Comprehensive Steps for Building LLM-Native Apps: From Initial Idea to Experimentation, Evaluation, and Productization
Large Language Models (LLMs) are swiftly becoming a cornerstone of modern AI. Yet, there are no established best practices, and often, pioneers are left with no clear roadmap, needing to reinvent the wheel or getting stuck.
Over the past two years, I’ve helped organizations leverage LLMs to build innovative applications. Through this experience, I developed a battle-tested method for creating innovative solutions (shaped by insights from the LLM.org.il community), which I’ll share in this article.
This guide provides a clear roadmap for navigating the complex landscape of LLM-native development. You’ll learn how to move from ideation to experimentation, evaluation, and productization, unlocking your potential to create groundbreaking applications.

(Created with Dall-E3)
Why a Standardized Process is Essential
The LLM space is so dynamic that sometimes, we hear about new groundbreaking innovations day after day. This is also exhilarating but chaotic — you may find yourself lost in the process, wondering what to do or how to bring your novel idea to life.
Long story short, if you are an AI Innovator (a manager or a practitioner) who wants to build LLM-native apps effectively, this is for you.
Implementing a standardized process helps kick off new projects and offers several key benefits:
Unlike any other established role in Software R&D, LLM-native development absolutely requires a new role: the LLM Engineer or the AI Engineer.
The LLM Engineer is a unique hybrid creature that involves skills from different (established) roles:
While writing this, LLM Engineering is still brand new, and hiring can be very challenging. It can be a good idea to look for candidates with a background in backend/data engineering or data science.
Software Engineers might expect a smoother transition, as the experimentation process is much more "engineer-y" and not that "scientific" (compared to traditional data science work). That being said, I've seen many Data Scientists do this transition as well. As long as you're okay with the fact that you'll have to embrace new soft skills, you're on the right path!
The Key Elements of LLM-Native Development
Unlike classical backend apps (such as CRUD), there are no step-by-step recipes here. Like everything else in "AI," LLM-native apps require a research and experimentation mindset.
To tame the beast, you must divide and conquer by splitting your work into smaller experiments, trying some of them, and selecting the most promising experiment.
I can't emphasize enough the importance of the research mindset. That means you might invest the time to explore a research vector and find out that it's "not possible," "not good enough," or "not worth it." That's totally okay — it means you're on the right track.

Experimenting with LLMs is the only way to build LLM-native apps (and avoid the snakes in the way) (Created with Dall-E3)
Embracing Experimentation: The Heart of the Process
Sometimes, your "experiment" will fail, then you slightly pivot your work, and this other experiment succeeded much better.
That's precisely why, before designing our endgame solution, we must start simple and hedge our risks.
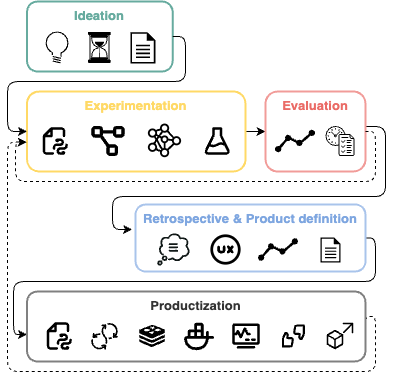
LLM-Native app development lifecycle (Image by author)
To implement the experiment-oriented process well, we must make an informed decision on approaching and constructing these experiments:
Starting Lean: The Bottom-Up Approach
While many early adopters quickly jump into" State-Of-The-Art" multichain agentic systems with full-fledged Langchain or something similar, I found "The Bottom-Up approach" often yields better results.
Start lean, very lean, embracing the “one prompt to rule them all” philosophy. Although this strategy might seem unconventional and will likely produce bad results at first, it establishes a baseline for your system.
From there, continuously iterate and refine your prompts, employing prompt engineering techniques to optimize outcomes. As you identify weaknesses in your lean solution, split the process by adding branches to address those shortcomings.
While designing each "leaf" of my LLM workflow graph, or LLM-native architecture, I follow The Magic Triangle³ to determine where and when to cut the branches, split them, or thicken the roots (by using prompt engineering techniques) and squeeze more of the lemon.
