Exploring the overlooked but remarkable progress of MusicGen
An image symbolizing how Music AI products can elevate music-making for everyone. Image generated through a conversation with ChatGPT and DALL-E-3.
How it started…
In February 2023, Google made waves with their generative music AI MusicLM. At that point, two things became clear:
Many anticipated that the next breakthrough model would be ten times the size of MusicLM in terms of model parameters and training data. It would also raise the same ethical issues, including restricted access to the source code and the use of copyrighted training material.
Today, we know that only half of this was true.
Released in June 2023, Meta’s MusicGen model brought some massive improvements, including…
…all while using less training data, open-sourcing the code and model weights, and using only commercially licensed training material.
Six months later, the hype has slowly subsided. However, Meta’s research team FAIR has continued publishing papers and updating the code to incrementally improve MusicGen.
… how it’s going
Since its release, Meta has upgraded MusicGen in two key ways:
While this may sound like two small improvements, it makes a big difference. Listen for yourself! Here is a 10-second piece generated with the original MusicGen model (3.3B parameters):
The prompt used was:
Now, here is an example of the output MusicGen can produce six months later based on the same prompt:
If you are listening through smartphone speakers, the difference might not be very noticeable. On other devices, you should be able to hear that the overall sound is much clearer and natural and that the stereo sound makes the composition more lively and exciting.
In this blog post, I want to showcase these improvements, explain why they matter and how they work, and provide some example generations.
Multi-Band Diffusion — What Does That Do?
To understand what multi-band diffusion is and why it makes a difference, let us look at how the original MusicGen model [1] produced its outputs.
30 seconds of audio at a sample rate of 34kHz are represented in a computer with almost 1 million numbers. Generating something like that sample-by-sample is comparable to generating 10 full novels with ChatGPT.
Instead, Meta relies on neural audio compression techniques. Their compression model, EnCodec [2], can compress music from 34kHz to roughly 0.05kHz, all while maintaining the relevant information to reconstruct it to the original sample rate. EnCodec consists of an encoder, which compresses the audio, and a decoder, which recreates the original sounds (Figure 1).

Figure 1 — Encodec: Meta’s neural audio compression model. Image by author.
Now back to MusicGen. Instead of generating music at full sample rate, it generates it at 0.05kHz and lets EnCodec “reconstruct” it, resulting in high-fidelity outputs at minimal computing time & cost (Figure 2).
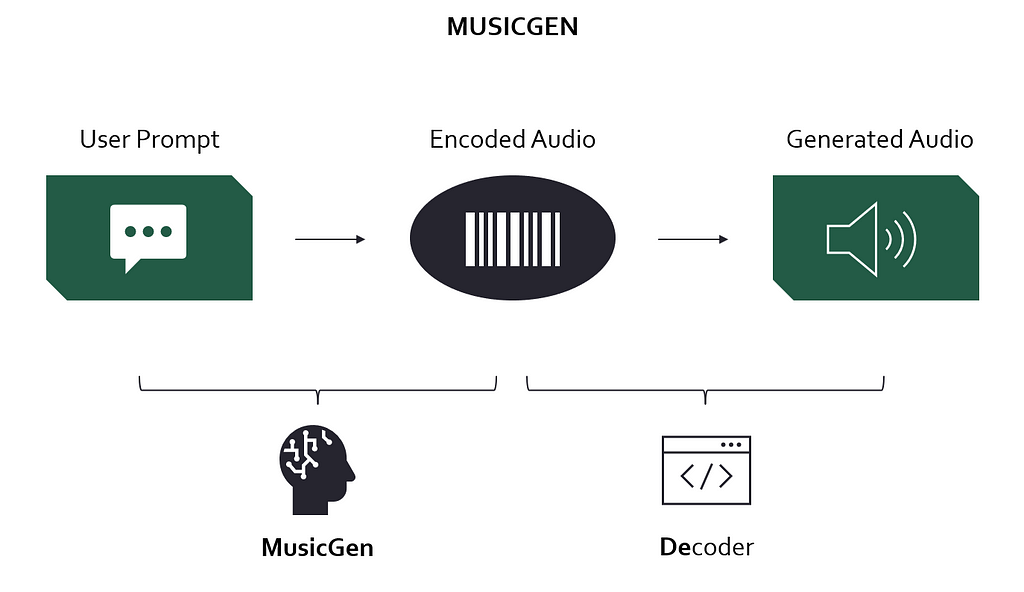
Figure 2 — MusicGen: A user prompt (text) is converted to an encoded audio signal which is then decoded to produce the final result. Image by author.
While EnCodec is an impressive technology, its compression is not lossless. There are noticeable artifacts in the reconstructed audio compared to the original. Listen for yourselves!
