Multilingual Learning with an Ollama-Python Walkie-Talkie

Image by author using DALL-E 3.
We live in an era where the world is truly placed at our fingertips, if we know where to look. Today’s open-source large language models (LLMs) are potent and compact enough to place reasonably complete collections of human knowledge on standard consumer hardware, available for countless hours of ad-free, in-depth discussion on innumerable subjects without requiring an internet connection. Thanks to the dedicated efforts of the open-source community, tools like Ollama now allow us to serve high-quality quantized versions of today’s top models locally and interact with them using streamlined APIs.
This ease of development means we can spend less time thinking about how we might build LLM applications, and focus more on what we would like to build. Personally, I have always wanted to learn multiple languages, but never had the conditions to properly practice such a thing, as my life experience has not yet included a lot of time in multilingual environments, and attempts at touristic language learning can be embarrassing when we don’t have close friends to practice with, since we are forced to experiment on strangers.
This a promising opportunity for employing the open-ended dialogue capabilities of LLM-based chat bots. Since locally serving quantized open-source LLMs on consumer hardware is now a well-oiled machine, the only other ingredient we need to make this vision into a reality is to augment the interaction into a speech-to-speech format. Again, the bounties of open-source research avail themselves to us. High-quality speech-to-text and text-to-speech models are on the shelf, wrapped in their own intuitive APIs.
A perfect demonstration of how these tools can make exciting concepts come to life with ease is LingoNaut: a multilingual language assistant that runs from a single Python script containing just 300 lines of code. Using a combination of OpenAI’s Whisper speech-to-text model, a local Ollama server, and the Coqui.ai TTS text-to-speech library, we can construct a user-friendly walkie-talkie interface with a wide selection of LLMs. From there, it is just a matter of system prompt engineering (easily done with ollama-python) to beckon our desired behavior from the LLM, in this case creating a helpful multilingual language tutor. Indeed, this means the LingoNaut code can easily be adapted to create a wide range of AI assistants by just adjusting the LLM and system prompt being used.
Code for running LingoNaut is available in the GitHub repo with easy instructions for installation. LingoNaut is an open-source project, and contribution is welcomed. For example, future work could involve wrapping the backend in a more sophisticated web UI to allow remote hosting of walkie-talkie LLM apps, which could lead to supporting mobile devices. I hope that LingoNaut is a fun and helpful resource for others on their learning journeys, and that the code is useful as a lightweight skeleton for engineers sandboxing new ideas for LLM- or LMM-based applications.
The rest of this article provides an overview of the Python code that runs LingoNaut, the toolbox of open-source components that makes the ready assembly of a tool like LingoNaut possible, and promising directions for future work. With some clever Python coding tricks, brilliant speech-to-text and text-to-speech models, and the local deployment of quantized LLMs on consumer machines, we can easily construct a speech-to-speech pipeline to unlock use cases that are less conducive to the confines of text, such as language learning. The ingenious contributions of the research community combine to provide us this extraordinary set of possibilities. Let’s walk through each one in more detail to understand the roles they play in bringing the LingoNaut app to life.
LingoNaut Code

Image by author using DALL-E 3.
Walkie-Talkie Interface
The code in LingoNaut creates a handy terminal-based speech-to-speech app for use with Ollama which can be easily adapted for new use cases. Using a package called pynput, we can create a keyboard listener object that runs in a background thread and reacts to keystrokes from the user. This opens up a wide array of options for apps that run in continuous loops, most importantly in this case providing a control for triggering and terminating the user audio recording without the need for a graphic user interface with buttons. This way, an interactive app can be run directly from the terminal, easing many engineering concerns.
In LingoNaut, different speech-to-text models can be deployed by pressing different keys to record audio. While lightweight Whisper models excel at quickly processing English audio, a larger and slower model must be used for accurate on-the-fly multilingual transcription. Thus, the user may choose to hold the Ctrl key to use a lightweight base model for asking questions in English, or hold the Shift key to speak in other languages.
Other useful LingoNaut features enabled by the keyboard listener are the ability to interrupt the model response with the End key when you’ve given it a bad input or are not satisfied with the direction of the response. This prevents getting stuck waiting for irrelevant text and audio to finish coming through so that the user can stay more engaged. The user can also lock the keyboard inputs using the F2 key so they can leave a session open for later without worrying about triggering the audio recording accidentally.