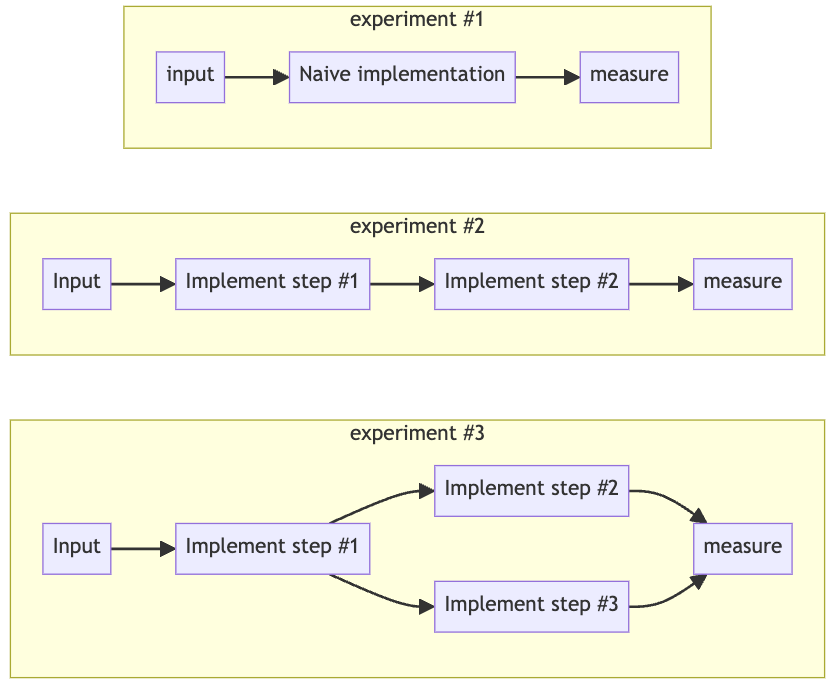
An illustration for the Bottom-Up approach (Image by author)
For example, to implement "Native language SQL querying" with the bottom-up approach, we'll start by naively sending the schemas to the LLM and ask it to generate a query.
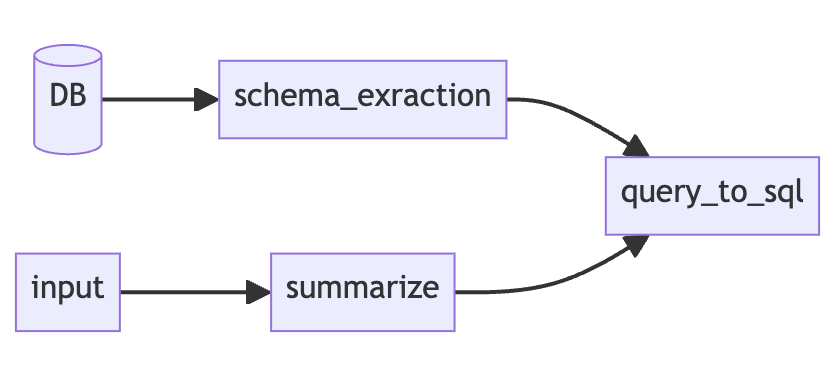
A Bottom-Up approach example (Image by author)
Usually, this does not contradict the "top-down approach" but serves as another step before it. This allows us to show quick wins and attract more project investment.
The Big Picture Upfront: The Top-Down Strategy
The Top-Down approach recognizes it and starts by designing the LLM-native architecture from day one and implementing its different steps/chains from the beginning.
This way, you can test your workflow architecture as a whole and squeeze the whole lemon instead of refining each leaf separately.
