Finding high-value patterns in transactions
In this post, I will give an alternative to popular techniques in market basket analysis that can help practitioners find high-value patterns rather than just the most frequent ones. We will gain some intuition into different pattern mining problems and look at a real-world example. The full code can be found here. All images are created by the author.
Introduction
I have written a more introductory article about pattern mining already; if you’re not familiar with some of the concepts that come up here, feel free to check that one out first.
In short, pattern mining tries to find patterns in data (duuh). Most of the time, this data comes in the form of (multi-)sets or sequences. In my last article, for example, I looked at the sequence of actions that a user performs on a website. In this case, we would care about the ordering of the items.
In other cases, such as the one we will discuss below, we do not care about the ordering of the items. We only list all the items that were in the transaction and how often they appeared.
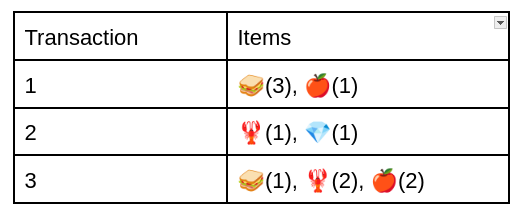
Example Transacton Database
So for example, transaction 1 contained 🥪 3 times and 🍎 once. As we see, we lose information about the ordering of the items, but in many scenarios (as the one we will discuss below), there is no logical ordering of the items. This is similar to a bag of words in NLP.
Market Basket Analysis
Market Basket Analysis (MBA) is a data analysis technique commonly used in retail and marketing to uncover relationships between products that customers tend to purchase together. It aims to identify patterns in customers’ shopping baskets or transactions by analyzing their purchasing behavior. The central idea is to understand the co-occurrence of items in shopping transactions, which helps businesses optimize their strategies for product placement, cross-selling, and targeted marketing campaigns.
Frequent Itemset Mining
Frequent Itemset Mining (FIM) is the process of finding frequent patterns in transaction databases. We can look at the frequency of a pattern (i.e. a set of items) by calculating its support. In other words, the support of a pattern X is the number of transactions T that contain X (and are in the database D). That is, we are simply looking at how often the pattern X appears in the database.
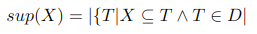
Definition of the support.
In FIM, we then want to find all the sequences that have a support bigger than some threshold (often called minsup). If the support of a sequence is higher than minsup, it is considered frequent.
Limitations
In FIM, we only look at the existence of an item in a sequence. That is, whether an item appears two times or 200 times does not matter, we simply represent it as a one. But we often have cases (such as MBA), where not only the existence of an item in a transaction is relevant but also how many times it appeared in the transaction.
Another problem is that frequency does not always imply relevance. In that sense, FIM assumes that all items in the transaction are equally important. However, it is reasonable to assume that someone buying caviar might be more important for a business than someone buying bread, as caviar is potentially a high ROI/profit item.
High Utility Itemset Mining
These limitations directly bring us to High Utility Itemset Mining (HUIM) and High Utility Quantitative Itemset Mining (HUQIM) which are generalizations of FIM that try to address some of the problems of normal FIM.
Our first generalization is that items can appear more than once in a transaction (i.e. we have a multiset instead of a simple set). As said before, in normal itemset mining, we transform the transaction into a set and only look at whether the item exists in the transaction or not. So for example the two transactions below would have the same representation.
t1 = [a,a,a,a,a,b] # repr. as {a,b} in FIM
t2 = [a,b] # repr. as {a,b} in FIM
Above, both these two transactions would be represented as [a,b] in regular FIM. We quickly see that, in some cases, we could miss important details. For example, if a and b were some items in a customer’s shopping cart, it would matter a lot whether we have a (e.g. a loaf of bread) five times or only once. Therefore, we represent the transaction as a multiset in which we write down, how many times each item appeared.
# multiset representation
t1_ms = {(a,5),(b,1)}
t2_ms = {(a,1),(b,1)}
This is also efficient if the items can appear in a large number of items (e.g. 100 or 1000 times). In that case, we need not write down all the a’s or b’s but simply how often they appear.
The generalization that both the quantitative and non-quantitative methods make, is to assign every item in the transaction a utility (e.g. profit or time). Below, we have a table that assigns every possible item a unit profit.