Concurrency
While the packages used in LingoNaut provide streamlined APIs for interfacing with the three models used to create the speech-to-speech pipeline, naively waiting for the LLM to generate text, transcribing it to audio, and then playing it to the user in series would be a very slow experience. The streaming of text chunks from the LLM, the transcription of text chunks into audio files, and the playback of previously transcribed audio files can all happen concurrently, so LingoNaut uses a separate thread for each of these tasks. By using ThreadPoolExecutor objects with max_workers set to 1, we can easily open new threads for task submissions while guaranteeing those tasks will be executed in order, allowing us to outsource work from the main thread without having overlapping or shuffled returns. A basic code outline for this arrangement is shown below:
import ollama
from concurrent import ThreadPoolExecutor
def play_audio(file_path: str):
# audio file playback code
def dump_to_audio(text: str, file_path: str):
# transcribe text-to-speech and save audio file
def process_stream(chat_history: list):
stream = ollama.chat(
model='mistral:lingonaut',
messages=chat_history,
stream=True,
)
with ThreadPoolExecutor(max_workers=1) as play_pool:
with ThreadPoolExecutor(max_workers=1) as tts_pool:
def play_output(text, file_path):
output_path = dump_to_audio(text, file_path)
play_pool.submit(play_audio, output_path)
return
def process_section(text, file_path):
tts_pool.submit(play_output, text, file_path)
return current_string
current_section = ""
for i, chunk in enumerate(stream):
file_path = f"{i}.wav"
text_chunk = chunk['message']['content']
current_section += text_chunk
if len(current_section) > 50:
process_section(current_section)
current_section = ""
tts_pool.shutdown(wait=True)
play_pool.shutdown(wait=True)
Model Customization
The ollama-python package has an easy tool for creating custom tagged model configurations using “Modelfiles” to guide the LLM behavior. In the case of LingoNaut, the 4-bit quantized Mistral 7B model in the Ollama library was customized with an explicit system prompt to guide the desired behavior as a language learning assistant. The prompt can be found in the repository in the create_lingonaut_ollama.py file, and it should be noted that this is the only file that customizes the model selection and behavior in the repo, meaning that this repo can be instantly converted into any other walkie-talkie LLM application of your choosing by creating a tagged model using a different Modelfile. The LLM being used can also easily be swapped for larger or smaller models based on available resources.
Speech-to-Speech Toolbox

Image by author using DALL-E 3.
Whisper
Whisper is an open-source speech-to-text model provided by OpenAI. There are five model sizes available in both English-focused and multilingual varieties to choose from, depending on the complexity of the application and desired accuracy-efficiency tradeoff. Whisper is an end-to-end speech-to-text framework that uses an encoder-decoder transformer architecture operating on input audio split into 30-second chunks and converted into a log-Mel spectrogram. The network is trained on multiple speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection.