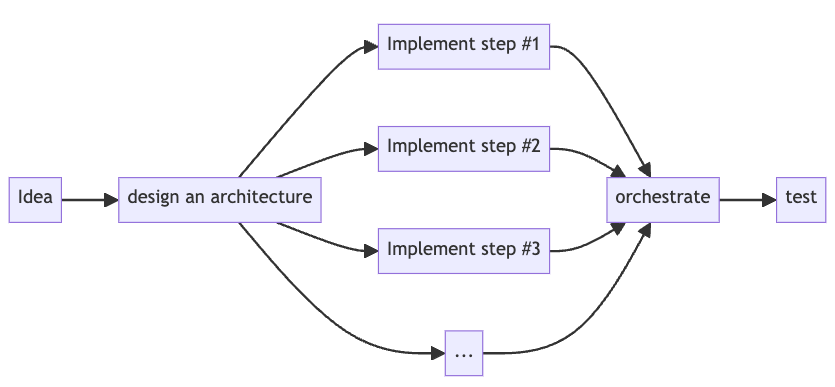
Top-down approach process: design your architecture once, implement, test & measure (Image by author)
For example, to implement "Native language SQL querying" with the top-down approach, we'll start designing the architecture before even starting to code and then jump to the full implementation:
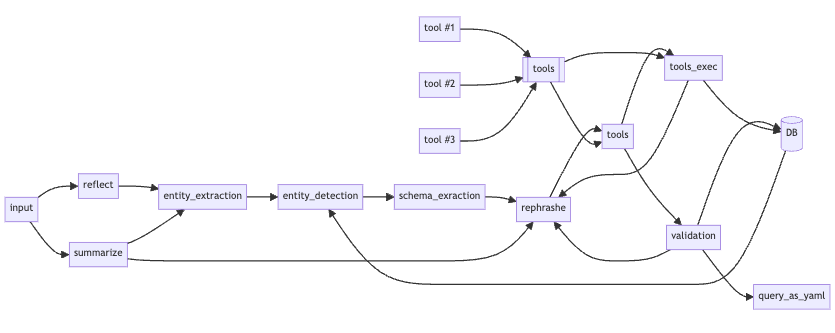
An example of the Top-Down approach (Image by author)
Finding the Right Balance
When you start experimenting with LLMs, you'll probably start at one of the extremes (overcomplicated top-down or super simple one-shot). In reality, there's no such a winner.
Ideally — you'll define a good SoP¹ and model an expert before coding and experimenting with the model. In reality, modeling is very hard; sometimes, you may not have access to such an expert.
I found it challenging to land on a good architecture/SoP¹ at the first shot, so it's worth experimenting lightly before jumping to the big guns. However, it doesn't mean that everything has to be too lean. If you already have a prior understanding that something MUST be broken into smaller pieces — do that.
In any case, you should leverage The Magic Triangle³ paradigm and model the manual process correctly while designing your solution.
Optimizing Your Solution: Squeezing the Lemon
During the experimentation phase, we continuously squeeze the lemon and add more "layers of complexity":

Squeezing the AI Lemon (Created with Dall-E3)
The Anatomy of an LLM Experiment
Personally, I prefer to start lean with a simple Jupyter Notebook using Python, Pydantic, and Jinja2:
In a broader scope, you can use different tools such as openai-streaming to easily utilize streaming (and tools), LiteLLM to have a standardized LLM SDK across different providers, or vLLM to serve open-source LLMs.
Ensuring Quality with Sanity Tests and Evaluations
A sanity test evaluates the quality of your project and ensures that you're not degrading a certain success rate baseline you defined.
Think of your solution/prompts as a short blanket — if you stretch it too much, it might suddenly not cover some use cases it used to cover.
To do that, define a set of cases you have already covered successfully and ensure you keep it that way (or at least it's worth it). Thinking of it like a table-driven test might help.
Evaluating the success of a "generative" solution(e.g., writing text) is much more complex than using LLMs for other tasks (such as categorization, entity extraction, etc.). For these kinds of tasks, you might want to involve a smarter model (such as GPT4, Claude Opus, or LLAMA3–70B) to act as a "judge."
It might also be a good idea to try and make the output include "deterministic parts" before the "generative" output, as these kinds of output are easier to test:
cities:
- New York
- Tel Aviv
vibes:
- vibrant
- energetic
- youthful
target_audience:
age_min: 18
age_max: 30
gender: both
attributes:
- adventurous
- outgoing
- culturally curious
# ignore the above, only show the user the `text` attr.
text: Both New York and Tel Aviv buzz with energy, offering endless activities, nightlife, and cultural experiences perfect for young, adventurous tourists.
