A prompt-based experiment to improve both accuracy and transparent reasoning in content personalization.

Deliver relevant content to readers at the right time. Image by author.
At DER SPIEGEL, we are continually exploring ways to improve how we recommend news articles to our readers. In our latest (offline) experiment, we investigated whether Large Language Models (LLMs) could effectively predict which articles a reader would be interested in, based on their reading history.
Our Approach
We conducted a study with readers who participated in a survey where they rated their interest in various news articles. This gave us a ground truth of reader preferences. For each participant, we had two key pieces of information: their actual reading history (which articles they had read before taking the survey) and their ratings of a set of new articles in the survey. Read more about this mixed-methods approach to offline evaluation of news recommender systems here:
A Mixed-Methods Approach to Offline Evaluation of News Recommender Systems
We then used the Anthropic API to access Claude 3.5 Sonnet, a state-of-the-art language model, as our recommendation engine. For each reader, we provided the model with their reading history (news title and article summary) and asked it to predict how interested they would be in the articles from the survey. Here is the prompt we used:
You are a news recommendation system. Based on the user's reading history,
predict how likely they are to read new articles. Score each article from 0 to 1000,
where 1000 means highest likelihood to read.
Reading history (Previous articles read by the user):
[List of previously read articles with titles and summaries]
Please rate the following articles (provide a score 0-1000 for each):
[List of candidate articles to rate]
You must respond with a JSON object in this format:
{
"recommendations": [
{
"article_id": "article-id-here",
"score": score
}
]
}
With this approach, we can now compare the actual ratings from the survey against the score predictions from the LLM. This comparison provides an ideal dataset for evaluating the language model’s ability to predict reader interests.
Results and Key Findings
The findings were impressively strong. To understand the performance, we can look at two key metrics. First, the Precision@5: the LLM achieved a score of 56%, which means that when the system recommended its top 5 articles for a user (out of 15), on average (almost) 3 out of these 5 articles were actually among the articles that user rated highest in our survey. Looking at the distribution of these predictions reveals even more impressive results: for 24% of users, the system correctly identified at least 4 or 5 of their top articles. For another 41% of users, it correctly identified 3 out of their top 5 articles.
To put this in perspective, if we were to recommend articles randomly, we would only achieve 38.8% precision (see previous medium article for details). Even recommendations based purely on article popularity (recommending what most people read) only reach 42.1%, and our previous approach using an embedding-based technique achieved 45.4%.
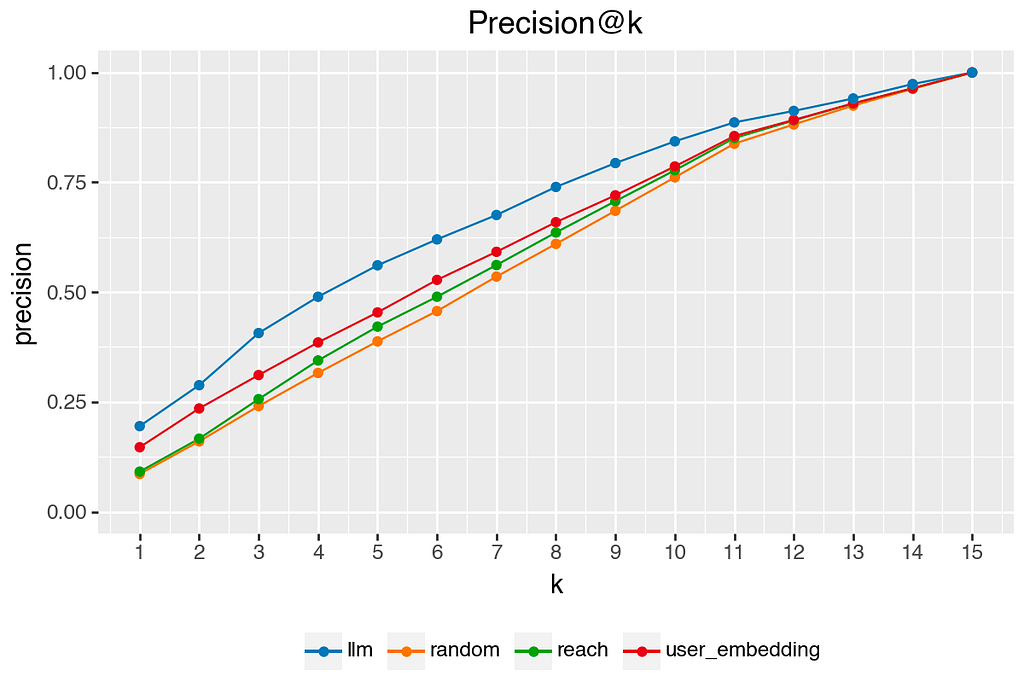
Graphic by author
The graphic below shows the uplift: While having any kind of knowledge about the users is better than guessing (random model), the LLM-based approach shows the strongest performance. Even compared to our sophisticated embedding-based logic, the LLM achieves a significant uplift in prediction accuracy.