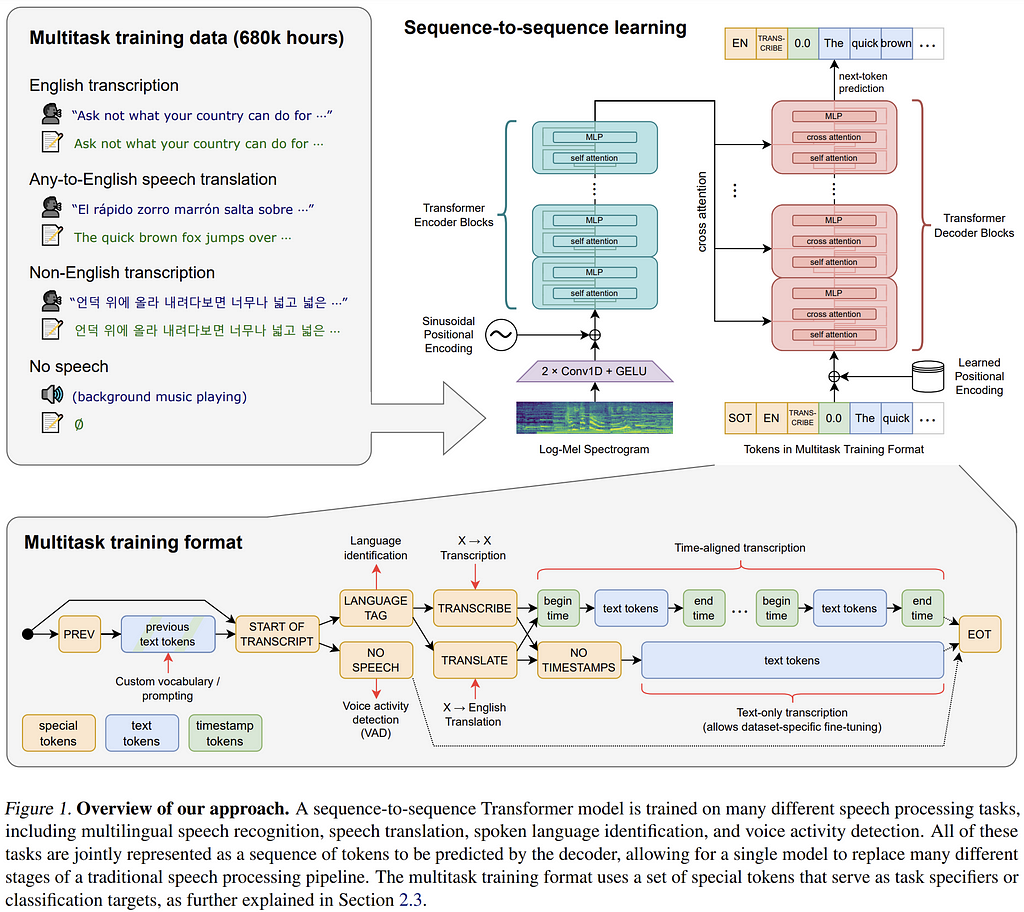
Diagram of Whisper architecture from the research paper.
For this project, two walkie-talkie buttons are available to the user: one which sends their general English-language questions to the bot through the lighter, faster “base” model, and a second which deploys the larger “medium” multilingual model that can distinguish between dozens of languages and accurately transcribe correctly pronounced statements. In the context of language learning, this leads the user to focus very intently on their pronunciation, accelerating the learning process. A chart of the available Whisper models is shown below:

Chart from https://github.com/openai/whisper
Ollama
There exists a variety of highly useful open-source language model interfaces, all catering to different use cases with varying levels of complexity for setup and use. Among the most widely known are the oobabooga text-gen webui, with arguably the most flexibility and under-the-hood control, llama.cpp, which originally focused on optimized deployment of quantized models on smaller CPU-only devices but has since expanded to serving other hardware types, and the streamlined interface chosen for this project (built on top of llama.cpp): Ollama.
Ollama focuses on simplicity and efficiency, running in the background and capable of serving multiple models simultaneously on small hardware, quickly shifting models in and out of memory as needed to serve their requests. Instead of focusing on lower-level tools like fine-tuning, Ollama excels at simple installation, efficient runtime, a great spread of ready-to-use models, and tools for importing pretrained model weights. The focus on efficiency and simplicity makes Ollama the natural choice for LLM interface in a project like LingoNaut, since the user does not need to remember to close their session to free up resources, as Ollama will automatically manage this in the background when the app is not in use. Further, the ready access to performant, quantized models in the library is perfect for frictionless development of LLM applications like LingoNaut.
While Ollama is not technically built for Windows, it is easy for Windows users to install it on Windows Subsystem for Linux (WSL), then communicate with the server from their Windows applications. With WSL installed, open a Linux terminal and enter the one-liner Ollama installation command. Once the installation finishes, simply run “ollama serve” in the Linux terminal, and you can then communicate with your Ollama server from any Python script on your Windows machine.
Coqui.ai ? TTS
TTS is a fully-loaded text-to-speech library available for non-commercial use, with paid commercial licenses available. The library has experienced notable popularity, with 3k forks and 26.6k stars on GitHub as of the time of this writing, and it’s clear why: the library works like the Ollama of the text-to-speech space, providing a unified interface for accessing a diverse array of performant models which cover a variety of use cases (for example: providing a multi-speaker, multilingual model for this project), exciting features such as voice cloning, and controls over the speed and emotional tone of transcriptions.