There are a few cutting-edge,🤩🤩 promising solutions worth investigating. I found them especially relevant when evaluating RAG-based solutions: take a look at DeepChecks, Ragas, or ArizeAI.
Making Informed Decisions: The Importance of Retrospectives
After each major/time-framed experiment or milestone, we should stop and make an informed decision on how and if to proceed with this approach.
At this point, your experiment will have a clear success rate baseline, and you'll have an idea of what needs to be improved.
This is also a good point to start discussing the productization implications of this solution and start with the "product work":
Suppose the baseline we achieved is “good enough,” and we believe we can mitigate the problems we raised. In that case, we will continue investing in and improving the project while ensuring it never degrades and using the sanity tests.

(Created with Dall-E3)
From Experiment to Product: Bringing Your Solution to Life
Last but not least, we have to productize our work. Like any other production-grade solution, we must implement production engineering concepts like logging, monitoring, dependency management, containerization, caching, etc.
This is a huge world, but luckily, we can borrow many mechanisms from classical production engineering and even adopt many of the existing tools.
That being said, it's important to take extra care of the nuances involving LLM-native apps:
This might be the end of the article, but certainly not the end of our work. LLM-native development is an iterative process that covers more use cases, challenges, and features and continuously improves our LLM-native product.
As you continue your AI development journey, stay agile, experiment fearlessly, and keep the end-user in mind. Share your experiences and insights with the community, and together, we can push the boundaries of what's possible with LLM-native apps. Keep exploring, learning, and building — the possibilities are endless.
I hope this guide has been a valuable companion on your LLM-native development journey! I'd love to hear your story — share your triumphs and challenges in the comments below. 💬
If you find this article helpful, please give it a few claps 👏 on Medium and share it with your fellow AI enthusiasts. Your support means the world to me! 🌍
Let's keep the conversation going — feel free to reach out via email or connect on LinkedIn 🤝
Special thanks to Yonatan V. Levin, Gal Peretz, Philip Tannor, Ori Cohen, Nadav, Ben Huberman, Carmel Barniv, Omri Allouche, and Liron Izhaki Allerhand for insights, feedback, and editing notes.
¹SoP- Standard operating procedure, a concept borrowed from The Magic Triangle³
²YAML- I found that using YAML to structure your output works much better with LLMs. Why? My theory is that it reduces the non-relevant tokens and behaves much like the native language. This article dives deep into this subject.
³The Magic Triangle- A blueprint for LLM-native development; stay tuned, and follow me to read the blueprint when it gets published.

Building LLM Apps: A Clear Step-By-Step Guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Large Language Models (LLMs) are swiftly becoming a cornerstone of modern AI. Yet, there are no established best practices, and often, pioneers are left with no clear roadmap, needing to reinvent the wheel or getting stuck.
Over the past two years, I’ve helped organizations leverage LLMs to build innovative applications. Through this experience, I developed a battle-tested method for creating innovative solutions (shaped by insights from the LLM.org.il community), which I’ll share in this article.
This guide provides a clear roadmap for navigating the complex landscape of LLM-native development. You’ll learn how to move from ideation to experimentation, evaluation, and productization, unlocking your potential to create groundbreaking applications.
(Created with Dall-E3)
Why a Standardized Process is Essential
The LLM space is so dynamic that sometimes, we hear about new groundbreaking innovations day after day. This is also exhilarating but chaotic — you may find yourself lost in the process, wondering what to do or how to bring your novel idea to life.
Long story short, if you are an AI Innovator (a manager or a practitioner) who wants to build LLM-native apps effectively, this is for you.
Implementing a standardized process helps kick off new projects and offers several key benefits:
- Standardize the process — A standardized process helps align the team members and ensures a smooth new member onboarding process (especially in this chaos).
- Defines clear milestones — A straightforward way to track your work, measure it, and make sure you're on the right path
- Identify decision points — LLM-native development is full of unknowns and "small experimentation" [see below]. Clear decision points make it easy to mitigate our risk and always stay lean with our development effort.
Unlike any other established role in Software R&D, LLM-native development absolutely requires a new role: the LLM Engineer or the AI Engineer.
