Boost the performance of your supervised fine-tuned models

Image by author
Pre-trained Large Language Models (LLMs) can only perform next-token prediction, making them unable to answer questions. This is why these base models are then fine-tuned on pairs of instructions and answers to act as helpful assistants. However, this process can still be flawed: fine-tuned LLMs can be biased, toxic, harmful, etc. This is where Reinforcement Learning from Human Feedback (RLHF) comes into play.
RLHF provides different answers to the LLM, which are ranked according to a desired behavior (helpfulness, toxicity, etc.). The model learns to output the best answer among these candidates, hence mimicking the behavior we want to instill. Often seen as a way to censor models, this process has recently become popular for improving performance, as shown in neural-chat-7b-v3–1.
In this article, we will create NeuralHermes-2.5, by fine-tuning OpenHermes-2.5 using a RLHF-like technique: Direct Preference Optimization (DPO). For this purpose, we will introduce a preference dataset, describe how the DPO algorithm works, and apply it to our model. We’ll see that it significantly improves the performance of the base model on the Open LLM Leaderboard.
As per usual, the code is available on GitHub and Google Colab.
? Preference datasets
Preference datasets are not standardized, but they typically consist of a collection of answers that are ranked by humans. This ranking is essential, as the RLHF process fine-tunes LLMs to output the preferred answer. Here is an example of Anthropic/hh-rlhf, a popular preference dataset:

Image by author
The structure of the dataset is straightforward: for each row, there is one chosen (preferred) answer, and one rejected answer. The goal of RLHF is to guide the model to output the preferred answer.
Preference datasets are notoriously costly and difficult to make, as they require collecting manual feedback from humans. This feedback is also subjective and can easily be biased toward confident (but wrong) answers or contradict itself (different annotators have different values). Over time, several solutions have been proposed to tackle these issues, such as replacing human feedback with AI feedback (RLAIF).
These datasets also tend to be a lot smaller than fine-tuning datasets. To illustrate this, the excellent neural-chat-7b-v3–1 (best 7B LLM on the Open LLM Leaderboard when it was released) uses 518k samples for fine-tuning (Open-Orca/SlimOrca) but only 12.9k samples for RLHF (Intel/orca_dpo_pairs). In this case, the authors generated answers with GPT-4/3.5 to create the preferred answers, and with Llama 2 13b chat to create the rejected responses. It’s a smart way to bypass human feedback and only rely on models with different levels of performance.
? Direct Preference Optimization
While the concept of RLHF has been used in robotics for a long time, it was popularized for LLMs in OpenAI’s paper Fine-Tuning Language Models from Human Preferences. In this paper, the authors present a framework where a reward model is trained to approximate human feedback. This reward model is then used to optimize the fine-tuned model’s policy using the Proximal Policy Optimization (PPO) algorithm.
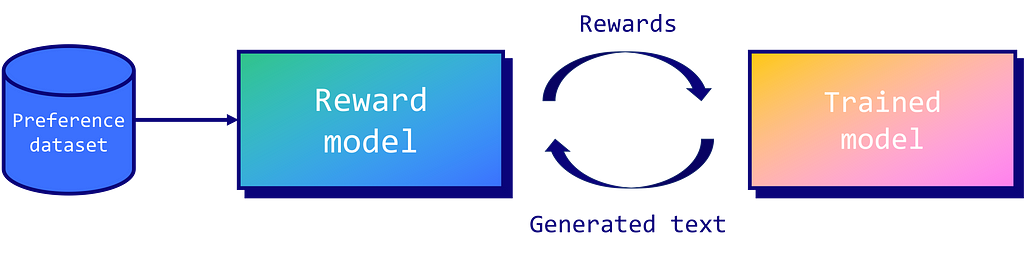
Image by author
The core concept of PPO revolves around making smaller, incremental updates to the policy, as larger updates can lead to instability or suboptimal solutions. From experience, this technique is unfortunately still unstable (loss diverges), difficult to reproduce (numerous hyperparameters, sensitive to random seeds), and computationally expensive.
