How PyTorch NestedTensors, FlashAttention2, and xFormers can Boost Performance and Reduce AI Costs

Photo by Tanja Zöllner on Unsplash
As generative AI (genAI) models grow in both popularity and scale, so do the computational demands and costs associated with their training and deployment. Optimizing these models is crucial for enhancing their runtime performance and reducing their operational expenses. At the heart of modern genAI systems is the Transformer architecture and its attention mechanism, which is notably compute-intensive.
In a previous post, we demonstrated how using optimized attention kernels can significantly accelerate the performance of Transformer models. In this post, we continue our exploration by addressing the challenge of variable-length input sequences — an inherent property of real-world data, including documents, code, time-series, and more.
The Challenge of Batching Variable-Length Input
In a typical deep learning workload, individual samples are grouped into batches before being copied to the GPU and fed to the AI model. Batching improves computational efficiency and often aids model convergence during training. Usually, batching involves stacking all of the sample tensors along a new dimension — the batch dimension. However, torch.stack requires that all tensors to have the same shape, which is not the case with variable-length sequences.
Padding and its Inefficiencies
The traditional way to address this challenge is to pad the input sequences to a fixed length and then perform stacking. This solution requires appropriate masking within the model so that the output is not affected by the irrelevant tensor elements. In the case of attention layers, a padding mask indicates which tokens are padding and should not be attended to (e.g., see PyTorch MultiheadAttention). However, padding can waste considerable GPU resources, increasing costs and slowing development. This is especially true for large-scale AI models.
Don’t Pad, Concatenate
One way to avoid padding is to concatenate sequences along an existing dimension instead of stacking them along a new dimension. Contrary to torch.stack, torch.cat allows inputs of different shapes. The output of concatenation is single sequence whose length equals the sum of the lengths of the individual sequences. For this solution to work, our single sequence would need to be supplemented by an attention mask that would ensure that each token only attends to other tokens in the same original sequence, in a process sometimes referred to as document masking. Denoting the sum of the lengths of all of the individual by N and adopting ”big O” notation, the size of this mask would need to be O(N²), as would the compute complexity of a standard attention layer, making this solution highly inefficient.
Attention Layer Optimization
The solution to this problem comes in the form of specialized attention layers. Contrary to the standard attention layer that performs the full set of O(N²) attention scores only to mask out the irrelevant ones, these optimized attention kernels are designed to calculate only the scores that matter. In this post we will explore several solutions, each with their own distinct characteristics. These include:
For teams working with pre-trained models, transitioning to these optimizations might seem challenging. We will demonstrate how HuggingFace’s APIs simplify this process, enabling developers to integrate these techniques with minimal code changes and effort.
Disclaimers
Special thanks to Yitzhak Levi and Peleg Nahaliel for their contributions to this post.
Toy LLM Model
To facilitate our discussion we will define a simple generative model (partially inspired by the GPT model defined here). For a more comprehensive guide on building language models, please see one of the many excellent tutorials available online (e.g., here).
Transformer Block
We begin by constructing a basic Transformer block, specifically designed to facilitate experimentation with different attention mechanisms and optimizations. While our block performs the same computation as standard Transformer blocks, we make slight modifications to the usual choice of operators in order to support the possibility of PyTorch NestedTensor inputs (as described here).
# general imports
import time, functools
# torch imports
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
# Define Transformer settings
BATCH_SIZE = 32
NUM_HEADS = 16
HEAD_DIM = 64
DIM = NUM_HEADS * HEAD_DIM
DEPTH = 24
NUM_TOKENS = 1024
MAX_SEQ_LEN = 1024
PAD_ID = 0
DEVICE = 'cuda'
class MyAttentionBlock(nn.Module):
def __init__(
self,
attn_fn,
dim,
num_heads,
format=None,
**kwargs
):
super().__init__()
self.attn_fn = attn_fn
self.num_heads = num_heads
self.dim = dim
self.head_dim = dim // num_heads
self.norm1 = nn.LayerNorm(dim, bias=False)
self.norm2 = nn.LayerNorm(dim, bias=False)
self.qkv = nn.Linear(dim, dim * 3)
self.proj = nn.Linear(dim, dim)
# mlp layers
self.fc1 = nn.Linear(dim, dim * 4)
self.act = nn.GELU()
self.fc2 = nn.Linear(dim * 4, dim)
self.permute = functools.partial(torch.transpose, dim0=1, dim1=2)
if format == 'bshd':
self.permute = nn.Identity()
def mlp(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
return x
def reshape_and_permute(self,x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.head_dim)
return self.permute(x)
def forward(self, x_in, attn_mask=None):
batch_size = x_in.size(0)
x = self.norm1(x_in)
qkv = self.qkv(x)
# rather than first reformatting and then splitting the input
# state, we first split and then reformat q, k, v in order to
# support PyTorch Nested Tensors
q, k, v = qkv.chunk(3, -1)
q = self.reshape_and_permute(q, batch_size)
k = self.reshape_and_permute(k, batch_size)
v = self.reshape_and_permute(v, batch_size)
# call the attn_fn with the input attn_mask
x = self.attn_fn(q, k, v, attn_mask=attn_mask)
# reformat output
x = self.permute(x).reshape(batch_size, -1, self.dim)
x = self.proj(x)
x = x + x_in
x = x + self.mlp(self.norm2(x))
return x
Transformer Decoder Model
Building on our programmable Transformer block, we construct a typical Transformer decoder model.