The LLM Engineer is a unique hybrid creature that involves skills from different (established) roles:
- Software Engineering skills—Like most SWEs, most of the work involves putting the Lego pieces together and gluing everything together.
- Research skills —Properly understanding the LLM-native experimental nature is essential. While building "cool demo apps" is pretty accessible, the distance between a "cool demo" and a practical solution requires experimentation and agility.
- Deep business/product understanding — Due to the fragility of the models, it's essential to understand the business goals and procedures rather than sticking to the architecture we defined. The ability to model a manual process is a golden skill for LLM Engineers.
While writing this, LLM Engineering is still brand new, and hiring can be very challenging. It can be a good idea to look for candidates with a background in backend/data engineering or data science.
Software Engineers might expect a smoother transition, as the experimentation process is much more "engineer-y" and not that "scientific" (compared to traditional data science work). That being said, I've seen many Data Scientists do this transition as well. As long as you're okay with the fact that you'll have to embrace new soft skills, you're on the right path!
The Key Elements of LLM-Native Development
Unlike classical backend apps (such as CRUD), there are no step-by-step recipes here. Like everything else in "AI," LLM-native apps require a research and experimentation mindset.
To tame the beast, you must divide and conquer by splitting your work into smaller experiments, trying some of them, and selecting the most promising experiment.
I can't emphasize enough the importance of the research mindset. That means you might invest the time to explore a research vector and find out that it's "not possible," "not good enough," or "not worth it." That's totally okay — it means you're on the right track.
Experimenting with LLMs is the only way to build LLM-native apps (and avoid the snakes in the way) (Created with Dall-E3)
Embracing Experimentation: The Heart of the Process
Sometimes, your "experiment" will fail, then you slightly pivot your work, and this other experiment succeeded much better.
That's precisely why, before designing our endgame solution, we must start simple and hedge our risks.
- Define a "budget" or timeframe. Let's see what we can do in X weeks and then decide how or if to continue. Usually, 2–4 weeks to understand basic PoC will be sufficient. If it looks promising — continue investing resources to improve it.
- Experiment—Whether you choose a bottom-up or top-down approach for your experimentation phase, your goal is to maximize the result succession rate. By the end of the first experimentation iteration, you should have some PoC (that stakeholders can play with) and a baseline you achieved.
- Retrospective — By the end of our research phase, we can understand the feasibility, limitations, and cost of building such an app. This helps us decide whether to productionize it and how to design the final product and its UX.
- Productization — Develop a production-ready version of your project and integrate it with the rest of your solution by following standard SWE best practices and implementing a feedback and data collection mechanism.
LLM-Native app development lifecycle (Image by author)
To implement the experiment-oriented process well, we must make an informed decision on approaching and constructing these experiments:
Starting Lean: The Bottom-Up Approach
While many early adopters quickly jump into" State-Of-The-Art" multichain agentic systems with full-fledged Langchain or something similar, I found "The Bottom-Up approach" often yields better results.
Start lean, very lean, embracing the “one prompt to rule them all” philosophy. Although this strategy might seem unconventional and will likely produce bad results at first, it establishes a baseline for your system.
From there, continuously iterate and refine your prompts, employing prompt engineering techniques to optimize outcomes. As you identify weaknesses in your lean solution, split the process by adding branches to address those shortcomings.
While designing each "leaf" of my LLM workflow graph, or LLM-native architecture, I follow The Magic Triangle³ to determine where and when to cut the branches, split them, or thicken the roots (by using prompt engineering techniques) and squeeze more of the lemon.
An illustration for the Bottom-Up approach (Image by author)
For example, to implement "Native language SQL querying" with the bottom-up approach, we'll start by naively sending the schemas to the LLM and ask it to generate a query.
A Bottom-Up approach example (Image by author)
Usually, this does not contradict the "top-down approach" but serves as another step before it. This allows us to show quick wins and attract more project investment.
The Big Picture Upfront: The Top-Down Strategy
“We know that LLM workflow is not easy, and to achieve our goal, we'll probably end up with some workflow or LLM-native architecture.”