The TTS library provides an extensive selection of text-to-speech models, including the illustrious Fairseq models from Facebook research’s Massively Multilingual Speech (MMS) project. For LingoNaut, the Coqui.ai team’s own XTTS model turned out to be the correct choice, as it generates high-quality speech in multiple languages seamlessly. Although the model does have a “language” input parameter, I found that even leaving this set to “en” for English and simply passing text in other languages still results in faithful multilingual generation with mostly correct pronunciations.
Conclusion

Image by author using DALL-E 3.
In this article, I’ve introduced a new speech-to-speech multilingual language learning assistant called LingoNaut. The app runs through the terminal using a light and easily adaptable Python script with a walkie-talkie keyboard interface. This completely free and locally hosted app allows the user to practice a large variety of languages using AI, becoming confident in new languages without having to practice on strangers before they are ready. The code is available on GitHub with quick setup instructions, and is easily extensible to new use cases. I hope that the community finds the app helpful in their language learning endeavors, and that the code serves as a handy lightweight framework for future proof-of-concepts. LingoNaut is open-source, and contributions are welcomed.
Future Work
This work built a speech-to-speech pipeline by combining the text-based conversational ability of a LLM with separate speech-to-text and text-to-speech models on the input and output sides, respectively. Such a design is clunky and prone to cascading error, so it is therefore inferior to using a truly multimodal language model that could understand and generate both audio and text tokens from a unified representation space. When we encode audio to text before passing it to the model, we remove all of the tonal information contained in the audio, including pronunciation and emotional delivery, which significantly limits how advanced our language assistant can be. By instead using an LMM that operates on a joint multimodal representation space, we would retain the nuanced tonal information in the user inputs. Similarly, encoding text-to-speech on the output side is another significant information bottleneck, and the interaction will not be as natural.
The authors of NeXT-GPT provide a promising framework for using pretrained LLMs to create large multimodal models (LMMs) that can operate in a unified multimodal representation space, and this is a promising direction for speech-to-speech apps. With some effort, it is likely that the released NeXT-GPT weights could be imported into Ollama for experimentation. Their experiment used a similarly sized Vicuna 7B LLM, establishing that lightweight LLMs can work on multimodal spaces. While the Vicuna model is not advertised as a multilingual model, neither is the Mistral 7B model used in this LingoNaut experiment, though it still seems to work quite well for the purpose. Ideally, a fine-tuned multilingual instruction-tuned model would be the best choice for LingoNaut. To that end, a well-chosen dataset and low-rank adaptation (LoRA) would lead to likely success. Further, the parameter efficient multimodal alignment with lightweight adapters demonstrated by LaVIN offers to make NeXT-GPT-style LMM development more attainable with limited resources. A first step would be to investigate aligning the representations of a high-quality audio encoder with the LLM using LaVIN’s “cheap and quick” Mixture-of-Modality Adaptation (MMA) training strategy, relieving the speech-to-text bottleneck on the input side. Then the next step would be to investigate enabling multimodal output using the NeXT-GPT-style modality-switching instruction tuning (MoSIT).
Finally, as mentioned in the introduction, building a web UI frontend which could communicate with a remote backend would expand the fun of LingoNaut considerably, as larger models could be deployed on rented cloud GPUs, and communicated with via https requests from laptops and mobile devices. This would allow the community to build any walkie-talkie LLM app of their imagination that could be used their by friends and family anywhere an internet connection is available, and turn the vision of a universally accessible language learning assistant into a reality.

LingoNaut Language Assistant was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Image by author using DALL-E 3.
We live in an era where the world is truly placed at our fingertips, if we know where to look. Today’s open-source large language models (LLMs) are potent and compact enough to place reasonably complete collections of human knowledge on standard consumer hardware, available for countless hours of ad-free, in-depth discussion on innumerable subjects without requiring an internet connection. Thanks to the dedicated efforts of the open-source community, tools like Ollama now allow us to serve high-quality quantized versions of today’s top models locally and interact with them using streamlined APIs.
