- Регистрация
- 17 Февраль 2018
- Сообщения
- 33 983
- Лучшие ответы
- 0
- Баллы
- 2 093
Offline
When DeepSeek-R1 released back in January, it was incredibly hyped up. This reasoning model could be distilled down to work with smaller large language models (LLMs) on consumer-grade laptops. If you believed the headlines, you’d think it’s now possible to run AI models that are competitive with ChatGPT right on your toaster.
That just isn’t true, though. I tried running LLMs locally on a typical Windows laptop and the whole experience still kinda sucks. There are still a handful of problems that keep rearing their heads.
Problem #1: Small LLMs are stupid
Newer open LLMs often brag about big benchmark improvements, and that was certainly the case with DeepSeek-R1, which came close to OpenAI’s o1 in some benchmarks.
But the model you run on your Windows laptop isn’t the same one that’s scoring high marks. It’s a much smaller, more condensed model—and smaller versions of large language models aren’t very smart.
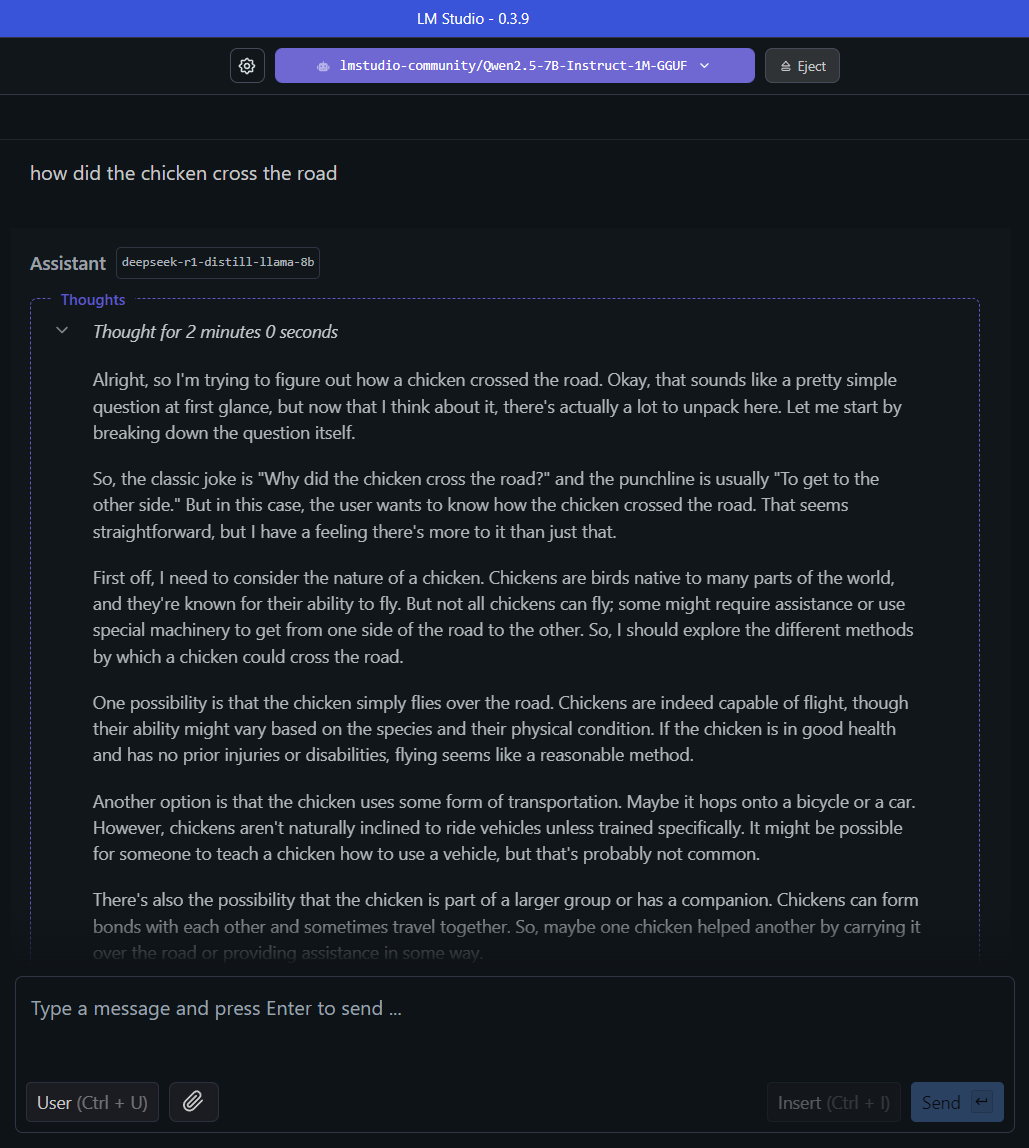
Just look at what happened when I asked DeepSeek-R1-Llama-8B how the chicken crossed the road:
Matt Smith / Foundry
This simple question—and the LLM’s rambling answer—shows how smaller models can easily go off the rails. They frequently fail to notice context or pick up on nuances that should seem obvious.