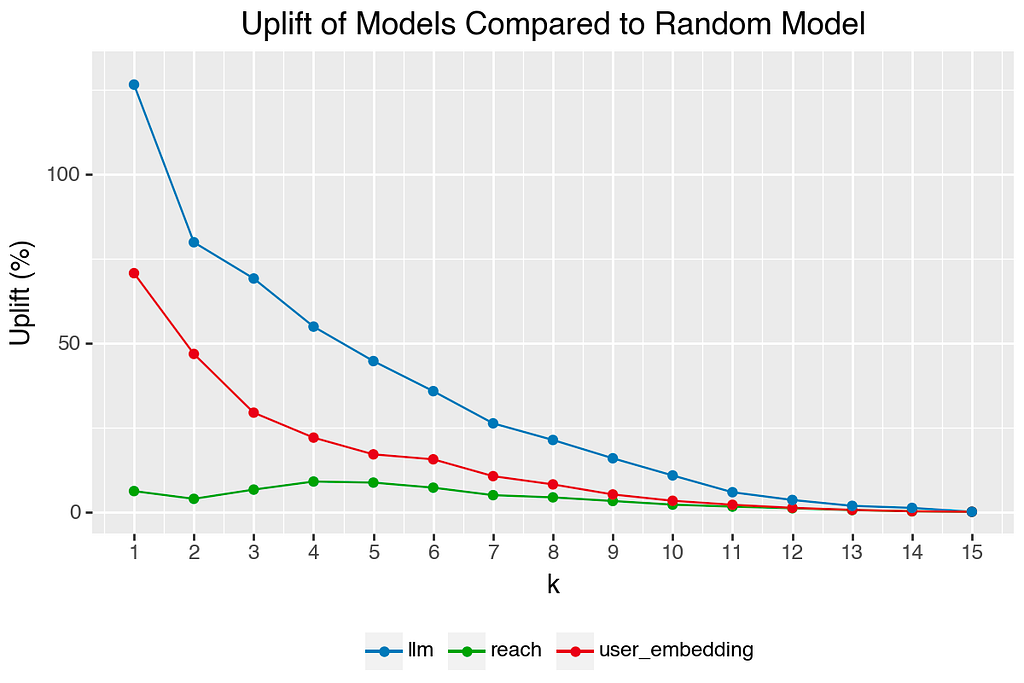
Graphic by author
As a second evaluation metric, we use Spearman correlation. At 0.41, it represents a substantial improvement over our embedding-based approach (0.17). This also shows that the LLM is not just better at finding relevant articles, but also at understanding how much a reader might prefer one article over another.