class MyDecoder(nn.Module):
def __init__(
self,
block_fn,
num_tokens,
dim,
num_heads,
num_layers,
max_seq_len,
pad_idx=None
):
super().__init__()
self.num_heads = num_heads
self.pad_idx = pad_idx
self.embedding = nn.Embedding(num_tokens, dim, padding_idx=pad_idx)
self.positional_embedding = nn.Embedding(max_seq_len, dim)
self.blocks = nn.ModuleList([
block_fn(
dim=dim,
num_heads=num_heads
)
for _ in range(num_layers)])
self.output = nn.Linear(dim, num_tokens)
def embed_tokens(self, input_ids, position_ids=None):
x = self.embedding(input_ids)
if position_ids is None:
position_ids = torch.arange(input_ids.shape[1],
device=x.device)
x = x + self.positional_embedding(position_ids)
return x
def forward(self, input_ids, position_ids=None, attn_mask=None):
# Embed tokens and add positional encoding
x = self.embed_tokens(input_ids, position_ids)
if self.pad_idx is not None:
assert attn_mask is None
# create a padding mask - we assume boolean masking
attn_mask = (input_ids != self.pad_idx)
attn_mask = attn_mask.view(BATCH_SIZE, 1, 1, -1) \
.expand(-1, self.num_heads, -1, -1)
for b in self.blocks:
x = b(x, attn_mask)
logits = self.output(x)
return logits
Variable Length Sequence Input
Next, we create a dataset containing sequences of variable lengths, where each sequence is made up of randomly generated tokens. For simplicity, we (arbitrarily) select a fixed distribution for the sequence lengths. In real-world scenarios, the distribution of sequence lengths typically reflects the nature of the data, such as the length of documents or audio segments. Note, that the distribution of lengths directly affects the computational inefficiencies caused by padding.
# Use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
length = torch.randint(1, MAX_SEQ_LEN, (1,))
sequence = torch.randint(1, NUM_TOKENS, (length + 1,))
input = sequence[:-1]
target = sequence[1:]
return input, target
def pad_sequence(sequence, length, pad_val):
return torch.nn.functional.pad(
sequence,
(0, length - sequence.shape[0]),
value=pad_val
)
def collate_with_padding(batch):
padded_inputs = []
padded_targets = []
for b in batch:
padded_inputs.append(pad_sequence(b[0], MAX_SEQ_LEN, PAD_ID))
padded_targets.append(pad_sequence(b[1], MAX_SEQ_LEN, PAD_ID))
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_targets = torch.stack(padded_targets, dim=0)
return {
'inputs': padded_inputs,
'targets': padded_targets
}
def data_to_device(data, device):
if isinstance(data, dict):
return {
key: data_to_device(val,device)
for key, val in data.items()
}
elif isinstance(data, (list, tuple)):
return type(data)(
data_to_device(val, device) for val in data
)
elif isinstance(data, torch.Tensor):
return data.to(device=device, non_blocking=True)
else:
return data.to(device=device)
Training/Evaluation Loop
Lastly, we implement a main function that performs training/evaluation on input sequences of varying length.
