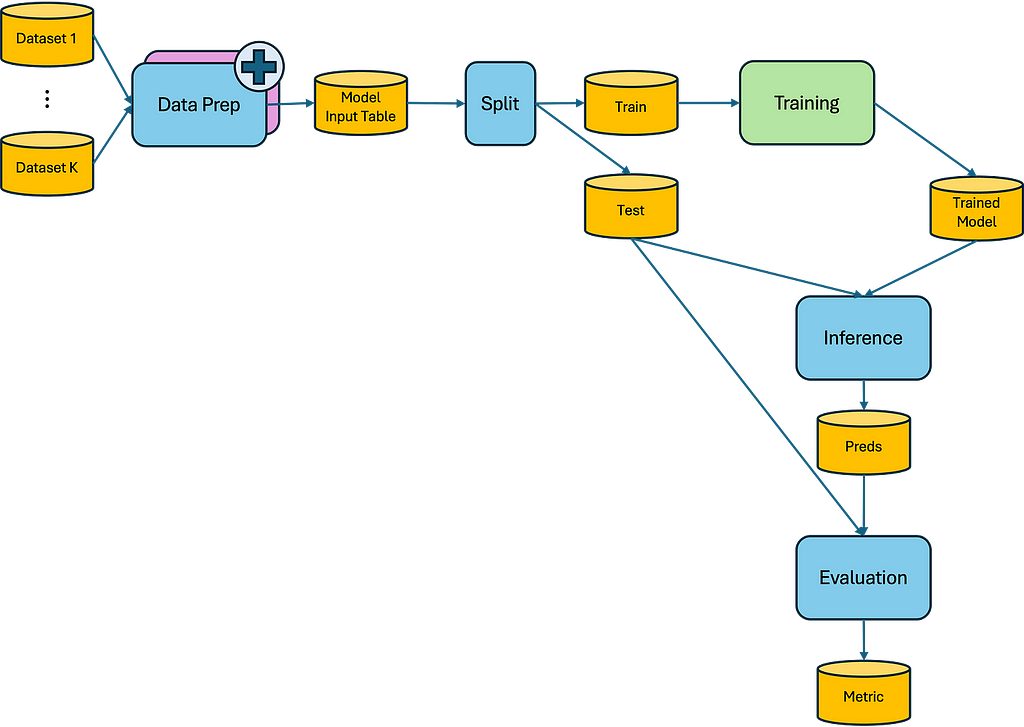
Image by the Author
Here we see our entire ML workflow. Now, let’s add a new Data Prep implementation and zoom into it:
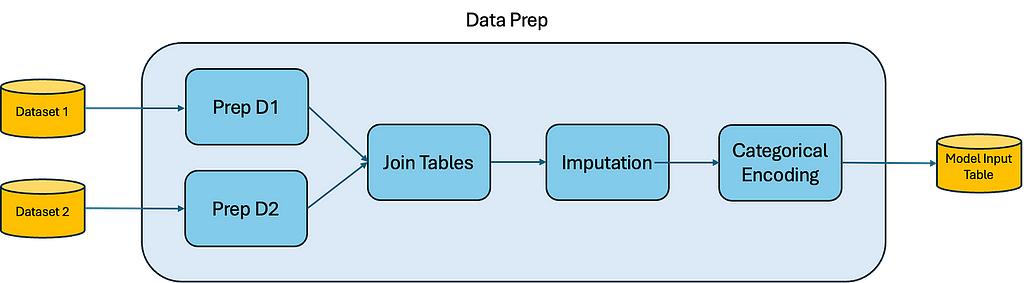
Image by the Author
When we work in this hierarchical and visual way, we can select a section of our workflow to improve and add a new implementation with the same input/output interface as the existing one.
We can then “zoom in” to that specific section, focusing solely on it without worrying about the rest of the project. Once we’re satisfied with our implementation — we can start testing it out alongside other various configurations in our workflow.
This approach unlocks several benefits:
These are the 5 pillars that I’ve found to hold the foundation to a “hyper-optimized AI workflow”:
In the upcoming blog posts, I’ll dive deeper into each of these pillars, providing more detailed insights, practical examples, and tools to help you implement these concepts in your own AI projects.