This is where Direct Preference Optimization (DPO) comes into play. DPO simplifies control by treating the task as a classification problem. Concretely, it uses two models: the trained model (or policy model) and a copy of it called the reference model. During training, the goal is to make sure the trained model outputs higher probabilities for preferred answers than the reference model. Conversely, we also want it to output lower probabilities for rejected answers. It means we’re penalizing the LLM for bad answers and rewarding it for good ones.
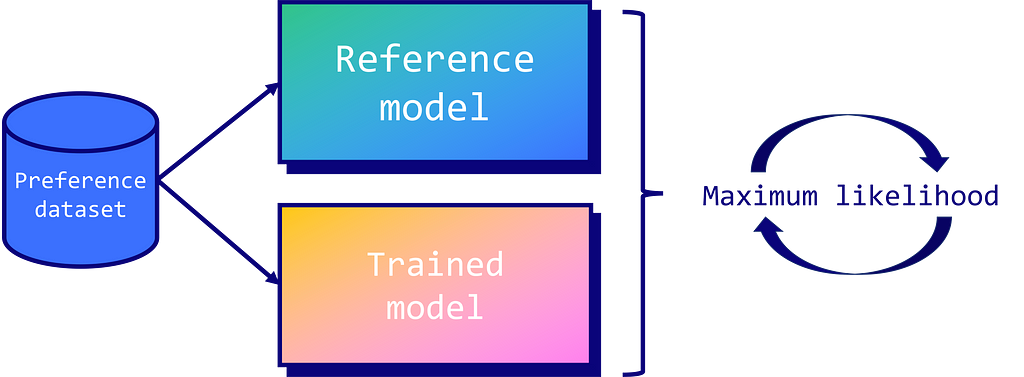
Image by author
By using the LLM itself as a reward model and employing binary cross-entropy objectives, DPO efficiently aligns the model’s outputs with human preferences without the need for extensive sampling, reward model fitting, or intricate hyperparameter adjustments. It results in a more stable, more efficient, and computationally less demanding process.
? Formatting the data
In this example, we’ll fine-tune the excellent OpenHermes-2.5-Mistral-7B, which is a Mistral-7b model that was only supervised fine-tuned. To this end, we’ll use the Intel/orca_dpo_pairs dataset to align our model and improve its performance. We call this new model NeuralHermes-2.5-Mistral-7B.
The first step consists of installing the required libraries as follows.
pip install -q datasets trl peft bitsandbytes sentencepiece wandb
Once it’s done, we can import the libraries. I’m also using the secrets tab in Google Colab to store my Hugging Face token.
import os
import gc
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from datasets import load_dataset
from peft import LoraConfig, PeftModel, get_peft_model, prepare_model_for_kbit_training
from trl import DPOTrainer
import bitsandbytes as bnb
from google.colab import userdata
import wandb
# Defined in the secrets tab in Google Colab
hf_token = userdata.get('huggingface')
wb_token = userdata.get('wandb')
wandb.login(key=wb_token)
model_name = "teknium/OpenHermes-2.5-Mistral-7B"
new_model = "NeuralHermes-2.5-Mistral-7B"
OpenHermes-2.5-Mistral-7B uses a specific chat template, called ChatML. Here is an example of a conversation formatted with this template:
<|im_start|>system
You are a helpful chatbot assistant.<|im_end|>
<|im_start|>user
Hi<|im_end|>
<|im_start|>assistant
Hi, how can I help you?<|im_end|>
As you can see, ChatML defines different roles (system, user, assistant) and appends special tokens (<|im_start|> and <|im_end|>) to separate them. Moreover, DPOTrainer also requires a specific format with three columns: prompt, chosen, and rejected.