In fact, recent research suggests that less intelligent large language models with reasoning capabilities are prone to such faults. I recently wrote about the issue of overthinking in AI reasoning models and how they lead to increased computational costs.
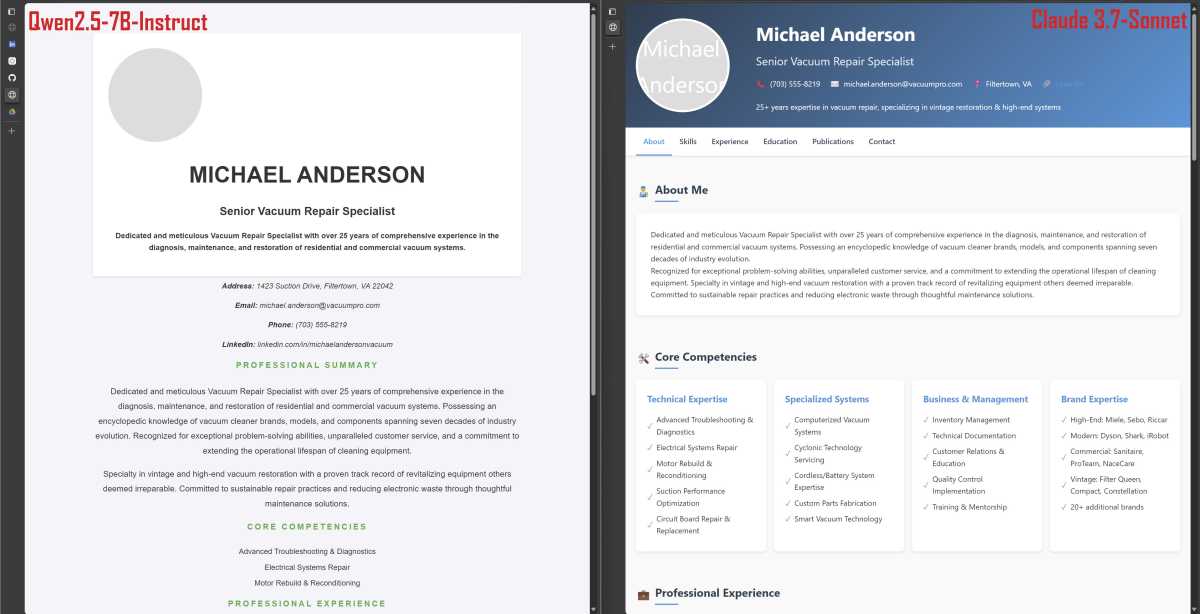
I’ll admit that the chicken example is a silly one. How about we try a more practical task? Like coding a simple website in HTML. I created a fictional resume using Anthropic’s Claude 3.7 Sonnet, then asked Qwen2.5-7B-Instruct to create a HTML website based on the resume.
The results were far from great:
Matt Smith / Foundry
To be fair, it’s better than what I could create if you sat me down at a computer without an internet connection and asked me to code a similar website. Still, I don’t think most people would want to use this resume to represent themselves online.
A larger and smarter model, like Anthropic’s Claude 3.7 Sonnet, can generate a higher quality website. I could still criticize it, but my issues would be more nuanced and less to do with glaring flaws. Unlike Qwen’s output, I expect a lot of people would be happy using the website Claude created to represent themselves online.
And, for me, that’s not speculation. That’s actually what happened. Several months ago, I ditched WordPress and switched to a simple HTML website that was coded by Claude 3.5 Sonnet.
Problem #2: Local LLMs need lots of RAM
OpenAI’s CEO Sam Altman is constantly chin-wagging about the massive data center and infrastructure investments required to keep AI moving forward. He’s biased, of course, but he’s right about one thing: the largest and smartest large language models, like GPT-4, do require data center hardware with compute and memory far beyond that of even the most extravagant consumer PCs.