The Top-Down approach recognizes it and starts by designing the LLM-native architecture from day one and implementing its different steps/chains from the beginning.
This way, you can test your workflow architecture as a whole and squeeze the whole lemon instead of refining each leaf separately.
Top-down approach process: design your architecture once, implement, test & measure (Image by author)
For example, to implement "Native language SQL querying" with the top-down approach, we'll start designing the architecture before even starting to code and then jump to the full implementation:
An example of the Top-Down approach (Image by author)
Finding the Right Balance
When you start experimenting with LLMs, you'll probably start at one of the extremes (overcomplicated top-down or super simple one-shot). In reality, there's no such a winner.
Ideally — you'll define a good SoP¹ and model an expert before coding and experimenting with the model. In reality, modeling is very hard; sometimes, you may not have access to such an expert.
I found it challenging to land on a good architecture/SoP¹ at the first shot, so it's worth experimenting lightly before jumping to the big guns. However, it doesn't mean that everything has to be too lean. If you already have a prior understanding that something MUST be broken into smaller pieces — do that.
In any case, you should leverage The Magic Triangle³ paradigm and model the manual process correctly while designing your solution.
Optimizing Your Solution: Squeezing the Lemon
During the experimentation phase, we continuously squeeze the lemon and add more "layers of complexity":
- Prompt engineering techniques — Like Few Shots, Role assignment, or even Dynamic few-shot
- Expanding the Context Window from simple variable information to complex RAG flows can help improve the results.
- Experimenting with different models — Different models perform differently on different tasks. Also, the large LLMs are often not very cost-effective, and it's worth trying more task-specific models.
- Prompt dieting — I learned that putting the SOP¹ (specifically, the prompt and the requested output) through a "diet" usually improves latency.
By reducing the prompt size and the steps the model needs to go through, we can reduce both the input and output the model needs to generate. You'll be surprised, but prompt dieting can sometimes even improve the quality!
Be aware that the diet might also cause quality degradation, so it's important to set up a sanity test before doing so. - Splitting the process into smaller steps can also be very beneficial and make optimizing a subprocess of your SOP¹ easier and feasible.
Be aware that this might increase the solution's complexity or damage the performance (e.g., increase the number of tokens processed). To mitigate this, aim for concise prompts and smaller models.
As a rule of thumb, it's usually a good idea to split when a dramatic change of the System Prompt yields much better results for this part of the SOP¹ flow.
Squeezing the AI Lemon (Created with Dall-E3)
The Anatomy of an LLM Experiment
Personally, I prefer to start lean with a simple Jupyter Notebook using Python, Pydantic, and Jinja2:
- Use Pydantic to define my outputs' schema from the model.
- Write the prompt template with Jinja2.
- Define a structured output format (in YAML²). This will ensure the model follows the "thinking steps" and is guided by my SOP.
- Ensure this output with your Pydantic validations; if needed — retry.
- Stabilize your work — structure your code into functional units with Python files and packages.
In a broader scope, you can use different tools such as openai-streaming to easily utilize streaming (and tools), LiteLLM to have a standardized LLM SDK across different providers, or vLLM to serve open-source LLMs.
Ensuring Quality with Sanity Tests and Evaluations
A sanity test evaluates the quality of your project and ensures that you're not degrading a certain success rate baseline you defined.
Think of your solution/prompts as a short blanket — if you stretch it too much, it might suddenly not cover some use cases it used to cover.
To do that, define a set of cases you have already covered successfully and ensure you keep it that way (or at least it's worth it). Thinking of it like a table-driven test might help.
Evaluating the success of a "generative" solution(e.g., writing text) is much more complex than using LLMs for other tasks (such as categorization, entity extraction, etc.). For these kinds of tasks, you might want to involve a smarter model (such as GPT4, Claude Opus, or LLAMA3–70B) to act as a "judge."
It might also be a good idea to try and make the output include "deterministic parts" before the "generative" output, as these kinds of output are easier to test:
cities:
- New York
- Tel Aviv
vibes:
- vibrant
- energetic
- youthful
target_audience:
age_min: 18
age_max: 30
gender: both
attributes:
- adventurous
- outgoing
- culturally curious
# ignore the above, only show the user the `text` attr.
text: Both New York and Tel Aviv buzz with energy, offering endless activities, nightlife, and cultural experiences perfect for young, adventurous tourists.