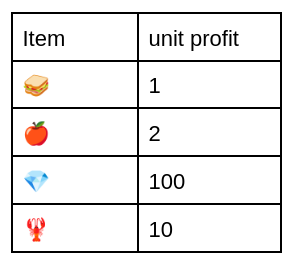
Utility of Items
We can then calculate the utility of a specific pattern such as {🥪, 🍎} by summing up the utility of those items in the transactions that contain them. In our example we would have:
(3🥪 * $1 + 1🍎 * $2) +
(1 🥪 * $1 + 2🍎 * $2) = $10
Transacton Database from Above
So, we get that this pattern has a utility of $10. With FIM, we had the task of finding frequent patterns. Now, we have to find patterns with high utility. This is mainly because we assume that frequency does not imply importance. In regular FIM, we might have missed rare (infrequent) patterns that provide a high utility (e.g. the diamond), which is not true with HUIM.
We also need to define the notion of a transaction utility. This is simply the sum of the utility of all the items in the transaction. For our transaction 3 in the database, this would be
1🥪 * $1 + 2🦞*$10 + 2🍎*$2 = $25
Note that solving this problem and finding all high-utility items is more difficult than regular FPM. This is because the utility does not follow the Apriori property.
The Apriori Property
Let X and Y be two patterns occurring in a transaction database D. The apriori property says that if X is a subset of Y, then the support of X must be at least as big as Y's.
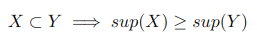
Apriori property.
This means that if a subset of Y is infrequent, Y itself must be infrequent since it must have a smaller support. Let’s say we have X = {a} and Y = {a,b}. If Y appears 4 times in our database, then X must appear at least 4 times, since X is a subset of Y. This makes sense since we are making the pattern less general / more specific by adding an item which means that it will fit less transactions. This property is used in most algorithms as it implies that if {a} is infrequent all supersets are also infrequent and we can eliminate them from the search space [3].
This property does not hold when we are talking about utility. A superset Y of transaction X could have more or less utility. If we take the example from above, {🥪} has a utility of $4. But this does not mean we cannot look at supersets of this pattern. For example, the superset we looked at {🥪, 🍎} has a higher utility of $10. At the same time, a superset of a pattern won’t always have more utility since it might be that this superset just doesn’t appear very often in the DB.
Idea Behind HUIM
Since we can’t use the apriori property for HUIM directly, we have to come up with some other upper bound for narrowing down the search space. One such bound is called Transaction-Weighted Utilization (TWU). To calculate it, we sum up the transaction utility of the transactions that contain the pattern X of interest. Any superset Y of X can’t have a higher utility than the TWU. Let’s make this clearer with an example. The TWU of {🥪,🍎} is $30 ($5 from transaction 1 and $5 from transaction 3). When we look at a superset pattern Y such as {🥪 🦞 🍎} we can see that there is no way it would have more utility since all transactions that have Y in them also have X in them.
There are now various algorithms for solving HUIM. All of them receive a minimum utility and produce the patterns that have at least that utility as their output. In this case, I have used the EFIM algorithm since it is fast and memory efficient.
Implementation
For this article, I will work with the Market Basket Analysis dataset from Kaggle (used with permission from the original dataset author).
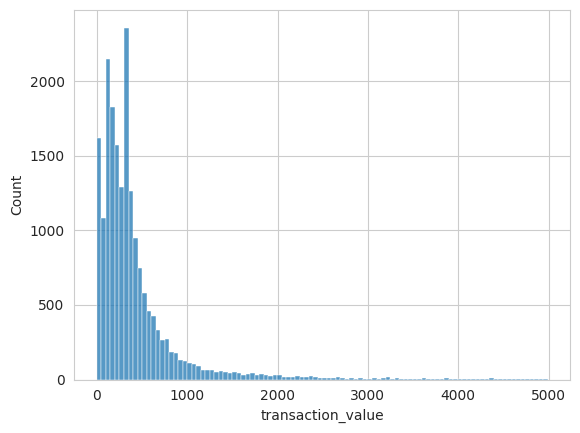
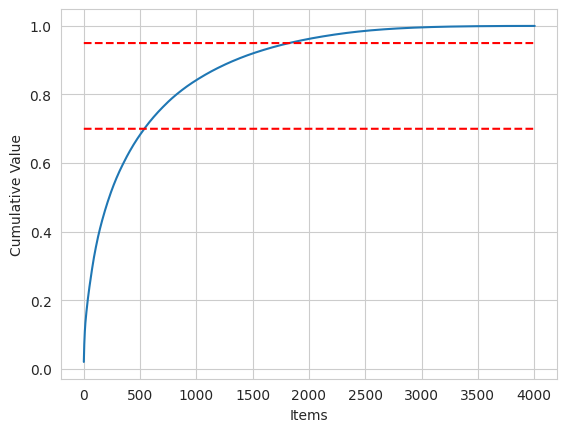
Above, we can see the distribution of transaction values found in the data. There is a total of around 19,500 transactions with an average transaction value of $526 and 26 distinct items per transaction. In total, there are around 4000 unique items. We can also make an ABC analysis where we put items into different buckets depending on their share of total revenue. We can see that around 500 of the 4000 items make up around 70% of the revenue (A-items). We then have a long right-tail of items (around 2250) that make up around 5% of the revenue (C-items).