Original Audio
Reconstructed Audio
As MusicGen fully relies on EnCodec, it is a major bottleneck for the quality of the generated music. That is why Meta decided to work on improving EnCodec’s decoder part. In August 2023, they had developed an updated decoder for EnCodec leveraging multi-band diffusion [3].
One problem Meta saw with EnCodec’s original decoder was that it tended to generate low frequencies first and higher frequencies after. Unfortunately, this meant that any errors/artifacts in the low frequencies would distort the high frequencies as well, drastically decreasing the output quality.
Multi-band diffusion addresses this problem by generating different sections of the frequency spectrum independently before combining them. The researchers found that this procedure significantly improved the generated outputs. The differences are clearly noticeable from my perspective. Listen to the same track with the original EnCodec decoder and the multi-band diffusion decoder:
Original Decoder
Multi-Band Diffusion Decoder
One of the core issues of current text-to-music systems is that there is always an unnatural quality to the sounds it produces, especially for acoustical instruments. Multi-band diffusion makes the output sound much cleaner and more natural and takes MusicGen to a new level.
Why is Stereo Sound so Significant?
Up until now, most generative music models have been producing mono sound. This means MusicGen does not place any sounds or instruments on the left or right side, resulting in a less lively and exciting mix. The reason why stereo sound has been mostly overlooked so far is that generating stereo is not a trivial task.
As musicians, when we produce stereo signals, we have access to the individual instrument tracks in our mix and we can place them wherever we want. MusicGen does not generate all instruments separately but instead produces one combined audio signal. Without access to these instrument sources, creating stereo sound is hard. Unfortunately, splitting an audio signal into its individual sources is a tough problem (I’ve published a blog post about that) and the tech is still not 100% ready.
Therefore, Meta decided to incorporate stereo generation directly into the MusicGen model. Using a new dataset consisting of stereo music, they trained MusicGen to produce stereo outputs. The researchers claim that generating stereo has no additional computing costs compared to mono.
Although I feel that the stereo procedure is not very clearly described in the paper, my understanding it works like this (Figure 3): MusicGen has learned to generate two compressed audio signals (left and right channel) instead of one mono signal. These compressed signals must then be decoded separately before they are combined to build the final stereo output. The reason this process does not take twice as long is that MusicGen can now produce two compressed audio signals at approximately the same time it previously took for one signal.
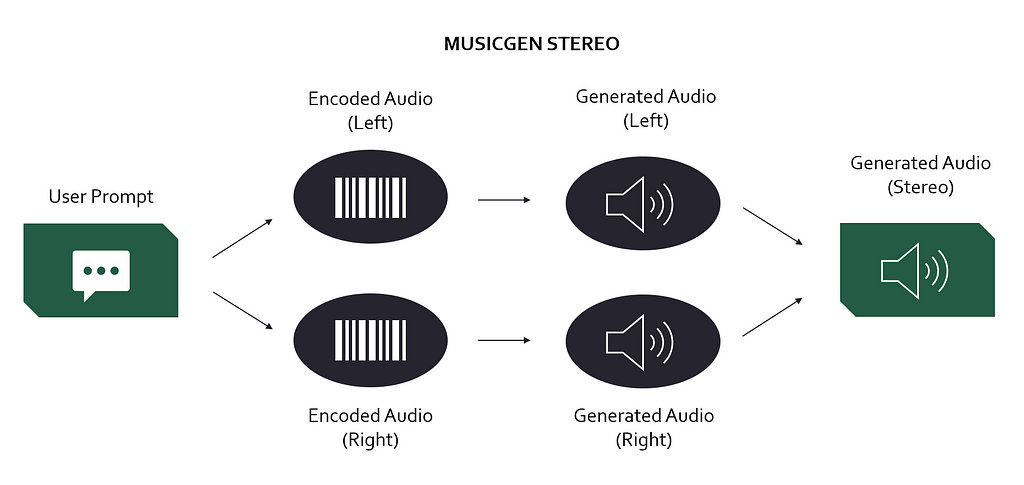
Figure 3 — MusicGen stereo update. Note that the process was not sufficiently documented in the paper for me to be 100% sure about this. Take it as an educated guess. Image by author.
Being able to produce convincing stereo sound really sets MusicGen apart from other state-of-the-art models like MusicLM or Stable Audio. From my perspective, this “little” addition makes a huge difference in the liveliness of the generated music. Listen for yourselves (might be hard to hear on smartphone speakers):
Mono
Stereo
Conclusion
MusicGen was impressive from the day it was released. However, since then, Meta’s FAIR team has been continually improving their product, enabling higher quality results that sound more authentic. When it comes to text-to-music models generating audio signals (not MIDI etc.), MusicGen is ahead of its competitors from my perspective (as of November 2023).