Specifically, I intend to introduce the methodology and tools I’ve built on top of DAGWorks Inc* Hamilton framework and my own packages: Hypster and HyperNodes (still in its early days).
Stay tuned for more!
*I am not affiliated with or employed by DAGWorks Inc.

5 Pillars for a Hyper-Optimized AI Workflow was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Credit: Google Gemini, prompt by the Author
Intro
In the last decade, I carried with me a deep question in the back of my mind in every project I’ve worked on:
How (the hell) am I supposed to structure and develop my AI & ML projects?
I wanted to know — is there an elegant way to build production-ready code in an iterative way? A codebase that is extensible, optimized, maintainable & reproducible?
And if so — where does this secret lie? Who owns the knowledge to this dark art?
I searched intensively for an answer over the course of many years — reading articles, watching tutorials and trying out different methodologies and frameworks. But I couldn’t find a satisfying answer. Every time I thought I was getting close to a solution, something was still missing.
After about 10 years of trial and error, with a focused effort in the last two years, I think I’ve finally found a satisfying answer to my long-standing quest. This post is the beginning of my journey of sharing what I’ve found.
My research has led me to identify 5 key pillars that form the foundation of what I call a hyper-optimized AI workflow. In the post I will shortly introduce each of them — giving you an overview of what’s to come.
I want to emphasize that each of the pillars that I will present is grounded in practical methods and tools, which I’ll elaborate on in future posts. If you’re already curious to see them in action, feel free to check out this video from Hamilton’s meetup where I present them live:
Note: Throughout this post and series, I’ll use the terms Artificial Intelligence (AI), Machine Learning (ML), and Data Science (DS) interchangeably. The concepts we’ll discuss apply equally to all these fields.
Now, let’s explore each pillar.
1 — Metric-Based Optimization
In every AI project there is a certain goal we want to achieve, and ideally — a set of metrics we want to optimize.
These metrics can include:
- Predictive quality metrics: Accuracy, F1-Score, Recall, Precision, etc…
- Cost metrics: Actual $ amount, FLOPS, Size in MB, etc…
- Performance metrics: Training speed, inference speed, etc…
We can choose one metric as our “north star” or create an aggregate metric. For example:
- 0.7 × F1-Score + 0.3 × (1 / Inference Time in ms)
- 0.6 × AUC-ROC + 0.2 × (1 / Training Time in hours) + 0.2 × (1 / Cloud Compute Cost in $)
There’s a wonderful short video by Andrew Ng. where here explains about the topic of a Single Number Evaluation Metric.
Once we have an agreed-upon metric to optimize and a set of constraints to meet, our goal is to build a workflow that maximizes this metric while satisfying our constraints.
2 — Interactive Developer Experience
In the world of Data Science and AI development — interactivity is key.
As AI Engineers (or whatever title we Data Scientists go by these days), we need to build code that works bug-free across different scenarios.
Unlike traditional software engineering, our role extends beyond writing code that “just” works. A significant aspect of our work involves examining the data and inspecting our models’ outputs and the results of various processing steps.
The most common environment for this kind of interactive exploration is Jupyter Notebooks.
Working within a notebook allows us to test different implementations, experiment with new APIs and inspect the intermediate results of our workflows and make decisions based on our observations. This is the core of the second pillar.
However, As much as we enjoy these benefits in our day-to-day work, notebooks can sometimes contain notoriously bad code that can only be executed in a non-trivial order.
In addition, some exploratory parts of the notebook might not be relevant for production settings, making it unclear how these can effectively be shipped to production.
3 — Production-Ready Code
“Production-Ready” can mean different things in different contexts. For one organization, it might mean serving results within a specified time frame. For another, it could refer to the service’s uptime (SLA). And yet for another, it might mean the code, model, or workflow has undergone sufficient testing to ensure reliability.
These are all important aspects of shipping reliable products, and the specific requirements may vary from place to place. Since my exploration is focused on the “meta” aspect of building AI workflows, I want to discuss a common denominator across these definitions: wrapping our workflow as a serviceable API and deploying it to an environment where it can be queried by external applications or users.