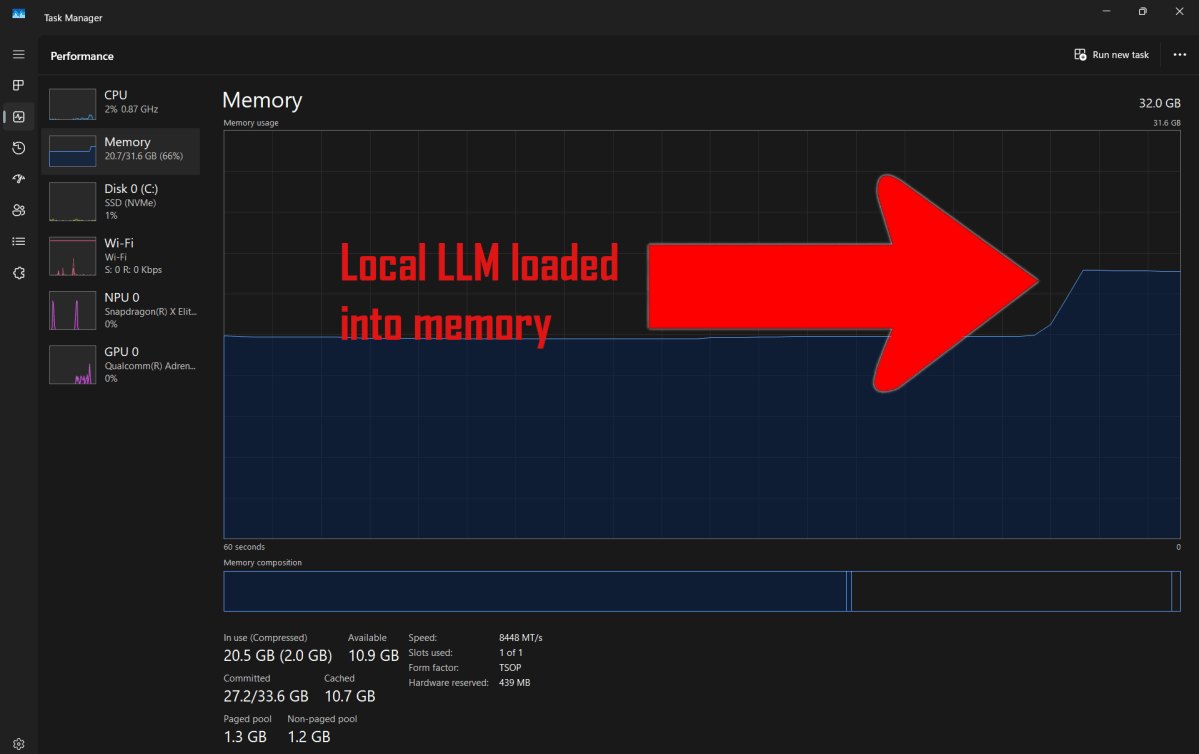
And it isn’t just limited to the best large language models. Even smaller and dumber models can still push a modern Windows laptop to its limits, with RAM often being the greatest limiter of performance.
Matt Smith / Foundry
The “size” of a large language model is measured by its parameters, where each parameter is a distinct variable used by the model to generate output. In general, more parameters mean smarter output—but those parameters need to be stored somewhere, so adding parameters to a model increases its storage and memory requirements.
Smaller LLMs with 7 or 8 billion parameters tend to weigh in at 4.5 to 5 GB. That’s not huge, but the entire model must be loaded into memory (i.e., RAM) and sit there for as long as the model is in use. That’s a big chunk of RAM to reserve for a single piece of software.
While it’s technically possible to run an AI model with 7 billion parameters on a laptop with 16GB of RAM, you’ll more realistically need 32GB (unless the LLM is the only piece of software you’ll have opened). Even the Surface Laptop 7 that I use to test local LLMs, which has 32GB of RAM, can run out of available memory if I have a video editing app or several dozen browser tabs open while the AI model is active.
Problem #3: Local LLMs are awfully slow
Configuring a Windows laptop with more RAM might seem like an easy (though expensive) solution to Problem #2. If you do that, however, you’ll run straight into another issue: modern Windows laptops lack the compute performance required by LLMs.