def main(
block_fn,
data_collate_fn=collate_with_padding,
pad_idx=None,
train=True,
compile=False
):
torch.random.manual_seed(0)
device = torch.device(DEVICE)
torch.set_float32_matmul_precision("high")
# Create dataset and dataloader
data_set = FakeDataset()
data_loader = DataLoader(
data_set,
batch_size=BATCH_SIZE,
collate_fn=data_collate_fn,
num_workers=12,
pin_memory=True,
drop_last=True
)
model = MyDecoder(
block_fn=block_fn,
num_tokens=NUM_TOKENS,
dim=DIM,
num_heads=NUM_HEADS,
num_layers=DEPTH,
max_seq_len=MAX_SEQ_LEN,
pad_idx=pad_idx
).to(device)
if compile:
model = torch.compile(model)
# Define loss and optimizer
criterion = torch.nn.CrossEntropyLoss(ignore_index=PAD_ID)
optimizer = torch.optim.SGD(model.parameters())
def train_step(model, inputs, targets,
position_ids=None, attn_mask=None):
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(inputs, position_ids, attn_mask)
outputs = outputs.view(-1, NUM_TOKENS)
targets = targets.flatten()
loss = criterion(outputs, targets)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
@torch.no_grad()
def eval_step(model, inputs, targets,
position_ids=None, attn_mask=None):
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(inputs, position_ids, attn_mask)
if outputs.is_nested:
outputs = outputs.data._values
targets = targets.data._values
else:
outputs = outputs.view(-1, NUM_TOKENS)
targets = targets.flatten()
loss = criterion(outputs, targets)
return loss
if train:
model.train()
step_fn = train_step
else:
model.eval()
step_fn = eval_step
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(data_loader):
# Copy data to GPU
data = data_to_device(data, device=device)
step_fn(model, data['inputs'], data['targets'],
position_ids=data.get('indices'),
attn_mask=data.get('attn_mask'))
# Capture step time
batch_time = time.perf_counter() - t0
if step > 20: # Skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step >= 100:
break
print(f'average step time: {summ / count}')
PyTorch SDPA with Padding
For our baseline experiments, we configure our Transformer block to utilize PyTorch’s SDPA mechanism. In our experiments, we run both training and evaluation, both with and without torch.compile. These were run on an NVIDIA H100 with CUDA 12.4 and PyTorch 2.5.1
from torch.nn.functional import scaled_dot_product_attention as sdpa
block_fn = functools.partial(MyAttentionBlock, attn_fn=sdpa)
causal_block_fn = functools.partial(
MyAttentionBlock,
attn_fn=functools.partial(sdpa, is_causal=True)
)
for mode in ['eval', 'train']:
for compile in [False, True]:
block_func = causal_block_fn\
if mode == 'train' else block_fn
print(f'{mode} with {collate}, '
f'{"compiled" if compile else "uncompiled"}')
main(block_fn=block_func,
pad_idx=PAD_ID,
train=mode=='train',
compile=compile)
Performance Results:
In this section, we will explore several optimization techniques for handling variable-length input sequences in Transformer models.
Padding Optimization
Our first optimization relates not to the attention kernel but to our padding mechanism. Rather than padding the sequences in each batch to a constant length, we pad to the length of the longest sequence in the batch. The following block of code consists of our revised collation function and updated experiments.
def collate_pad_to_longest(batch):
padded_inputs = []
padded_targets = []
max_length = max([b[0].shape[0] for b in batch])
for b in batch:
padded_inputs.append(pad_sequence(b[0], max_length, PAD_ID))
padded_targets.append(pad_sequence(b[1], max_length, PAD_ID))
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_targets = torch.stack(padded_targets, dim=0)
return {
'inputs': padded_inputs,
'targets': padded_targets
}
for mode in ['eval', 'train']:
for compile in [False, True]:
block_func = causal_block_fn\
if mode == 'train' else block_fn
print(f'{mode} with {collate}, '
f'{"compiled" if compile else "uncompiled"}')
main(block_fn=block_func,
data_collate_fn=collate_pad_to_longest,
pad_idx=PAD_ID,
train=mode=='train',
compile=compile)
Padding to the longest sequence in each batch results in a slight performance acceleration:
Next, we take advantage of the built-in support for PyTorch NestedTensors in SDPA in evaluation mode. Currently a prototype feature, PyTorch NestedTensors allows for grouping together tensors of varying length. These are sometimes referred to as jagged or ragged tensors. In the code block below, we define a collation function for grouping our sequences into NestedTensors. We also define an indices entry so that we can properly calculate the positional embeddings.
PyTorch NestedTensors are supported by a limited number of PyTorch ops. Working around these limitations can require some creativity. For example, addition between NestedTensors is only supported when they share precisely the same “jagged” shape. In the code below we use a workaround to ensure that the indices entry shares the same shape as the model inputs.
def nested_tensor_collate(batch):
inputs = torch.nested.as_nested_tensor([b[0] for b in batch],
layout=torch.jagged)
targets = torch.nested.as_nested_tensor([b[1] for b in batch],
layout=torch.jagged)
indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])
# workaround for creating a NestedTensor with identical "jagged" shape
xx = torch.empty_like(inputs)
xx.data._values[:] = indices
return {
'inputs': inputs,
'targets': targets,
'indices': xx
}
for compile in [False, True]:
print(f'eval with nested tensors, '
f'{"compiled" if compile else "uncompiled"}')
main(
block_fn=block_fn,
data_collate_fn=nested_tensor_collate,
train=False,
compile=compile
)
Although, with torch.compile, the NestedTensor optimization results in a step time of 131 ms, similar to our baseline result, in compiled mode the step time drops to 42 ms for an impressive ~3x improvement.