This ease of development means we can spend less time thinking about how we might build LLM applications, and focus more on what we would like to build. Personally, I have always wanted to learn multiple languages, but never had the conditions to properly practice such a thing, as my life experience has not yet included a lot of time in multilingual environments, and attempts at touristic language learning can be embarrassing when we don’t have close friends to practice with, since we are forced to experiment on strangers.
This a promising opportunity for employing the open-ended dialogue capabilities of LLM-based chat bots. Since locally serving quantized open-source LLMs on consumer hardware is now a well-oiled machine, the only other ingredient we need to make this vision into a reality is to augment the interaction into a speech-to-speech format. Again, the bounties of open-source research avail themselves to us. High-quality speech-to-text and text-to-speech models are on the shelf, wrapped in their own intuitive APIs.
A perfect demonstration of how these tools can make exciting concepts come to life with ease is LingoNaut: a multilingual language assistant that runs from a single Python script containing just 300 lines of code. Using a combination of OpenAI’s Whisper speech-to-text model, a local Ollama server, and the Coqui.ai TTS text-to-speech library, we can construct a user-friendly walkie-talkie interface with a wide selection of LLMs. From there, it is just a matter of system prompt engineering (easily done with ollama-python) to beckon our desired behavior from the LLM, in this case creating a helpful multilingual language tutor. Indeed, this means the LingoNaut code can easily be adapted to create a wide range of AI assistants by just adjusting the LLM and system prompt being used.
Code for running LingoNaut is available in the GitHub repo with easy instructions for installation. LingoNaut is an open-source project, and contribution is welcomed. For example, future work could involve wrapping the backend in a more sophisticated web UI to allow remote hosting of walkie-talkie LLM apps, which could lead to supporting mobile devices. I hope that LingoNaut is a fun and helpful resource for others on their learning journeys, and that the code is useful as a lightweight skeleton for engineers sandboxing new ideas for LLM- or LMM-based applications.
The rest of this article provides an overview of the Python code that runs LingoNaut, the toolbox of open-source components that makes the ready assembly of a tool like LingoNaut possible, and promising directions for future work. With some clever Python coding tricks, brilliant speech-to-text and text-to-speech models, and the local deployment of quantized LLMs on consumer machines, we can easily construct a speech-to-speech pipeline to unlock use cases that are less conducive to the confines of text, such as language learning. The ingenious contributions of the research community combine to provide us this extraordinary set of possibilities. Let’s walk through each one in more detail to understand the roles they play in bringing the LingoNaut app to life.
LingoNaut Code
Image by author using DALL-E 3.
Walkie-Talkie Interface
The code in LingoNaut creates a handy terminal-based speech-to-speech app for use with Ollama which can be easily adapted for new use cases. Using a package called pynput, we can create a keyboard listener object that runs in a background thread and reacts to keystrokes from the user. This opens up a wide array of options for apps that run in continuous loops, most importantly in this case providing a control for triggering and terminating the user audio recording without the need for a graphic user interface with buttons. This way, an interactive app can be run directly from the terminal, easing many engineering concerns.
In LingoNaut, different speech-to-text models can be deployed by pressing different keys to record audio. While lightweight Whisper models excel at quickly processing English audio, a larger and slower model must be used for accurate on-the-fly multilingual transcription. Thus, the user may choose to hold the Ctrl key to use a lightweight base model for asking questions in English, or hold the Shift key to speak in other languages.
Other useful LingoNaut features enabled by the keyboard listener are the ability to interrupt the model response with the End key when you’ve given it a bad input or are not satisfied with the direction of the response. This prevents getting stuck waiting for irrelevant text and audio to finish coming through so that the user can stay more engaged. The user can also lock the keyboard inputs using the F2 key so they can leave a session open for later without worrying about triggering the audio recording accidentally.