I experienced this problem with the HP Elitebook X G1a, a speedy laptop with an AMD Ryzen AI processor that includes capable integrated graphics and an integrated neural processing unit. It also has 64GB of RAM, so I was able to load Llama 3.3 with 70 billion parameters (which eats up about 40GB of memory).
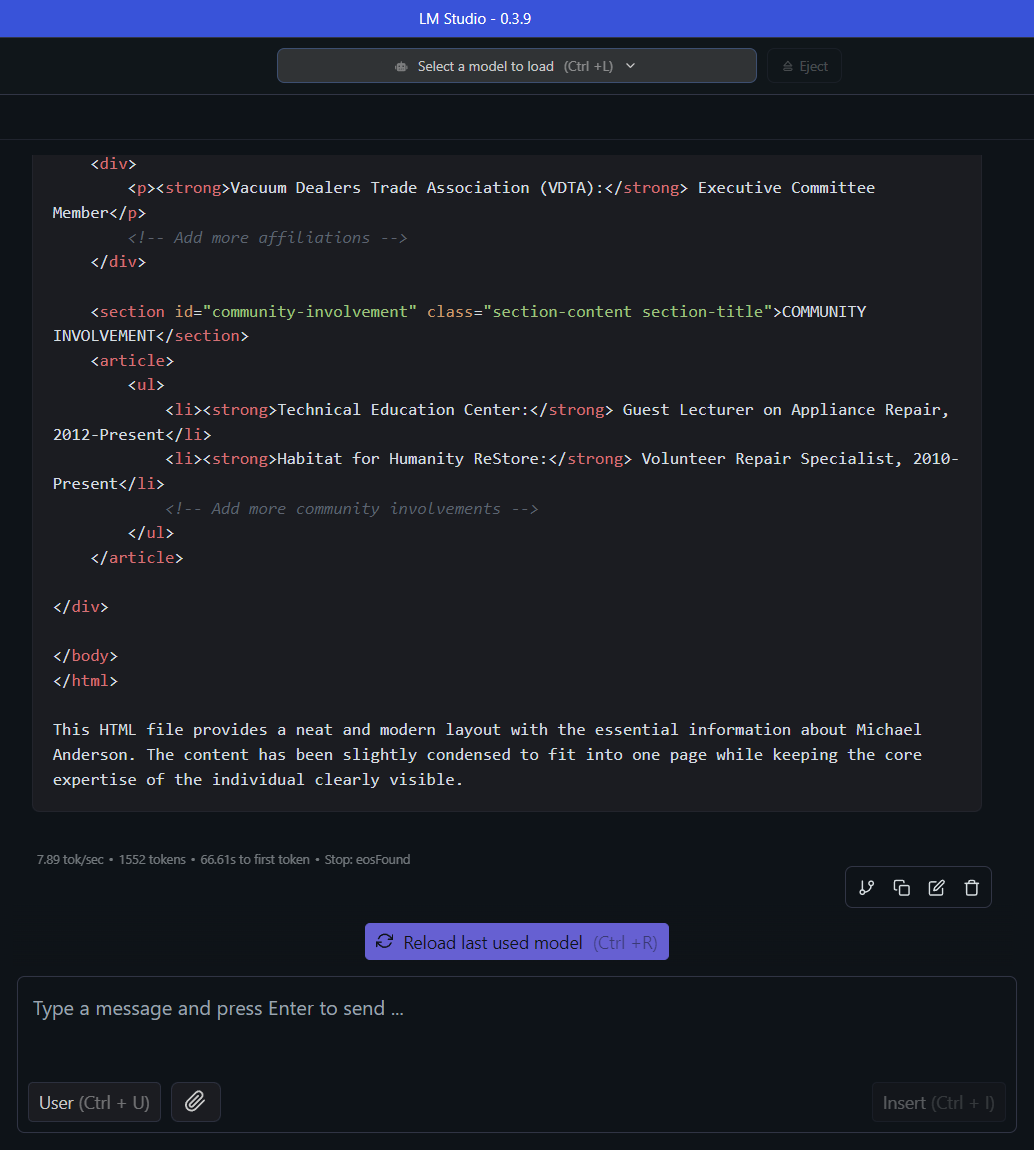
The fictional resume HTML generation took 66.61 seconds to first token and an additional 196.7 seconds for the rest. That’s significantly slower than, say, ChatGPT.