Beyond Performance: The Power of Explainability
What sets LLM-based recommendations apart is not just their performance but their ability to explain their decisions in natural language. Here is an example of how our system analyzes a user’s reading patterns and explains its recommendations (prompt not shown):
User has 221 articles in reading history
Top 5 Comparison:
--------------------------------------------------------------------------------
Top 5 Predicted by Claude:
1. Wie ich mit 38 Jahren zum ersten Mal lernte, strukturiert zu arbeiten (Score: 850, Actual Value: 253.0)
2. Warum wir den Umgang mit der Sonne neu lernen müssen (Score: 800, Actual Value: 757.0)
3. Lohnt sich ein Speicher für Solarstrom vom Balkon? (Score: 780, Actual Value: 586.0)
4. »Man muss sich fragen, ob dieser spezielle deutsche Weg wirklich intelligent ist« (Score: 750, Actual Value: 797.0)
5. Wie Bayern versucht, sein Drogenproblem unsichtbar zu machen (Score: 720, Actual Value: 766.0)
Actual Top 5 from Survey:
4. »Man muss sich fragen, ob dieser spezielle deutsche Weg wirklich intelligent ist« (Value: 797.0, Predicted Score: 750)
5. Wie Bayern versucht, sein Drogenproblem unsichtbar zu machen (Value: 766.0, Predicted Score: 720)
2. Warum wir den Umgang mit der Sonne neu lernen müssen (Value: 757.0, Predicted Score: 800)
6. Abitur als Lotterie? (Value: 601.0, Predicted Score: 650)
3. Lohnt sich ein Speicher für Solarstrom vom Balkon? (Value: 586.0, Predicted Score: 780)
Performance Metrics:
--------------------------------------------------------------------------------
Spearman Correlation: 0.673
Precision@5: 0.800
Claude's Analysis:
--------------------------------------------------------------------------------
1. Key patterns in user's reading history:
- Strong interest in social and political issues
- Regular engagement with lifestyle and personal development content
- Interest in health and wellness topics
- Frequent reading of articles about economic and financial matters
- Attraction to critical analysis and commentary pieces
- Interest in food and cooking content
2. Scoring explanation:
Highest scored articles:
- "Wie ich mit 38 Jahren zum ersten Mal lernte, strukturiert zu arbeiten" (850) - Aligns with the user's interest in personal development and lifestyle content
- "Warum wir den Umgang mit der Sonne neu lernen müssen" (800) - Matches interest in health and wellness topics
- "Lohnt sich ein Speicher für Solarstrom vom Balkon?" (780) - Corresponds to interest in practical advice and economic considerations
Medium scored articles:
- "Man muss sich fragen, ob dieser spezielle deutsche Weg wirklich intelligent ist" (750) - Fits pattern of interest in political commentary
- "Wie Bayern versucht, sein Drogenproblem unsichtbar zu machen" (720) - Matches interest in social issues and critical reporting
- "Abitur als Lotterie?" (650) - Aligns with interest in educational and social topics
Lower scored articles:
- "Eine Brise Formel 1" (550) - Limited sports content in reading history
- "Reizender Absatz" (450) - Less alignment with demonstrated interests
- "Hier wird jetzt auf ganz, ganz hohem Niveau gemeckert" (400) - Style and topic less aligned with user preferences
The scoring prioritizes articles that match the user's demonstrated interests in social issues, practical advice, and critical analysis while giving lower scores to sports and lighter content that appears less frequently in their reading history.
Rather than operating as a black box, the system could articulate why it thinks a particular article might be interesting to a reader: Because you frequently read articles about practical advice and economic matters, you might find this analysis about the cost-effectiveness of balcony solar storage particularly relevant. This kind of transparent reasoning could make recommendations feel more personal and trustworthy.
Conclusion
While our results are promising, several challenges need to be addressed. Due to long prompts (hundreds of article summaries per user), the most significant is cost. At about $0.21 per user for a single recommendation run, scaling this to full readerships would be irresponsibly expensive. Testing high-performing open-source models, could potentially reduce these costs. Additionally, the current implementation is relatively slow, taking several seconds per user. For a news platform where content updates frequently and reader interests evolve sometimes even throughout a single day, we would need to run these recommendations multiple times daily to stay relevant.
Furthermore, we used a single, straightforward prompt without any prompt engineering or optimization. There is likely (significant) room for improvement through systematic prompt refinement.[1] Additionally, our current implementation only uses article titles and summaries, without leveraging available metadata. We could potentially increase the performance by incorporating additional signals such as reading time per article (how long users spent reading each piece) or overall article popularity. Anyhow, due to high API costs, running iterative evaluation pipelines is currently not an option.
All in all, the combination of strong predictive performance and natural language explanations suggests that LLMs will be a valuable tool in news recommendation systems. And beyond recommendations, they add a new way on how we analyze user journeys in digital news. Their ability to process and interpret reading histories alongside metadata opens up exciting possibilities: from understanding content journeys and topic progressions to creating personalized review summaries.
Thanks for reading 🙏
I hope you liked it, if so, just make it clap. Please do not hesitate to connect with me on LinkedIn for further discussion or questions.
As a data scientist at DER SPIEGEL, I have authorized access to proprietary user data and click histories, which form the basis of this study. This data is not publicly available. All presented results are aggregated and anonymized to protect user privacy while showcasing our methodological approach to news recommendation.
References
[1] Dairui, Liu & Yang, Boming & Du, Honghui & Greene, Derek & Hurley, Neil & Lawlor, Aonghus & Dong, Ruihai & Li, Irene. (2024). RecPrompt: A Self-tuning Prompting Framework for News Recommendation Using Large Language Models.