There are a few cutting-edge,🤩🤩 promising solutions worth investigating. I found them especially relevant when evaluating RAG-based solutions: take a look at DeepChecks, Ragas, or ArizeAI.
Making Informed Decisions: The Importance of Retrospectives
After each major/time-framed experiment or milestone, we should stop and make an informed decision on how and if to proceed with this approach.
At this point, your experiment will have a clear success rate baseline, and you'll have an idea of what needs to be improved.
This is also a good point to start discussing the productization implications of this solution and start with the "product work":
- What will this look like within the product?
- What are the limitations/challenges? How would you mitigate them?
- What’s your current latency? Is it good enough?
- What should the UX be? Which UI hacks can you use? Can streaming help?
- What's the estimated spending on tokens? Can we use smaller models to reduce spending?
- What are priorities? Is any of the challenges a showstopper?
Suppose the baseline we achieved is “good enough,” and we believe we can mitigate the problems we raised. In that case, we will continue investing in and improving the project while ensuring it never degrades and using the sanity tests.
(Created with Dall-E3)
From Experiment to Product: Bringing Your Solution to Life
Last but not least, we have to productize our work. Like any other production-grade solution, we must implement production engineering concepts like logging, monitoring, dependency management, containerization, caching, etc.
This is a huge world, but luckily, we can borrow many mechanisms from classical production engineering and even adopt many of the existing tools.
That being said, it's important to take extra care of the nuances involving LLM-native apps:
- Feedback loop — How do we measure success? Is it simply a "thumb up/down" mechanism or something more sophisticated that considers the adoption of our solution?
It is also important to collect this data; down the road, this can help us redefine our sanity "baseline" or fine-tune our results with dynamic-few shots or fine-tune the model. - Caching — Unlike traditional SWE, caching can be very challenging when we involve a generative aspect in our solution. To mitigate it, explore the option to cache similar results(e.g., using RAG) and/or reduce the generative output (by having a strict output schema)
- Cost tracking — Many companies find it very tempting to start with a "strong model" (such as GPT-4 or Opus) however - in production, the costs can quickly rise. Avoid being surprised on the final bill, and make sure to measure the input/output tokens and keep track of your workflow impact (without these practices — good luck profiling it later on)
- Debuggability and tracing — Ensure you have set up the right tools to track a "buggy" input and track it throughout the process. This usually involves retaining the user input for later investigation and setting up a tracing system. Remember: "Unlike transitional software, AI fails silently!"
This might be the end of the article, but certainly not the end of our work. LLM-native development is an iterative process that covers more use cases, challenges, and features and continuously improves our LLM-native product.
As you continue your AI development journey, stay agile, experiment fearlessly, and keep the end-user in mind. Share your experiences and insights with the community, and together, we can push the boundaries of what's possible with LLM-native apps. Keep exploring, learning, and building — the possibilities are endless.
I hope this guide has been a valuable companion on your LLM-native development journey! I'd love to hear your story — share your triumphs and challenges in the comments below. 💬
If you find this article helpful, please give it a few claps 👏 on Medium and share it with your fellow AI enthusiasts. Your support means the world to me! 🌍
Let's keep the conversation going — feel free to reach out via email or connect on LinkedIn 🤝
Special thanks to Yonatan V. Levin, Gal Peretz, Philip Tannor, Ori Cohen, Nadav, Ben Huberman, Carmel Barniv, Omri Allouche, and Liron Izhaki Allerhand for insights, feedback, and editing notes.
¹SoP- Standard operating procedure, a concept borrowed from The Magic Triangle³
²YAML- I found that using YAML to structure your output works much better with LLMs. Why? My theory is that it reduces the non-relevant tokens and behaves much like the native language. This article dives deep into this subject.
³The Magic Triangle- A blueprint for LLM-native development; stay tuned, and follow me to read the blueprint when it gets published.
Building LLM Apps: A Clear Step-By-Step Guide was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.