Preprocessing
The initial data is in a long format where each row is a line item within a bill. From the BillNo we can see to which transaction the item belongs.
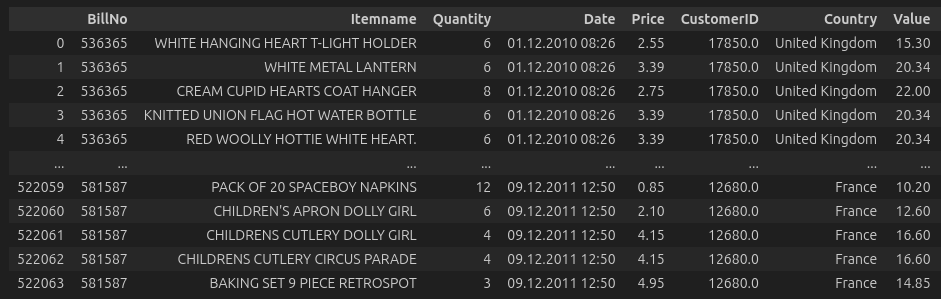
Initial Data Format
After some preprocessing, we get the data into the format required by PAMI which is the Python library we are going to use for applying the EFIM algorithm.
data['item_id'] = pd.factorize(data.Itemname)[0].astype(str) # map item names to id
data["Value_Int"] = data["Value"].astype(int).astype(str)
data = data.loc[data.Value_Int != '0'] # exclude items w/o utility
transaction_db = data.groupby('BillNo').agg(
items=('item_id', lambda x: ' '.join(list(x))),
total_value=('Value', lambda x: int(x.sum())),
values=('Value_Int', lambda x: ' '.join(list(x))),
)
# filter out long transactions, only use subset of transactions
transaction_db = transaction_db.loc[transaction_db.num_items < 10].iloc[:1000]
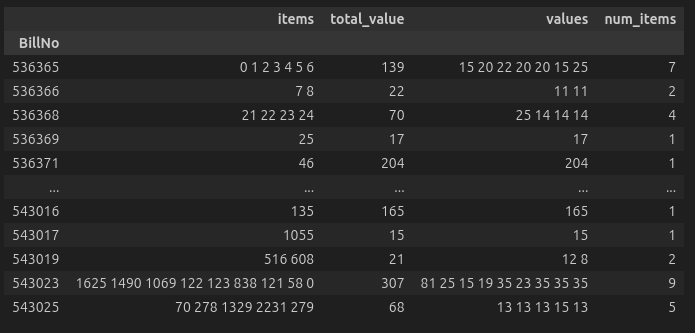
Transaction Database
We can then apply the EFIM algorithm.
import PAMI.highUtilityPattern.basic.EFIM as efim
obj = efim.EFIM('tdb.csv', minUtil=1000, sep=' ')
obj.startMine() #start the mining process
obj.save('out.txt') #store the patterns in file
results = obj.getPatternsAsDataFrame() #Get the patterns discovered into a dataframe
obj.printResults()
The algorithm then returns a list of patterns that meet this minimum utility criterion.

This is the point at which a subject matter expert would have to look at these patterns to see if there is something worth taking a closer look at. We can for example see that the combination of VINTAGE BEAD PINK PURSE’ and ‘ANT COPPER RED BOUDICCA BRACELET’ seems to perform quite well. In that case, we might think about offering these items as a bundle or recommending them together.
Conclusion
In this blog post, we looked at classical FIM and its limitations. Especially when we care about the transaction value of a pattern and the potential revenue it can provide, it can be beneficial to use HUIM and mine patterns with high utility.
Resources & Further Reading

Market Basket Analysis Using High Utility Itemset Mining was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
In this post, I will give an alternative to popular techniques in market basket analysis that can help practitioners find high-value patterns rather than just the most frequent ones. We will gain some intuition into different pattern mining problems and look at a real-world example. The full code can be found here. All images are created by the author.