Making News Recommendations Explainable with Large Language Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Deliver relevant content to readers at the right time. Image by author.
At DER SPIEGEL, we are continually exploring ways to improve how we recommend news articles to our readers. In our latest (offline) experiment, we investigated whether Large Language Models (LLMs) could effectively predict which articles a reader would be interested in, based on their reading history.
Our Approach
We conducted a study with readers who participated in a survey where they rated their interest in various news articles. This gave us a ground truth of reader preferences. For each participant, we had two key pieces of information: their actual reading history (which articles they had read before taking the survey) and their ratings of a set of new articles in the survey. Read more about this mixed-methods approach to offline evaluation of news recommender systems here:
A Mixed-Methods Approach to Offline Evaluation of News Recommender Systems
We then used the Anthropic API to access Claude 3.5 Sonnet, a state-of-the-art language model, as our recommendation engine. For each reader, we provided the model with their reading history (news title and article summary) and asked it to predict how interested they would be in the articles from the survey. Here is the prompt we used:
You are a news recommendation system. Based on the user's reading history,
predict how likely they are to read new articles. Score each article from 0 to 1000,
where 1000 means highest likelihood to read.
Reading history (Previous articles read by the user):
[List of previously read articles with titles and summaries]
Please rate the following articles (provide a score 0-1000 for each):
[List of candidate articles to rate]
You must respond with a JSON object in this format:
{
"recommendations": [
{
"article_id": "article-id-here",
"score": score
}
]
}
With this approach, we can now compare the actual ratings from the survey against the score predictions from the LLM. This comparison provides an ideal dataset for evaluating the language model’s ability to predict reader interests.
Results and Key Findings
The findings were impressively strong. To understand the performance, we can look at two key metrics. First, the Precision@5: the LLM achieved a score of 56%, which means that when the system recommended its top 5 articles for a user (out of 15), on average (almost) 3 out of these 5 articles were actually among the articles that user rated highest in our survey. Looking at the distribution of these predictions reveals even more impressive results: for 24% of users, the system correctly identified at least 4 or 5 of their top articles. For another 41% of users, it correctly identified 3 out of their top 5 articles.
To put this in perspective, if we were to recommend articles randomly, we would only achieve 38.8% precision (see previous medium article for details). Even recommendations based purely on article popularity (recommending what most people read) only reach 42.1%, and our previous approach using an embedding-based technique achieved 45.4%.
Graphic by author
The graphic below shows the uplift: While having any kind of knowledge about the users is better than guessing (random model), the LLM-based approach shows the strongest performance. Even compared to our sophisticated embedding-based logic, the LLM achieves a significant uplift in prediction accuracy.
Graphic by author
As a second evaluation metric, we use Spearman correlation. At 0.41, it represents a substantial improvement over our embedding-based approach (0.17). This also shows that the LLM is not just better at finding relevant articles, but also at understanding how much a reader might prefer one article over another.
Beyond Performance: The Power of Explainability
What sets LLM-based recommendations apart is not just their performance but their ability to explain their decisions in natural language. Here is an example of how our system analyzes a user’s reading patterns and explains its recommendations (prompt not shown):
User has 221 articles in reading history
Top 5 Comparison:
--------------------------------------------------------------------------------
Top 5 Predicted by Claude:
1. Wie ich mit 38 Jahren zum ersten Mal lernte, strukturiert zu arbeiten (Score: 850, Actual Value: 253.0)
2. Warum wir den Umgang mit der Sonne neu lernen müssen (Score: 800, Actual Value: 757.0)
3. Lohnt sich ein Speicher für Solarstrom vom Balkon? (Score: 780, Actual Value: 586.0)
4. »Man muss sich fragen, ob dieser spezielle deutsche Weg wirklich intelligent ist« (Score: 750, Actual Value: 797.0)
5. Wie Bayern versucht, sein Drogenproblem unsichtbar zu machen (Score: 720, Actual Value: 766.0)
Actual Top 5 from Survey:
4. »Man muss sich fragen, ob dieser spezielle deutsche Weg wirklich intelligent ist« (Value: 797.0, Predicted Score: 750)
5. Wie Bayern versucht, sein Drogenproblem unsichtbar zu machen (Value: 766.0, Predicted Score: 720)
2. Warum wir den Umgang mit der Sonne neu lernen müssen (Value: 757.0, Predicted Score: 800)