Our dataset contains four columns: system, question, chatgpt, and llama2–13b-chat. We’ll simply concatenate the system and question columns to the prompt column. We’ll also map the chatgpt column to “chosen” and llama2–13b-chat to “rejected”. To format the dataset in a reliable way, we’ll use the tokenizer’s apply_chat_template() function, which already uses ChatML.
def chatml_format(example):
# Format system
if len(example['system']) > 0:
message = {"role": "system", "content": example['system']}
system = tokenizer.apply_chat_template([message], tokenize=False)
else:
system = ""
# Format instruction
message = {"role": "user", "content": example['question']}
prompt = tokenizer.apply_chat_template([message], tokenize=False, add_generation_prompt=True)
# Format chosen answer
chosen = example['chosen'] + "<|im_end|>\n"
# Format rejected answer
rejected = example['rejected'] + "<|im_end|>\n"
return {
"prompt": system + prompt,
"chosen": chosen,
"rejected": rejected,
}
# Load dataset
dataset = load_dataset("Intel/orca_dpo_pairs")['train']
# Save columns
original_columns = dataset.column_names
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
# Format dataset
dataset = dataset.map(
chatml_format,
remove_columns=original_columns
)
Let’s print a sample of the formatted dataset to confirm that everything works as expected:
{'prompt': '<|im_start|>system\nYou are an AI assistant. You will be given a task. You must generate a detailed and long answer.<|im_end|>\n<|im_start|>user\nGenerate an approximately fifteen-word sentence that describes all this data: Midsummer House eatType restaurant; Midsummer House food Chinese; Midsummer House priceRange moderate; Midsummer House customer rating 3 out of 5; Midsummer House near All Bar One<|im_end|>\n<|im_start|>assistant\n',
'chosen': 'Midsummer House is a moderately priced Chinese restaurant with a 3/5 customer rating, located near All Bar One.<|im_end|>\n',
'rejected': ' Sure! Here\'s a sentence that describes all the data you provided:\n\n"Midsummer House is a moderately priced Chinese restaurant with a customer rating of 3 out of 5, located near All Bar One, offering a variety of delicious dishes."<|im_end|>\n'}
We can see that the prompt combines system and user instructions. Thanks to the add_generation_prompt=True argument, it also appends the beginning of the assistant's answer. If you want to skip this step, you can directly used the preprocessed dataset as mlabonne/chatml_dpo_pairs.
⚙️ Training the model with DPO
Next, we define the LoRA configurations to train the model. As described in Intel’s blog post, we set the rank value to be equal to the lora_alpha, which is unusual (2 * r as a rule of thumb). We also target all the linear modules with adapters.
# LoRA configuration
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['k_proj', 'gate_proj', 'v_proj', 'up_proj', 'q_proj', 'o_proj', 'down_proj']
)
We’re now ready to load the model we want to fine-tune with DPO. In this case, two models are required: the model to fine-tune as well as the reference model. This is mostly for the sake of readability, as the DPOTrainer object automatically creates a reference model if none is provided.
# Model to fine-tune
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
load_in_4bit=True
)
model.config.use_cache = False
# Reference model
ref_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
load_in_4bit=True
)
The final step consists of providing all the hyperparameters to TrainingArguments and DPOTrainer:
We can now start training the model. Note that it requires an A100 GPU and takes between 1 hour to complete the training.
# Training arguments
training_args = TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=5e-5,
lr_scheduler_type="cosine",
max_steps=200,
save_strategy="no",
logging_steps=1,
output_dir=new_model,
optim="paged_adamw_32bit",
warmup_steps=100,
bf16=True,
report_to="wandb",
)
# Create DPO trainer
dpo_trainer = DPOTrainer(
model,
ref_model,
args=training_args,
train_dataset=dataset,
tokenizer=tokenizer,
peft_config=peft_config,
beta=0.1,
max_prompt_length=1024,
max_length=1536,
)
# Fine-tune model with DPO
dpo_trainer.train()
Our model is now fine-tuned. You can check the project on Weights & Biases at this address. Here are some interesting metrics to analyze:

Image by author
Interestingly, the training loss quickly drops to zero (before 50 steps), despite 100 warmup steps. Meanwhile, the other metrics keep evolving.