Introduction
I have written a more introductory article about pattern mining already; if you’re not familiar with some of the concepts that come up here, feel free to check that one out first.
In short, pattern mining tries to find patterns in data (duuh). Most of the time, this data comes in the form of (multi-)sets or sequences. In my last article, for example, I looked at the sequence of actions that a user performs on a website. In this case, we would care about the ordering of the items.
In other cases, such as the one we will discuss below, we do not care about the ordering of the items. We only list all the items that were in the transaction and how often they appeared.
Example Transacton Database
So for example, transaction 1 contained 🥪 3 times and 🍎 once. As we see, we lose information about the ordering of the items, but in many scenarios (as the one we will discuss below), there is no logical ordering of the items. This is similar to a bag of words in NLP.
Market Basket Analysis
Market Basket Analysis (MBA) is a data analysis technique commonly used in retail and marketing to uncover relationships between products that customers tend to purchase together. It aims to identify patterns in customers’ shopping baskets or transactions by analyzing their purchasing behavior. The central idea is to understand the co-occurrence of items in shopping transactions, which helps businesses optimize their strategies for product placement, cross-selling, and targeted marketing campaigns.
Frequent Itemset Mining
Frequent Itemset Mining (FIM) is the process of finding frequent patterns in transaction databases. We can look at the frequency of a pattern (i.e. a set of items) by calculating its support. In other words, the support of a pattern X is the number of transactions T that contain X (and are in the database D). That is, we are simply looking at how often the pattern X appears in the database.
Definition of the support.
In FIM, we then want to find all the sequences that have a support bigger than some threshold (often called minsup). If the support of a sequence is higher than minsup, it is considered frequent.
Limitations
In FIM, we only look at the existence of an item in a sequence. That is, whether an item appears two times or 200 times does not matter, we simply represent it as a one. But we often have cases (such as MBA), where not only the existence of an item in a transaction is relevant but also how many times it appeared in the transaction.
Another problem is that frequency does not always imply relevance. In that sense, FIM assumes that all items in the transaction are equally important. However, it is reasonable to assume that someone buying caviar might be more important for a business than someone buying bread, as caviar is potentially a high ROI/profit item.
High Utility Itemset Mining
These limitations directly bring us to High Utility Itemset Mining (HUIM) and High Utility Quantitative Itemset Mining (HUQIM) which are generalizations of FIM that try to address some of the problems of normal FIM.
Our first generalization is that items can appear more than once in a transaction (i.e. we have a multiset instead of a simple set). As said before, in normal itemset mining, we transform the transaction into a set and only look at whether the item exists in the transaction or not. So for example the two transactions below would have the same representation.
t1 = [a,a,a,a,a,b] # repr. as {a,b} in FIM
t2 = [a,b] # repr. as {a,b} in FIM
Above, both these two transactions would be represented as [a,b] in regular FIM. We quickly see that, in some cases, we could miss important details. For example, if a and b were some items in a customer’s shopping cart, it would matter a lot whether we have a (e.g. a loaf of bread) five times or only once. Therefore, we represent the transaction as a multiset in which we write down, how many times each item appeared.
# multiset representation
t1_ms = {(a,5),(b,1)}
t2_ms = {(a,1),(b,1)}
This is also efficient if the items can appear in a large number of items (e.g. 100 or 1000 times). In that case, we need not write down all the a’s or b’s but simply how often they appear.
The generalization that both the quantitative and non-quantitative methods make, is to assign every item in the transaction a utility (e.g. profit or time). Below, we have a table that assigns every possible item a unit profit.
Utility of Items
We can then calculate the utility of a specific pattern such as {🥪, 🍎} by summing up the utility of those items in the transactions that contain them. In our example we would have:
(3🥪 * $1 + 1🍎 * $2) +
(1 🥪 * $1 + 2🍎 * $2) = $10
Transacton Database from Above
So, we get that this pattern has a utility of $10. With FIM, we had the task of finding frequent patterns. Now, we have to find patterns with high utility. This is mainly because we assume that frequency does not imply importance. In regular FIM, we might have missed rare (infrequent) patterns that provide a high utility (e.g. the diamond), which is not true with HUIM.
We also need to define the notion of a transaction utility. This is simply the sum of the utility of all the items in the transaction. For our transaction 3 in the database, this would be
1🥪 * $1 + 2🦞*$10 + 2🍎*$2 = $25
Note that solving this problem and finding all high-utility items is more difficult than regular FPM. This is because the utility does not follow the Apriori property.