Concurrency
While the packages used in LingoNaut provide streamlined APIs for interfacing with the three models used to create the speech-to-speech pipeline, naively waiting for the LLM to generate text, transcribing it to audio, and then playing it to the user in series would be a very slow experience. The streaming of text chunks from the LLM, the transcription of text chunks into audio files, and the playback of previously transcribed audio files can all happen concurrently, so LingoNaut uses a separate thread for each of these tasks. By using ThreadPoolExecutor objects with max_workers set to 1, we can easily open new threads for task submissions while guaranteeing those tasks will be executed in order, allowing us to outsource work from the main thread without having overlapping or shuffled returns. A basic code outline for this arrangement is shown below:
import ollama
from concurrent import ThreadPoolExecutor
def play_audio(file_path: str):
# audio file playback code
def dump_to_audio(text: str, file_path: str):
# transcribe text-to-speech and save audio file
def process_stream(chat_history: list):
stream = ollama.chat(
model='mistral:lingonaut',
messages=chat_history,
stream=True,
)
with ThreadPoolExecutor(max_workers=1) as play_pool:
with ThreadPoolExecutor(max_workers=1) as tts_pool:
def play_output(text, file_path):
output_path = dump_to_audio(text, file_path)
play_pool.submit(play_audio, output_path)
return
def process_section(text, file_path):
tts_pool.submit(play_output, text, file_path)
return current_string
current_section = ""
for i, chunk in enumerate(stream):
file_path = f"{i}.wav"
text_chunk = chunk['message']['content']
current_section += text_chunk
if len(current_section) > 50:
process_section(current_section)
current_section = ""
tts_pool.shutdown(wait=True)
play_pool.shutdown(wait=True)
Model Customization
The ollama-python package has an easy tool for creating custom tagged model configurations using “Modelfiles” to guide the LLM behavior. In the case of LingoNaut, the 4-bit quantized Mistral 7B model in the Ollama library was customized with an explicit system prompt to guide the desired behavior as a language learning assistant. The prompt can be found in the repository in the create_lingonaut_ollama.py file, and it should be noted that this is the only file that customizes the model selection and behavior in the repo, meaning that this repo can be instantly converted into any other walkie-talkie LLM application of your choosing by creating a tagged model using a different Modelfile. The LLM being used can also easily be swapped for larger or smaller models based on available resources.
Speech-to-Speech Toolbox
Image by author using DALL-E 3.
Whisper
Whisper is an open-source speech-to-text model provided by OpenAI. There are five model sizes available in both English-focused and multilingual varieties to choose from, depending on the complexity of the application and desired accuracy-efficiency tradeoff. Whisper is an end-to-end speech-to-text framework that uses an encoder-decoder transformer architecture operating on input audio split into 30-second chunks and converted into a log-Mel spectrogram. The network is trained on multiple speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection.
Diagram of Whisper architecture from the research paper.
For this project, two walkie-talkie buttons are available to the user: one which sends their general English-language questions to the bot through the lighter, faster “base” model, and a second which deploys the larger “medium” multilingual model that can distinguish between dozens of languages and accurately transcribe correctly pronounced statements. In the context of language learning, this leads the user to focus very intently on their pronunciation, accelerating the learning process. A chart of the available Whisper models is shown below:
Chart from https://github.com/openai/whisper
Ollama
There exists a variety of highly useful open-source language model interfaces, all catering to different use cases with varying levels of complexity for setup and use. Among the most widely known are the oobabooga text-gen webui, with arguably the most flexibility and under-the-hood control, llama.cpp, which originally focused on optimized deployment of quantized models on smaller CPU-only devices but has since expanded to serving other hardware types, and the streamlined interface chosen for this project (built on top of llama.cpp): Ollama.
Ollama focuses on simplicity and efficiency, running in the background and capable of serving multiple models simultaneously on small hardware, quickly shifting models in and out of memory as needed to serve their requests. Instead of focusing on lower-level tools like fine-tuning, Ollama excels at simple installation, efficient runtime, a great spread of ready-to-use models, and tools for importing pretrained model weights. The focus on efficiency and simplicity makes Ollama the natural choice for LLM interface in a project like LingoNaut, since the user does not need to remember to close their session to free up resources, as Ollama will automatically manage this in the background when the app is not in use. Further, the ready access to performant, quantized models in the library is perfect for frictionless development of LLM applications like LingoNaut.
While Ollama is not technically built for Windows, it is easy for Windows users to install it on Windows Subsystem for Linux (WSL), then communicate with the server from their Windows applications. With WSL installed, open a Linux terminal and enter the one-liner Ollama installation command. Once the installation finishes, simply run “ollama serve” in the Linux terminal, and you can then communicate with your Ollama server from any Python script on your Windows machine.