The train/rewards/chosen and train/rewards/rejected plots correspond to the mean difference between the log probabilities output by the trained and reference models. It makes sense that, over time, they diverge as our trained model learns the preferred answers. The train/rewards/margins plot also shows the difference between these two plots. Finally, the train/reward/accuracies plot shows the frequency of choosing the preferred answer. The trained model quickly reaches a perfect accuracy score, which is a good sign but could also mean that the difference between preferred and rejected answers is too obvious.
Now that it’s trained, we can merge the adapter with the original model. Next, we save the merged model and the tokenizer before pushing it to the Hugging Face Hub.
# Save artifacts
dpo_trainer.model.save_pretrained("final_checkpoint")
tokenizer.save_pretrained("final_checkpoint")
# Flush memory
del dpo_trainer, model, ref_model
gc.collect()
torch.cuda.empty_cache()
# Reload model in FP16 (instead of NF4)
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
return_dict=True,
torch_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Merge base model with the adapter
model = PeftModel.from_pretrained(base_model, "final_checkpoint")
model = model.merge_and_unload()
# Save model and tokenizer
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)
# Push them to the HF Hub
model.push_to_hub(new_model, use_temp_dir=False, token=hf_token)
tokenizer.push_to_hub(new_model, use_temp_dir=False, token=hf_token)
Let’s see how our model performs in a real test. We’ll format the prompt to ask a basic question: “What is a Large Language Model?”
# Format prompt
message = [
{"role": "system", "content": "You are a helpful assistant chatbot."},
{"role": "user", "content": "What is a Large Language Model?"}
]
tokenizer = AutoTokenizer.from_pretrained(new_model)
prompt = tokenizer.apply_chat_template(message, add_generation_prompt=True, tokenize=False)
# Create pipeline
pipeline = transformers.pipeline(
"text-generation",
model=new_model,
tokenizer=tokenizer
)
# Generate text
sequences = pipeline(
prompt,
do_sample=True,
temperature=0.7,
top_p=0.9,
num_return_sequences=1,
max_length=200,
)
print(sequences[0]['generated_text'])
Here’s the answer from the model:
A large language model is a type of artificial intelligence (AI) system that has been trained on vast amounts of text data. These models are designed to understand and generate human language, allowing them to perform various natural language processing tasks, such as text generation, language translation, and question answering. Large language models typically use deep learning techniques, like recurrent neural networks (RNNs) or transformers, to learn patterns and relationships in the data, enabling them to generate coherent and contextually relevant responses. The size of these models, in terms of the number of parameters and the volume of data they are trained on, plays a significant role in their ability to comprehend and produce complex language structures.
Everything seems to be working, we can now evaluate the merged model. As this is a general-purpose model, we can leverage the lm-evaluation-harness to evaluate it. As the process is quite resource-intensive, we can also directly submit it for evaluation on the Open LLM Leaderboard. It took a few days, but here are the results compared to other OpenHermes models:
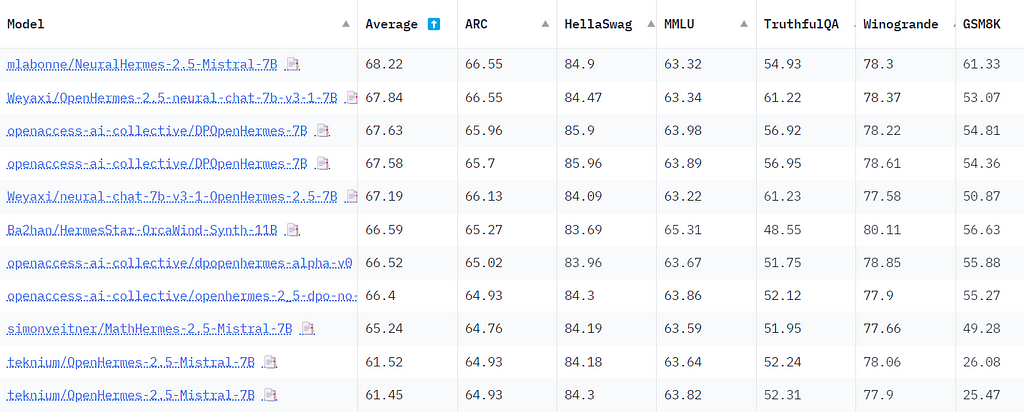
Image by author
Compared to the original model, NeuralHermes-2–5-Mistral-7B model improved the average score by 6.7 points (particularly on GSM8K). This is an unexpectedly large improvement, which showcases the power of Direct Preference Optimization.