Further, since MusicGen and all its related products (EnCodec, AudioGen) are open-source, they constitute an incredible source of inspiration and a go-to framework for aspiring AI audio engineers. If we look at the improvements MusicGen has made in only 6 months, I can only imagine that 2024 will be an exciting year.
Another important point is that with their transparent approach, Meta is also doing foundational work for developers who want to integrate this technology into software for musicians. Generating samples, brainstorming musical ideas, or changing the genre of your existing work — these are some of the exciting applications we are already starting to see. With a sufficient level of transparency, we can make sure we are building a future where AI makes creating music more exciting instead of being only a threat to human musicianship.
Note: While MusicGen is open-source, the pre-trained models may not be used commercially! Visit the audiocraft GitHub repository for more detailed information on the intended use for all its components.
References
[1] Copet et al. (2023). Simple and Controllable Music Generation. https://arxiv.org/pdf/2306.05284.pdf
[2] Défossez et al. (2022). High Fidelity Neural Audio Compression. https://arxiv.org/pdf/2210.13438.pdf
[3] Roman et al. (2023). From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion. https://arxiv.org/abs/2308.02560
About Me
Hi there! I’m a musicologist and a data scientist, sharing my thoughts on current topics in AI & music. Here is some of my previous work related to this article:
Find me on Medium and Linkedin!

MusicGen Reimagined: Meta’s Under-the-Radar Advances in AI Music was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
An image symbolizing how Music AI products can elevate music-making for everyone. Image generated through a conversation with ChatGPT and DALL-E-3.
How it started…
In February 2023, Google made waves with their generative music AI MusicLM. At that point, two things became clear:
- 2023 would be the breakthrough year for AI-based music generation
- A new model would overshadow MusicLM in no time
Many anticipated that the next breakthrough model would be ten times the size of MusicLM in terms of model parameters and training data. It would also raise the same ethical issues, including restricted access to the source code and the use of copyrighted training material.
Today, we know that only half of this was true.
Released in June 2023, Meta’s MusicGen model brought some massive improvements, including…
- Higher quality music output (24kHz → 32kHz)
- More natural-sounding instruments
- The option to condition the generation on any melody (I wrote a blog post about this)
…all while using less training data, open-sourcing the code and model weights, and using only commercially licensed training material.
Six months later, the hype has slowly subsided. However, Meta’s research team FAIR has continued publishing papers and updating the code to incrementally improve MusicGen.
… how it’s going
Since its release, Meta has upgraded MusicGen in two key ways:
- Higher quality generation using multi-band diffusion
- More lively outputs thanks to stereo generation
While this may sound like two small improvements, it makes a big difference. Listen for yourself! Here is a 10-second piece generated with the original MusicGen model (3.3B parameters):
The prompt used was:
earthy tones, environmentally conscious, ukulele-infused, harmonic, breezy, easygoing, organic instrumentation, gentle grooves
Now, here is an example of the output MusicGen can produce six months later based on the same prompt:
If you are listening through smartphone speakers, the difference might not be very noticeable. On other devices, you should be able to hear that the overall sound is much clearer and natural and that the stereo sound makes the composition more lively and exciting.
In this blog post, I want to showcase these improvements, explain why they matter and how they work, and provide some example generations.
Multi-Band Diffusion — What Does That Do?
To understand what multi-band diffusion is and why it makes a difference, let us look at how the original MusicGen model [1] produced its outputs.
30 seconds of audio at a sample rate of 34kHz are represented in a computer with almost 1 million numbers. Generating something like that sample-by-sample is comparable to generating 10 full novels with ChatGPT.
Instead, Meta relies on neural audio compression techniques. Their compression model, EnCodec [2], can compress music from 34kHz to roughly 0.05kHz, all while maintaining the relevant information to reconstruct it to the original sample rate. EnCodec consists of an encoder, which compresses the audio, and a decoder, which recreates the original sounds (Figure 1).
Figure 1 — Encodec: Meta’s neural audio compression model. Image by author.
Now back to MusicGen. Instead of generating music at full sample rate, it generates it at 0.05kHz and lets EnCodec “reconstruct” it, resulting in high-fidelity outputs at minimal computing time & cost (Figure 2).
Figure 2 — MusicGen: A user prompt (text) is converted to an encoded audio signal which is then decoded to produce the final result. Image by author.
While EnCodec is an impressive technology, its compression is not lossless. There are noticeable artifacts in the reconstructed audio compared to the original. Listen for yourselves!
Original Audio
Reconstructed Audio
As MusicGen fully relies on EnCodec, it is a major bottleneck for the quality of the generated music. That is why Meta decided to work on improving EnCodec’s decoder part. In August 2023, they had developed an updated decoder for EnCodec leveraging multi-band diffusion [3].