This means we need to have a way to abstract the complexity of our codebase into a clearly defined interface that can be used across various use-cases. Let’s consider an example:
Imagine a complex RAG (Retrieval-Augmented Generation) system over PDF files that we’ve developed. It may contain 10 different parts, each consisting of hundreds of lines of code.
However, we can still wrap them into a simple API with just two main functions:
- upload_document(file: PDF) -> document_id: str
- query_document(document_id: str, query: str, output_format: str) -> response: str
This abstraction allows users to:
- Upload a PDF document and receive a unique identifier.
- Ask questions about the document using natural language.
- Specify the desired format for the response (e.g., markdown, JSON, Pandas Dataframe).
By providing this clean interface, we’ve effectively hidden the complexities and implementation details of our workflow.
Having a systematic way to convert arbitrarily complex workflows into deployable APIs is our third pillar.
In addition, we would ideally want to establish a methodology that ensures that our iterative, daily work stays in sync with our production code.
This means if we make a change to our workflow — fixing a bug, adding a new implementation, or even tweaking a configuration — we should be able to deploy these changes to our production environment with just a click of a button.
4 — Modular & Extensible Code
Another crucial aspect of our methodology is maintaining a Modular & Extensible codebase.
This means that we can add new implementations and test them against existing ones that occupy the same logical step without modifying our existing code or overwriting other configurations.
This approach aligns with the open-closed principle, where our code is open for extension but closed for modification. It allows us to:
- Introduce new implementations alongside existing ones
- Easily compare the performance of different approaches
- Maintain the integrity of our current working solutions
- Extend our workflow’s capabilities without risking the stability of the whole system
Let’s look at a toy example:
Image by the Author
Image by the Author
In this example, we can see a (pseudo) code that is modular and configurable. In this way, we can easily add new configurations and test their performance:
Image by the Author
Once our code consists of multiple competing implementations & configurations, we enter a state that I like to call a “superposition of workflows”. In this state we can instantiate and execute a workflow using a specific set of configurations.
5 — Hierarchical & Visual Structures
What if we take modularity and extensibility a step further? What if we apply this approach to entire sections of our workflow?
So now, instead of configuring this LLM or that retriever, we can configure our whole preprocessing, training, or evaluation steps.
Let’s look at an example:
Image by the Author
Here we see our entire ML workflow. Now, let’s add a new Data Prep implementation and zoom into it:
Image by the Author
When we work in this hierarchical and visual way, we can select a section of our workflow to improve and add a new implementation with the same input/output interface as the existing one.
We can then “zoom in” to that specific section, focusing solely on it without worrying about the rest of the project. Once we’re satisfied with our implementation — we can start testing it out alongside other various configurations in our workflow.
This approach unlocks several benefits:
- Reduced mental overload: Focus on one section at a time, providing clarity and reducing complexity in decision-making.
- Easier collaboration: A modular structure simplifies task delegation to teammates or AI assistants, with clear interfaces for each component.
- Reusability: These encapsulated implementations can be utilized in different projects, potentially without modification to their source code.
- Self-documentation: Visualizing entire workflows and their components makes it easier to understand the project’s structure and logic without diving into unnecessary details.
These are the 5 pillars that I’ve found to hold the foundation to a “hyper-optimized AI workflow”:
- Metric-Based Optimization: Define and optimize clear, project-specific metrics to guide decision-making and workflow improvements.
- Interactive Developer Experience: Utilize tools for iterative coding & data inspection like Jupyter Notebooks.
- Production-Ready Code: Wrap complete workflows into deployable APIs and sync development and production code.
- Modular & Extensible Code: Structure code to easily add, swap, and test different implementations.
- Hierarchical & Visual Structures: Organize projects into visual, hierarchical components that can be independently developed and easily understood at various levels of abstraction.
In the upcoming blog posts, I’ll dive deeper into each of these pillars, providing more detailed insights, practical examples, and tools to help you implement these concepts in your own AI projects.
Specifically, I intend to introduce the methodology and tools I’ve built on top of DAGWorks Inc* Hamilton framework and my own packages: Hypster and HyperNodes (still in its early days).
Stay tuned for more!
*I am not affiliated with or employed by DAGWorks Inc.
5 Pillars for a Hyper-Optimized AI Workflow was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.