Conclusion
In this article, we fine-tuned an already supervised fine-tuned model using DPO and created our own NeuralHermes-2.5 model. By leveraging a high-quality preference dataset, we created a sample-efficient fine-tuning pipeline that produced a significant improvement on the Open LLM Leaderboard. If you want to give it a try, you can find quantized variants of this model or use this Hugging Face Space.
Note that our fine-tuning pipeline can still be improved in different ways. For example, the preference dataset is still quite raw and could be improved with more filtering and by using different models. In addition, numerous hyperparameters can still be tweaked to achieve better results. In particular, the learning rate can still be lowered to train the model on more steps and inject more preference data.
References
Learn more about machine learning and support my work with one click — become a Medium member here:
Join Medium with my referral link - Maxime Labonne

Fine-tune a Mistral-7b model with Direct Preference Optimization was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Image by author
Pre-trained Large Language Models (LLMs) can only perform next-token prediction, making them unable to answer questions. This is why these base models are then fine-tuned on pairs of instructions and answers to act as helpful assistants. However, this process can still be flawed: fine-tuned LLMs can be biased, toxic, harmful, etc. This is where Reinforcement Learning from Human Feedback (RLHF) comes into play.
RLHF provides different answers to the LLM, which are ranked according to a desired behavior (helpfulness, toxicity, etc.). The model learns to output the best answer among these candidates, hence mimicking the behavior we want to instill. Often seen as a way to censor models, this process has recently become popular for improving performance, as shown in neural-chat-7b-v3–1.
In this article, we will create NeuralHermes-2.5, by fine-tuning OpenHermes-2.5 using a RLHF-like technique: Direct Preference Optimization (DPO). For this purpose, we will introduce a preference dataset, describe how the DPO algorithm works, and apply it to our model. We’ll see that it significantly improves the performance of the base model on the Open LLM Leaderboard.
As per usual, the code is available on GitHub and Google Colab.
? Preference datasets
Preference datasets are not standardized, but they typically consist of a collection of answers that are ranked by humans. This ranking is essential, as the RLHF process fine-tunes LLMs to output the preferred answer. Here is an example of Anthropic/hh-rlhf, a popular preference dataset:
Image by author
The structure of the dataset is straightforward: for each row, there is one chosen (preferred) answer, and one rejected answer. The goal of RLHF is to guide the model to output the preferred answer.
Preference datasets are notoriously costly and difficult to make, as they require collecting manual feedback from humans. This feedback is also subjective and can easily be biased toward confident (but wrong) answers or contradict itself (different annotators have different values). Over time, several solutions have been proposed to tackle these issues, such as replacing human feedback with AI feedback (RLAIF).
These datasets also tend to be a lot smaller than fine-tuning datasets. To illustrate this, the excellent neural-chat-7b-v3–1 (best 7B LLM on the Open LLM Leaderboard when it was released) uses 518k samples for fine-tuning (Open-Orca/SlimOrca) but only 12.9k samples for RLHF (Intel/orca_dpo_pairs). In this case, the authors generated answers with GPT-4/3.5 to create the preferred answers, and with Llama 2 13b chat to create the rejected responses. It’s a smart way to bypass human feedback and only rely on models with different levels of performance.