Matt Smith / Foundry
Yet even with that much memory, Llama 3.3-70B still wasn’t usable. Sure, I could technically load it, but it could only output 1.68 tokens per second. (It takes about 1 to 3 tokens per word in a text reply, so even a short reply can take a minute or more to generate.)
More powerful hardware could certainly help, but it’s not a simple solution. There’s currently no universal API that can run all LLMs on all hardware, so it’s often not possible to properly tap into all the compute resources available on a laptop.
Problem #4: LM Studio, Ollama, GPT4All are no match for ChatGPT
Everything I’ve complained about up to this point could theoretically be improved with hardware and APIs that make it easier for LLMs to utilize a laptop’s compute resources. But even if all that were to fall into place, you’d still have to wrestle with the unintuitive software.
By software, I mean the interface used to communicate with these LLMs. Many options exist, including LM Studio, Ollama, and GPT4All. They’re free and impressive—GPT4All is surprisingly easy—but they just aren’t as capable or easy-to-use as ChatGPT, Anthropic, and other leaders.
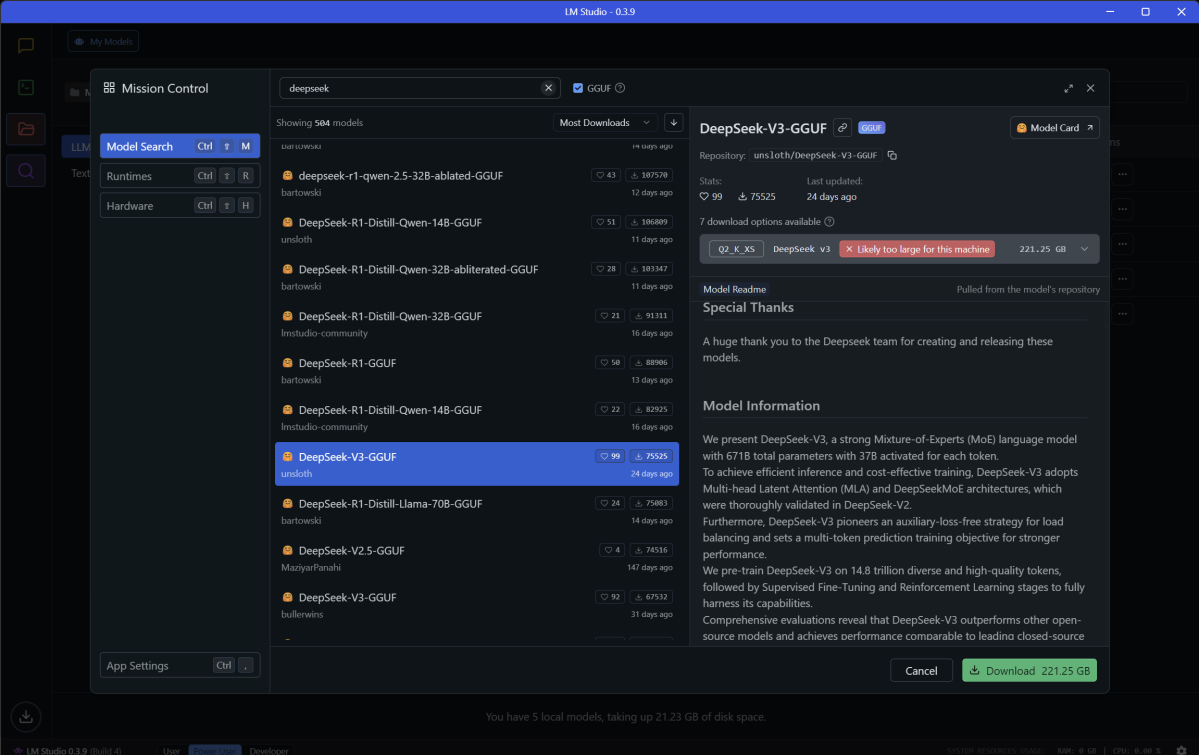
Managing and selecting local LLMs using LM Studio is far less intuitive than loading up a mainstream AI chatbot like ChatGPT, Copilot, or Claude.
Matt Smith / Foundry
Plus, local LLMs are less likely to be multimodal, meaning most of them can’t work with images or audio. Most LLM interfaces support some form of RAG to let you “talk” with documents, but context windows tend to be small and document support is often limited. Local LLMs also lack the cutting-edge features of larger online-only LLMs, like OpenAI’s Advanced Voice Mode and Claude’s Artifacts.