One problem Meta saw with EnCodec’s original decoder was that it tended to generate low frequencies first and higher frequencies after. Unfortunately, this meant that any errors/artifacts in the low frequencies would distort the high frequencies as well, drastically decreasing the output quality.
Multi-band diffusion addresses this problem by generating different sections of the frequency spectrum independently before combining them. The researchers found that this procedure significantly improved the generated outputs. The differences are clearly noticeable from my perspective. Listen to the same track with the original EnCodec decoder and the multi-band diffusion decoder:
Original Decoder
Multi-Band Diffusion Decoder
One of the core issues of current text-to-music systems is that there is always an unnatural quality to the sounds it produces, especially for acoustical instruments. Multi-band diffusion makes the output sound much cleaner and more natural and takes MusicGen to a new level.
Why is Stereo Sound so Significant?
Up until now, most generative music models have been producing mono sound. This means MusicGen does not place any sounds or instruments on the left or right side, resulting in a less lively and exciting mix. The reason why stereo sound has been mostly overlooked so far is that generating stereo is not a trivial task.
As musicians, when we produce stereo signals, we have access to the individual instrument tracks in our mix and we can place them wherever we want. MusicGen does not generate all instruments separately but instead produces one combined audio signal. Without access to these instrument sources, creating stereo sound is hard. Unfortunately, splitting an audio signal into its individual sources is a tough problem (I’ve published a blog post about that) and the tech is still not 100% ready.
Therefore, Meta decided to incorporate stereo generation directly into the MusicGen model. Using a new dataset consisting of stereo music, they trained MusicGen to produce stereo outputs. The researchers claim that generating stereo has no additional computing costs compared to mono.
Although I feel that the stereo procedure is not very clearly described in the paper, my understanding it works like this (Figure 3): MusicGen has learned to generate two compressed audio signals (left and right channel) instead of one mono signal. These compressed signals must then be decoded separately before they are combined to build the final stereo output. The reason this process does not take twice as long is that MusicGen can now produce two compressed audio signals at approximately the same time it previously took for one signal.
Figure 3 — MusicGen stereo update. Note that the process was not sufficiently documented in the paper for me to be 100% sure about this. Take it as an educated guess. Image by author.
Being able to produce convincing stereo sound really sets MusicGen apart from other state-of-the-art models like MusicLM or Stable Audio. From my perspective, this “little” addition makes a huge difference in the liveliness of the generated music. Listen for yourselves (might be hard to hear on smartphone speakers):
Mono
Stereo
Conclusion
MusicGen was impressive from the day it was released. However, since then, Meta’s FAIR team has been continually improving their product, enabling higher quality results that sound more authentic. When it comes to text-to-music models generating audio signals (not MIDI etc.), MusicGen is ahead of its competitors from my perspective (as of November 2023).
Further, since MusicGen and all its related products (EnCodec, AudioGen) are open-source, they constitute an incredible source of inspiration and a go-to framework for aspiring AI audio engineers. If we look at the improvements MusicGen has made in only 6 months, I can only imagine that 2024 will be an exciting year.
Another important point is that with their transparent approach, Meta is also doing foundational work for developers who want to integrate this technology into software for musicians. Generating samples, brainstorming musical ideas, or changing the genre of your existing work — these are some of the exciting applications we are already starting to see. With a sufficient level of transparency, we can make sure we are building a future where AI makes creating music more exciting instead of being only a threat to human musicianship.
Note: While MusicGen is open-source, the pre-trained models may not be used commercially! Visit the audiocraft GitHub repository for more detailed information on the intended use for all its components.
References
[1] Copet et al. (2023). Simple and Controllable Music Generation. https://arxiv.org/pdf/2306.05284.pdf
[2] Défossez et al. (2022). High Fidelity Neural Audio Compression. https://arxiv.org/pdf/2210.13438.pdf
[3] Roman et al. (2023). From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion. https://arxiv.org/abs/2308.02560
About Me
Hi there! I’m a musicologist and a data scientist, sharing my thoughts on current topics in AI & music. Here is some of my previous work related to this article:
- How Meta’s AI Generates Music Based on a Reference Melody: View: https://medium.com/towards-data-science/how-metas-ai-generates-music-based-on-a-reference-melody-de34acd783
- MusicLM: Has Google Solved AI Music Generation?: View: https://medium.com/towards-data-science/musiclm-has-google-solved-ai-music-generation-c6859e76bc3c
- AI Music Source Separation: How it Works and Why it is so Hard: View: https://medium.com/towards-data-science/ai-music-source-separation-how-it-works-and-why-it-is-so-hard-187852e54752
Find me on Medium and Linkedin!
MusicGen Reimagined: Meta’s Under-the-Radar Advances in AI Music was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.