? Direct Preference Optimization
While the concept of RLHF has been used in robotics for a long time, it was popularized for LLMs in OpenAI’s paper Fine-Tuning Language Models from Human Preferences. In this paper, the authors present a framework where a reward model is trained to approximate human feedback. This reward model is then used to optimize the fine-tuned model’s policy using the Proximal Policy Optimization (PPO) algorithm.
Image by author
The core concept of PPO revolves around making smaller, incremental updates to the policy, as larger updates can lead to instability or suboptimal solutions. From experience, this technique is unfortunately still unstable (loss diverges), difficult to reproduce (numerous hyperparameters, sensitive to random seeds), and computationally expensive.
This is where Direct Preference Optimization (DPO) comes into play. DPO simplifies control by treating the task as a classification problem. Concretely, it uses two models: the trained model (or policy model) and a copy of it called the reference model. During training, the goal is to make sure the trained model outputs higher probabilities for preferred answers than the reference model. Conversely, we also want it to output lower probabilities for rejected answers. It means we’re penalizing the LLM for bad answers and rewarding it for good ones.
Image by author
By using the LLM itself as a reward model and employing binary cross-entropy objectives, DPO efficiently aligns the model’s outputs with human preferences without the need for extensive sampling, reward model fitting, or intricate hyperparameter adjustments. It results in a more stable, more efficient, and computationally less demanding process.
? Formatting the data
In this example, we’ll fine-tune the excellent OpenHermes-2.5-Mistral-7B, which is a Mistral-7b model that was only supervised fine-tuned. To this end, we’ll use the Intel/orca_dpo_pairs dataset to align our model and improve its performance. We call this new model NeuralHermes-2.5-Mistral-7B.
The first step consists of installing the required libraries as follows.
pip install -q datasets trl peft bitsandbytes sentencepiece wandb
Once it’s done, we can import the libraries. I’m also using the secrets tab in Google Colab to store my Hugging Face token.
import os
import gc
import torch
import transformers
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig
from datasets import load_dataset
from peft import LoraConfig, PeftModel, get_peft_model, prepare_model_for_kbit_training
from trl import DPOTrainer
import bitsandbytes as bnb
from google.colab import userdata
import wandb
# Defined in the secrets tab in Google Colab
hf_token = userdata.get('huggingface')
wb_token = userdata.get('wandb')
wandb.login(key=wb_token)
model_name = "teknium/OpenHermes-2.5-Mistral-7B"
new_model = "NeuralHermes-2.5-Mistral-7B"
OpenHermes-2.5-Mistral-7B uses a specific chat template, called ChatML. Here is an example of a conversation formatted with this template:
<|im_start|>system
You are a helpful chatbot assistant.<|im_end|>
<|im_start|>user
Hi<|im_end|>
<|im_start|>assistant
Hi, how can I help you?<|im_end|>
As you can see, ChatML defines different roles (system, user, assistant) and appends special tokens (<|im_start|> and <|im_end|>) to separate them. Moreover, DPOTrainer also requires a specific format with three columns: prompt, chosen, and rejected.
Our dataset contains four columns: system, question, chatgpt, and llama2–13b-chat. We’ll simply concatenate the system and question columns to the prompt column. We’ll also map the chatgpt column to “chosen” and llama2–13b-chat to “rejected”. To format the dataset in a reliable way, we’ll use the tokenizer’s apply_chat_template() function, which already uses ChatML.