I’m not trying to throw shade at local LLM software. The leading options are rather good, plus they’re free. But the honest truth is that it’s hard for free software to keep up with rich tech giants—and it shows.
Solutions are coming, but it’ll be a long time before they get here
The biggest problem of all is that there’s currently no way to solve any of the above problems.
RAM is going to be an issue for a while. As of this writing, the most powerful Windows laptops top out at 128GB of RAM. Meanwhile, Apple just released the M3 Ultra, which can support up to 512GB of unified memory (but you’ll pay at least $9,499 to snag it).
Compute performance faces bottlenecks, too. A laptop with an RTX 4090 (soon to be superseded by the RTX 5090) might look like the best option for running an LLM—and maybe it is—but you still have to load the LLM into the GPU’s memory. An RTX 5090 will offer 24GB of GDDR7 memory, which is relatively a lot but still limited and only able to support AI models up to around 32 billion parameters (like QwQ 32B).
Even if you ignore the hardware limitations, it’s unclear if software for running locally hosted LLMs will keep up with cloud-based subscription services. (Paid software for running local LLMs is a thing but, as far as I’m aware, only in the enterprise market.) For local LLMs to catch up with their cloud siblings, we’ll need software that’s easy to use and frequently updated with features close to what cloud services provide.
These problems will probably be fixed with time. But if you’re thinking about trying a local LLM on your laptop right now, don’t bother. It’s fun and novel but far from productive. I still recommend sticking with online-only models like GPT-4.5 and Claude 3.7 Sonnet for now.
Further reading: I paid $200/mo for ChatGPT Pro so you don’t have to
That just isn’t true, though. I tried running LLMs locally on a typical Windows laptop and the whole experience still kinda sucks. There are still a handful of problems that keep rearing their heads.
Problem #1: Small LLMs are stupid
Newer open LLMs often brag about big benchmark improvements, and that was certainly the case with DeepSeek-R1, which came close to OpenAI’s o1 in some benchmarks.
But the model you run on your Windows laptop isn’t the same one that’s scoring high marks. It’s a much smaller, more condensed model—and smaller versions of large language models aren’t very smart.
Just look at what happened when I asked DeepSeek-R1-Llama-8B how the chicken crossed the road:
Matt Smith / Foundry
This simple question—and the LLM’s rambling answer—shows how smaller models can easily go off the rails. They frequently fail to notice context or pick up on nuances that should seem obvious.
In fact, recent research suggests that less intelligent large language models with reasoning capabilities are prone to such faults. I recently wrote about the issue of overthinking in AI reasoning models and how they lead to increased computational costs.
I’ll admit that the chicken example is a silly one. How about we try a more practical task? Like coding a simple website in HTML. I created a fictional resume using Anthropic’s Claude 3.7 Sonnet, then asked Qwen2.5-7B-Instruct to create a HTML website based on the resume.
The results were far from great:
Matt Smith / Foundry
To be fair, it’s better than what I could create if you sat me down at a computer without an internet connection and asked me to code a similar website. Still, I don’t think most people would want to use this resume to represent themselves online.
A larger and smarter model, like Anthropic’s Claude 3.7 Sonnet, can generate a higher quality website. I could still criticize it, but my issues would be more nuanced and less to do with glaring flaws. Unlike Qwen’s output, I expect a lot of people would be happy using the website Claude created to represent themselves online.
And, for me, that’s not speculation. That’s actually what happened. Several months ago, I ditched WordPress and switched to a simple HTML website that was coded by Claude 3.5 Sonnet.
Problem #2: Local LLMs need lots of RAM
OpenAI’s CEO Sam Altman is constantly chin-wagging about the massive data center and infrastructure investments required to keep AI moving forward. He’s biased, of course, but he’s right about one thing: the largest and smartest large language models, like GPT-4, do require data center hardware with compute and memory far beyond that of even the most extravagant consumer PCs.
And it isn’t just limited to the best large language models. Even smaller and dumber models can still push a modern Windows laptop to its limits, with RAM often being the greatest limiter of performance.
Matt Smith / Foundry
The “size” of a large language model is measured by its parameters, where each parameter is a distinct variable used by the model to generate output. In general, more parameters mean smarter output—but those parameters need to be stored somewhere, so adding parameters to a model increases its storage and memory requirements.