The Apriori Property
Let X and Y be two patterns occurring in a transaction database D. The apriori property says that if X is a subset of Y, then the support of X must be at least as big as Y's.
Apriori property.
This means that if a subset of Y is infrequent, Y itself must be infrequent since it must have a smaller support. Let’s say we have X = {a} and Y = {a,b}. If Y appears 4 times in our database, then X must appear at least 4 times, since X is a subset of Y. This makes sense since we are making the pattern less general / more specific by adding an item which means that it will fit less transactions. This property is used in most algorithms as it implies that if {a} is infrequent all supersets are also infrequent and we can eliminate them from the search space [3].
This property does not hold when we are talking about utility. A superset Y of transaction X could have more or less utility. If we take the example from above, {🥪} has a utility of $4. But this does not mean we cannot look at supersets of this pattern. For example, the superset we looked at {🥪, 🍎} has a higher utility of $10. At the same time, a superset of a pattern won’t always have more utility since it might be that this superset just doesn’t appear very often in the DB.
Idea Behind HUIM
Since we can’t use the apriori property for HUIM directly, we have to come up with some other upper bound for narrowing down the search space. One such bound is called Transaction-Weighted Utilization (TWU). To calculate it, we sum up the transaction utility of the transactions that contain the pattern X of interest. Any superset Y of X can’t have a higher utility than the TWU. Let’s make this clearer with an example. The TWU of {🥪,🍎} is $30 ($5 from transaction 1 and $5 from transaction 3). When we look at a superset pattern Y such as {🥪 🦞 🍎} we can see that there is no way it would have more utility since all transactions that have Y in them also have X in them.
There are now various algorithms for solving HUIM. All of them receive a minimum utility and produce the patterns that have at least that utility as their output. In this case, I have used the EFIM algorithm since it is fast and memory efficient.
Implementation
For this article, I will work with the Market Basket Analysis dataset from Kaggle (used with permission from the original dataset author).
Above, we can see the distribution of transaction values found in the data. There is a total of around 19,500 transactions with an average transaction value of $526 and 26 distinct items per transaction. In total, there are around 4000 unique items. We can also make an ABC analysis where we put items into different buckets depending on their share of total revenue. We can see that around 500 of the 4000 items make up around 70% of the revenue (A-items). We then have a long right-tail of items (around 2250) that make up around 5% of the revenue (C-items).
Preprocessing
The initial data is in a long format where each row is a line item within a bill. From the BillNo we can see to which transaction the item belongs.
Initial Data Format
After some preprocessing, we get the data into the format required by PAMI which is the Python library we are going to use for applying the EFIM algorithm.
data['item_id'] = pd.factorize(data.Itemname)[0].astype(str) # map item names to id
data["Value_Int"] = data["Value"].astype(int).astype(str)
data = data.loc[data.Value_Int != '0'] # exclude items w/o utility
transaction_db = data.groupby('BillNo').agg(
items=('item_id', lambda x: ' '.join(list(x))),
total_value=('Value', lambda x: int(x.sum())),
values=('Value_Int', lambda x: ' '.join(list(x))),
)
# filter out long transactions, only use subset of transactions
transaction_db = transaction_db.loc[transaction_db.num_items < 10].iloc[:1000]
Transaction Database
We can then apply the EFIM algorithm.
import PAMI.highUtilityPattern.basic.EFIM as efim
obj = efim.EFIM('tdb.csv', minUtil=1000, sep=' ')
obj.startMine() #start the mining process
obj.save('out.txt') #store the patterns in file
results = obj.getPatternsAsDataFrame() #Get the patterns discovered into a dataframe
obj.printResults()
The algorithm then returns a list of patterns that meet this minimum utility criterion.
This is the point at which a subject matter expert would have to look at these patterns to see if there is something worth taking a closer look at. We can for example see that the combination of VINTAGE BEAD PINK PURSE’ and ‘ANT COPPER RED BOUDICCA BRACELET’ seems to perform quite well. In that case, we might think about offering these items as a bundle or recommending them together.
Conclusion
In this blog post, we looked at classical FIM and its limitations. Especially when we care about the transaction value of a pattern and the potential revenue it can provide, it can be beneficial to use HUIM and mine patterns with high utility.
Resources & Further Reading
- [1] High Utility Itemset Mining
- [2] The Pattern Mining Course
- [3] EFIM: A Fast and Memory Efficient Algorithm for High-Utility Itemset Mining
- [4] Coursera Course on Pattern Mining
Market Basket Analysis Using High Utility Itemset Mining was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.