def chatml_format(example):
# Format system
if len(example['system']) > 0:
message = {"role": "system", "content": example['system']}
system = tokenizer.apply_chat_template([message], tokenize=False)
else:
system = ""
# Format instruction
message = {"role": "user", "content": example['question']}
prompt = tokenizer.apply_chat_template([message], tokenize=False, add_generation_prompt=True)
# Format chosen answer
chosen = example['chosen'] + "<|im_end|>\n"
# Format rejected answer
rejected = example['rejected'] + "<|im_end|>\n"
return {
"prompt": system + prompt,
"chosen": chosen,
"rejected": rejected,
}
# Load dataset
dataset = load_dataset("Intel/orca_dpo_pairs")['train']
# Save columns
original_columns = dataset.column_names
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
# Format dataset
dataset = dataset.map(
chatml_format,
remove_columns=original_columns
)
Let’s print a sample of the formatted dataset to confirm that everything works as expected:
{'prompt': '<|im_start|>system\nYou are an AI assistant. You will be given a task. You must generate a detailed and long answer.<|im_end|>\n<|im_start|>user\nGenerate an approximately fifteen-word sentence that describes all this data: Midsummer House eatType restaurant; Midsummer House food Chinese; Midsummer House priceRange moderate; Midsummer House customer rating 3 out of 5; Midsummer House near All Bar One<|im_end|>\n<|im_start|>assistant\n',
'chosen': 'Midsummer House is a moderately priced Chinese restaurant with a 3/5 customer rating, located near All Bar One.<|im_end|>\n',
'rejected': ' Sure! Here\'s a sentence that describes all the data you provided:\n\n"Midsummer House is a moderately priced Chinese restaurant with a customer rating of 3 out of 5, located near All Bar One, offering a variety of delicious dishes."<|im_end|>\n'}
We can see that the prompt combines system and user instructions. Thanks to the add_generation_prompt=True argument, it also appends the beginning of the assistant's answer. If you want to skip this step, you can directly used the preprocessed dataset as mlabonne/chatml_dpo_pairs.
⚙️ Training the model with DPO
Next, we define the LoRA configurations to train the model. As described in Intel’s blog post, we set the rank value to be equal to the lora_alpha, which is unusual (2 * r as a rule of thumb). We also target all the linear modules with adapters.
# LoRA configuration
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['k_proj', 'gate_proj', 'v_proj', 'up_proj', 'q_proj', 'o_proj', 'down_proj']
)
We’re now ready to load the model we want to fine-tune with DPO. In this case, two models are required: the model to fine-tune as well as the reference model. This is mostly for the sake of readability, as the DPOTrainer object automatically creates a reference model if none is provided.
# Model to fine-tune
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
load_in_4bit=True
)
model.config.use_cache = False
# Reference model
ref_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
load_in_4bit=True
)
The final step consists of providing all the hyperparameters to TrainingArguments and DPOTrainer:
- Among them, the beta parameter is unique to DPO since it controls the divergence from the initial policy (0.1 is a typical value for it).
- Compared to the values described in Intel’s blog post, we lower the learning rate (from 5e-4 to 5e-5) and the number of steps (from 1,000 to 200). I manually optimized these values after a few runs to stabilize training and achieve the best results.
We can now start training the model. Note that it requires an A100 GPU and takes between 1 hour to complete the training.
# Training arguments
training_args = TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=5e-5,
lr_scheduler_type="cosine",
max_steps=200,
save_strategy="no",
logging_steps=1,
output_dir=new_model,
optim="paged_adamw_32bit",
warmup_steps=100,
bf16=True,
report_to="wandb",
)
# Create DPO trainer
dpo_trainer = DPOTrainer(
model,
ref_model,
args=training_args,
train_dataset=dataset,
tokenizer=tokenizer,
peft_config=peft_config,
beta=0.1,
max_prompt_length=1024,
max_length=1536,
)
# Fine-tune model with DPO
dpo_trainer.train()
Our model is now fine-tuned. You can check the project on Weights & Biases at this address. Here are some interesting metrics to analyze:
Image by author
Interestingly, the training loss quickly drops to zero (before 50 steps), despite 100 warmup steps. Meanwhile, the other metrics keep evolving.
The train/rewards/chosen and train/rewards/rejected plots correspond to the mean difference between the log probabilities output by the trained and reference models. It makes sense that, over time, they diverge as our trained model learns the preferred answers. The train/rewards/margins plot also shows the difference between these two plots. Finally, the train/reward/accuracies plot shows the frequency of choosing the preferred answer. The trained model quickly reaches a perfect accuracy score, which is a good sign but could also mean that the difference between preferred and rejected answers is too obvious.