6. Abitur als Lotterie? (Value: 601.0, Predicted Score: 650)
3. Lohnt sich ein Speicher für Solarstrom vom Balkon? (Value: 586.0, Predicted Score: 780)
Performance Metrics:
--------------------------------------------------------------------------------
Spearman Correlation: 0.673
Precision@5: 0.800
Claude's Analysis:
--------------------------------------------------------------------------------
1. Key patterns in user's reading history:
- Strong interest in social and political issues
- Regular engagement with lifestyle and personal development content
- Interest in health and wellness topics
- Frequent reading of articles about economic and financial matters
- Attraction to critical analysis and commentary pieces
- Interest in food and cooking content
2. Scoring explanation:
Highest scored articles:
- "Wie ich mit 38 Jahren zum ersten Mal lernte, strukturiert zu arbeiten" (850) - Aligns with the user's interest in personal development and lifestyle content
- "Warum wir den Umgang mit der Sonne neu lernen müssen" (800) - Matches interest in health and wellness topics
- "Lohnt sich ein Speicher für Solarstrom vom Balkon?" (780) - Corresponds to interest in practical advice and economic considerations
Medium scored articles:
- "Man muss sich fragen, ob dieser spezielle deutsche Weg wirklich intelligent ist" (750) - Fits pattern of interest in political commentary
- "Wie Bayern versucht, sein Drogenproblem unsichtbar zu machen" (720) - Matches interest in social issues and critical reporting
- "Abitur als Lotterie?" (650) - Aligns with interest in educational and social topics
Lower scored articles:
- "Eine Brise Formel 1" (550) - Limited sports content in reading history
- "Reizender Absatz" (450) - Less alignment with demonstrated interests
- "Hier wird jetzt auf ganz, ganz hohem Niveau gemeckert" (400) - Style and topic less aligned with user preferences
The scoring prioritizes articles that match the user's demonstrated interests in social issues, practical advice, and critical analysis while giving lower scores to sports and lighter content that appears less frequently in their reading history.
Rather than operating as a black box, the system could articulate why it thinks a particular article might be interesting to a reader: Because you frequently read articles about practical advice and economic matters, you might find this analysis about the cost-effectiveness of balcony solar storage particularly relevant. This kind of transparent reasoning could make recommendations feel more personal and trustworthy.
Conclusion
While our results are promising, several challenges need to be addressed. Due to long prompts (hundreds of article summaries per user), the most significant is cost. At about $0.21 per user for a single recommendation run, scaling this to full readerships would be irresponsibly expensive. Testing high-performing open-source models, could potentially reduce these costs. Additionally, the current implementation is relatively slow, taking several seconds per user. For a news platform where content updates frequently and reader interests evolve sometimes even throughout a single day, we would need to run these recommendations multiple times daily to stay relevant.
Furthermore, we used a single, straightforward prompt without any prompt engineering or optimization. There is likely (significant) room for improvement through systematic prompt refinement.[1] Additionally, our current implementation only uses article titles and summaries, without leveraging available metadata. We could potentially increase the performance by incorporating additional signals such as reading time per article (how long users spent reading each piece) or overall article popularity. Anyhow, due to high API costs, running iterative evaluation pipelines is currently not an option.
All in all, the combination of strong predictive performance and natural language explanations suggests that LLMs will be a valuable tool in news recommendation systems. And beyond recommendations, they add a new way on how we analyze user journeys in digital news. Their ability to process and interpret reading histories alongside metadata opens up exciting possibilities: from understanding content journeys and topic progressions to creating personalized review summaries.
Thanks for reading 🙏
I hope you liked it, if so, just make it clap. Please do not hesitate to connect with me on LinkedIn for further discussion or questions.
As a data scientist at DER SPIEGEL, I have authorized access to proprietary user data and click histories, which form the basis of this study. This data is not publicly available. All presented results are aggregated and anonymized to protect user privacy while showcasing our methodological approach to news recommendation.
References
[1] Dairui, Liu & Yang, Boming & Du, Honghui & Greene, Derek & Hurley, Neil & Lawlor, Aonghus & Dong, Ruihai & Li, Irene. (2024). RecPrompt: A Self-tuning Prompting Framework for News Recommendation Using Large Language Models.
Making News Recommendations Explainable with Large Language Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.