Coqui.ai ? TTS
TTS is a fully-loaded text-to-speech library available for non-commercial use, with paid commercial licenses available. The library has experienced notable popularity, with 3k forks and 26.6k stars on GitHub as of the time of this writing, and it’s clear why: the library works like the Ollama of the text-to-speech space, providing a unified interface for accessing a diverse array of performant models which cover a variety of use cases (for example: providing a multi-speaker, multilingual model for this project), exciting features such as voice cloning, and controls over the speed and emotional tone of transcriptions.
The TTS library provides an extensive selection of text-to-speech models, including the illustrious Fairseq models from Facebook research’s Massively Multilingual Speech (MMS) project. For LingoNaut, the Coqui.ai team’s own XTTS model turned out to be the correct choice, as it generates high-quality speech in multiple languages seamlessly. Although the model does have a “language” input parameter, I found that even leaving this set to “en” for English and simply passing text in other languages still results in faithful multilingual generation with mostly correct pronunciations.
Conclusion
Image by author using DALL-E 3.
In this article, I’ve introduced a new speech-to-speech multilingual language learning assistant called LingoNaut. The app runs through the terminal using a light and easily adaptable Python script with a walkie-talkie keyboard interface. This completely free and locally hosted app allows the user to practice a large variety of languages using AI, becoming confident in new languages without having to practice on strangers before they are ready. The code is available on GitHub with quick setup instructions, and is easily extensible to new use cases. I hope that the community finds the app helpful in their language learning endeavors, and that the code serves as a handy lightweight framework for future proof-of-concepts. LingoNaut is open-source, and contributions are welcomed.
Future Work
This work built a speech-to-speech pipeline by combining the text-based conversational ability of a LLM with separate speech-to-text and text-to-speech models on the input and output sides, respectively. Such a design is clunky and prone to cascading error, so it is therefore inferior to using a truly multimodal language model that could understand and generate both audio and text tokens from a unified representation space. When we encode audio to text before passing it to the model, we remove all of the tonal information contained in the audio, including pronunciation and emotional delivery, which significantly limits how advanced our language assistant can be. By instead using an LMM that operates on a joint multimodal representation space, we would retain the nuanced tonal information in the user inputs. Similarly, encoding text-to-speech on the output side is another significant information bottleneck, and the interaction will not be as natural.
The authors of NeXT-GPT provide a promising framework for using pretrained LLMs to create large multimodal models (LMMs) that can operate in a unified multimodal representation space, and this is a promising direction for speech-to-speech apps. With some effort, it is likely that the released NeXT-GPT weights could be imported into Ollama for experimentation. Their experiment used a similarly sized Vicuna 7B LLM, establishing that lightweight LLMs can work on multimodal spaces. While the Vicuna model is not advertised as a multilingual model, neither is the Mistral 7B model used in this LingoNaut experiment, though it still seems to work quite well for the purpose. Ideally, a fine-tuned multilingual instruction-tuned model would be the best choice for LingoNaut. To that end, a well-chosen dataset and low-rank adaptation (LoRA) would lead to likely success. Further, the parameter efficient multimodal alignment with lightweight adapters demonstrated by LaVIN offers to make NeXT-GPT-style LMM development more attainable with limited resources. A first step would be to investigate aligning the representations of a high-quality audio encoder with the LLM using LaVIN’s “cheap and quick” Mixture-of-Modality Adaptation (MMA) training strategy, relieving the speech-to-text bottleneck on the input side. Then the next step would be to investigate enabling multimodal output using the NeXT-GPT-style modality-switching instruction tuning (MoSIT).
Finally, as mentioned in the introduction, building a web UI frontend which could communicate with a remote backend would expand the fun of LingoNaut considerably, as larger models could be deployed on rented cloud GPUs, and communicated with via https requests from laptops and mobile devices. This would allow the community to build any walkie-talkie LLM app of their imagination that could be used their by friends and family anywhere an internet connection is available, and turn the vision of a universally accessible language learning assistant into a reality.
LingoNaut Language Assistant was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.