Now that it’s trained, we can merge the adapter with the original model. Next, we save the merged model and the tokenizer before pushing it to the Hugging Face Hub.
# Save artifacts
dpo_trainer.model.save_pretrained("final_checkpoint")
tokenizer.save_pretrained("final_checkpoint")
# Flush memory
del dpo_trainer, model, ref_model
gc.collect()
torch.cuda.empty_cache()
# Reload model in FP16 (instead of NF4)
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
return_dict=True,
torch_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Merge base model with the adapter
model = PeftModel.from_pretrained(base_model, "final_checkpoint")
model = model.merge_and_unload()
# Save model and tokenizer
model.save_pretrained(new_model)
tokenizer.save_pretrained(new_model)
# Push them to the HF Hub
model.push_to_hub(new_model, use_temp_dir=False, token=hf_token)
tokenizer.push_to_hub(new_model, use_temp_dir=False, token=hf_token)
Let’s see how our model performs in a real test. We’ll format the prompt to ask a basic question: “What is a Large Language Model?”
# Format prompt
message = [
{"role": "system", "content": "You are a helpful assistant chatbot."},
{"role": "user", "content": "What is a Large Language Model?"}
]
tokenizer = AutoTokenizer.from_pretrained(new_model)
prompt = tokenizer.apply_chat_template(message, add_generation_prompt=True, tokenize=False)
# Create pipeline
pipeline = transformers.pipeline(
"text-generation",
model=new_model,
tokenizer=tokenizer
)
# Generate text
sequences = pipeline(
prompt,
do_sample=True,
temperature=0.7,
top_p=0.9,
num_return_sequences=1,
max_length=200,
)
print(sequences[0]['generated_text'])
Here’s the answer from the model:
A large language model is a type of artificial intelligence (AI) system that has been trained on vast amounts of text data. These models are designed to understand and generate human language, allowing them to perform various natural language processing tasks, such as text generation, language translation, and question answering. Large language models typically use deep learning techniques, like recurrent neural networks (RNNs) or transformers, to learn patterns and relationships in the data, enabling them to generate coherent and contextually relevant responses. The size of these models, in terms of the number of parameters and the volume of data they are trained on, plays a significant role in their ability to comprehend and produce complex language structures.
Everything seems to be working, we can now evaluate the merged model. As this is a general-purpose model, we can leverage the lm-evaluation-harness to evaluate it. As the process is quite resource-intensive, we can also directly submit it for evaluation on the Open LLM Leaderboard. It took a few days, but here are the results compared to other OpenHermes models:
Image by author
Compared to the original model, NeuralHermes-2–5-Mistral-7B model improved the average score by 6.7 points (particularly on GSM8K). This is an unexpectedly large improvement, which showcases the power of Direct Preference Optimization.
Conclusion
In this article, we fine-tuned an already supervised fine-tuned model using DPO and created our own NeuralHermes-2.5 model. By leveraging a high-quality preference dataset, we created a sample-efficient fine-tuning pipeline that produced a significant improvement on the Open LLM Leaderboard. If you want to give it a try, you can find quantized variants of this model or use this Hugging Face Space.
Note that our fine-tuning pipeline can still be improved in different ways. For example, the preference dataset is still quite raw and could be improved with more filtering and by using different models. In addition, numerous hyperparameters can still be tweaked to achieve better results. In particular, the learning rate can still be lowered to train the model on more steps and inject more preference data.
References
- Fine-tune Llama 2 with DPO by Kashif Rasul, Younes Belkada, and Leandro von Werra.
- Supervised Fine-Tuning and Direct Preference Optimization on Intel Gaudi2 by Kaokao Lv, Wenxin Zhang, and Haihao Shen.
- llama2-fine-tune by mzbac.
Learn more about machine learning and support my work with one click — become a Medium member here:
Join Medium with my referral link - Maxime Labonne
Fine-tune a Mistral-7b model with Direct Preference Optimization was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.