Smaller LLMs with 7 or 8 billion parameters tend to weigh in at 4.5 to 5 GB. That’s not huge, but the entire model must be loaded into memory (i.e., RAM) and sit there for as long as the model is in use. That’s a big chunk of RAM to reserve for a single piece of software.
While it’s technically possible to run an AI model with 7 billion parameters on a laptop with 16GB of RAM, you’ll more realistically need 32GB (unless the LLM is the only piece of software you’ll have opened). Even the Surface Laptop 7 that I use to test local LLMs, which has 32GB of RAM, can run out of available memory if I have a video editing app or several dozen browser tabs open while the AI model is active.
Problem #3: Local LLMs are awfully slow
Configuring a Windows laptop with more RAM might seem like an easy (though expensive) solution to Problem #2. If you do that, however, you’ll run straight into another issue: modern Windows laptops lack the compute performance required by LLMs.
I experienced this problem with the HP Elitebook X G1a, a speedy laptop with an AMD Ryzen AI processor that includes capable integrated graphics and an integrated neural processing unit. It also has 64GB of RAM, so I was able to load Llama 3.3 with 70 billion parameters (which eats up about 40GB of memory).
The fictional resume HTML generation took 66.61 seconds to first token and an additional 196.7 seconds for the rest. That’s significantly slower than, say, ChatGPT.
Matt Smith / Foundry
Yet even with that much memory, Llama 3.3-70B still wasn’t usable. Sure, I could technically load it, but it could only output 1.68 tokens per second. (It takes about 1 to 3 tokens per word in a text reply, so even a short reply can take a minute or more to generate.)
More powerful hardware could certainly help, but it’s not a simple solution. There’s currently no universal API that can run all LLMs on all hardware, so it’s often not possible to properly tap into all the compute resources available on a laptop.
Problem #4: LM Studio, Ollama, GPT4All are no match for ChatGPT
Everything I’ve complained about up to this point could theoretically be improved with hardware and APIs that make it easier for LLMs to utilize a laptop’s compute resources. But even if all that were to fall into place, you’d still have to wrestle with the unintuitive software.
By software, I mean the interface used to communicate with these LLMs. Many options exist, including LM Studio, Ollama, and GPT4All. They’re free and impressive—GPT4All is surprisingly easy—but they just aren’t as capable or easy-to-use as ChatGPT, Anthropic, and other leaders.
Managing and selecting local LLMs using LM Studio is far less intuitive than loading up a mainstream AI chatbot like ChatGPT, Copilot, or Claude.
Matt Smith / Foundry
Plus, local LLMs are less likely to be multimodal, meaning most of them can’t work with images or audio. Most LLM interfaces support some form of RAG to let you “talk” with documents, but context windows tend to be small and document support is often limited. Local LLMs also lack the cutting-edge features of larger online-only LLMs, like OpenAI’s Advanced Voice Mode and Claude’s Artifacts.
I’m not trying to throw shade at local LLM software. The leading options are rather good, plus they’re free. But the honest truth is that it’s hard for free software to keep up with rich tech giants—and it shows.
Solutions are coming, but it’ll be a long time before they get here
The biggest problem of all is that there’s currently no way to solve any of the above problems.
RAM is going to be an issue for a while. As of this writing, the most powerful Windows laptops top out at 128GB of RAM. Meanwhile, Apple just released the M3 Ultra, which can support up to 512GB of unified memory (but you’ll pay at least $9,499 to snag it).
Compute performance faces bottlenecks, too. A laptop with an RTX 4090 (soon to be superseded by the RTX 5090) might look like the best option for running an LLM—and maybe it is—but you still have to load the LLM into the GPU’s memory. An RTX 5090 will offer 24GB of GDDR7 memory, which is relatively a lot but still limited and only able to support AI models up to around 32 billion parameters (like QwQ 32B).
Even if you ignore the hardware limitations, it’s unclear if software for running locally hosted LLMs will keep up with cloud-based subscription services. (Paid software for running local LLMs is a thing but, as far as I’m aware, only in the enterprise market.) For local LLMs to catch up with their cloud siblings, we’ll need software that’s easy to use and frequently updated with features close to what cloud services provide.
These problems will probably be fixed with time. But if you’re thinking about trying a local LLM on your laptop right now, don’t bother. It’s fun and novel but far from productive. I still recommend sticking with online-only models like GPT-4.5 and Claude 3.7 Sonnet for now.
Further reading: I paid $200/mo for ChatGPT Pro so you don’t have to