FlashAttention2
In our previous post we demonstrated the use of FlashAttention and its impact on the performance of a transformer model. In this post we demonstrate the use of flash_attn_varlen_func from flash-attn (2.7.0), an API designed for use with variable-sized inputs. To use this function, we concatenate all of the sequences in the batch into a single sequence. We also create a cu_seqlens tensor that points to the indices within the concatenated tensor where each of the individual sequences start. The code block below includes our collation function followed by evaluation and training experiments. Note, that flash_attn_varlen_func does not support torch.compile (at the time of this writing).
def collate_concat(batch):
inputs = torch.concat([b[0] for b in batch]).unsqueeze(0)
targets = torch.concat([b[1] for b in batch]).unsqueeze(0)
indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])
seqlens = torch.tensor([b[0].shape[0] for b in batch])
seqlens = torch.cumsum(seqlens, dim=0, dtype=torch.int32)
cu_seqlens = torch.nn.functional.pad(seqlens, (1, 0))
return {
'inputs': inputs,
'targets': targets,
'indices': indices,
'attn_mask': cu_seqlens
}
from flash_attn import flash_attn_varlen_func
fa_varlen = lambda q, k, v, attn_mask: flash_attn_varlen_func(
q.squeeze(0),
k.squeeze(0),
v.squeeze(0),
cu_seqlens_q=attn_mask,
cu_seqlens_k=attn_mask,
max_seqlen_q=MAX_SEQ_LEN,
max_seqlen_k=MAX_SEQ_LEN
).unsqueeze(0)
fa_varlen_causal = lambda q, k, v, attn_mask: flash_attn_varlen_func(
q.squeeze(0),
k.squeeze(0),
v.squeeze(0),
cu_seqlens_q=attn_mask,
cu_seqlens_k=attn_mask,
max_seqlen_q=MAX_SEQ_LEN,
max_seqlen_k=MAX_SEQ_LEN,
causal=True
).unsqueeze(0)
block_fn = functools.partial(MyAttentionBlock,
attn_fn=fa_varlen,
format='bshd')
causal_block_fn = functools.partial(MyAttentionBlock,
attn_fn=fa_varlen_causal,
format='bshd')
print('flash-attn eval')
main(
block_fn=block_fn,
data_collate_fn=collate_concat,
train=False
)
print('flash-attn train')
main(
block_fn=causal_block_fn,
data_collate_fn=collate_concat,
train=True,
)
The impact of this optimization is dramatic, 51 ms for evaluation and 160 ms for training, amounting to 2.6x and 2.1x performance boosts compared to our baseline experiment.
XFormers Memory Efficient Attention
In our previous post we demonstrated the use of the memory_efficient_attention operator from xFormers (0.0.28). Here we demonstrate the use of BlockDiagonalMask, specifically designed for input sequences of arbitrary length. The required collation function appears in the code block below followed by the evaluation and training experiments. Note, that torch.compile failed in training mode.
from xformers.ops import fmha
from xformers.ops import memory_efficient_attention as mea
def collate_xformer(batch):
inputs = torch.concat([b[0] for b in batch]).unsqueeze(0)
targets = torch.concat([b[1] for b in batch]).unsqueeze(0)
indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])
seqlens = [b[0].shape[0] for b in batch]
batch_sizes = [1 for b in batch]
block_diag = fmha.BlockDiagonalMask.from_seqlens(seqlens, device='cpu')
block_diag._batch_sizes = batch_sizes
return {
'inputs': inputs,
'targets': targets,
'indices': indices,
'attn_mask': block_diag
}
mea_eval = lambda q, k, v, attn_mask: mea(
q,k,v, attn_bias=attn_mask)
mea_train = lambda q, k, v, attn_mask: mea(
q,k,v, attn_bias=attn_mask.make_causal())
block_fn = functools.partial(MyAttentionBlock,
attn_fn=mea_eval,
format='bshd')
causal_block_fn = functools.partial(MyAttentionBlock,
attn_fn=mea_train,
format='bshd')
print(f'xFormer Attention ')
for compile in [False, True]:
print(f'eval with xFormer Attention, '
f'{"compiled" if compile else "uncompiled"}')
main(block_fn=block_fn,
train=False,
data_collate_fn=collate_xformer,
compile=compile)
print(f'train with xFormer Attention')
main(block_fn=causal_block_fn,
train=True,
data_collate_fn=collate_xformer)
The resultant step time were 50 ms and 159 ms for evaluation and training without torch.compile. Evaluation with torch.compile resulted in a step time of 42 ms.
Results
The table below summarizes the results of our optimization methods.
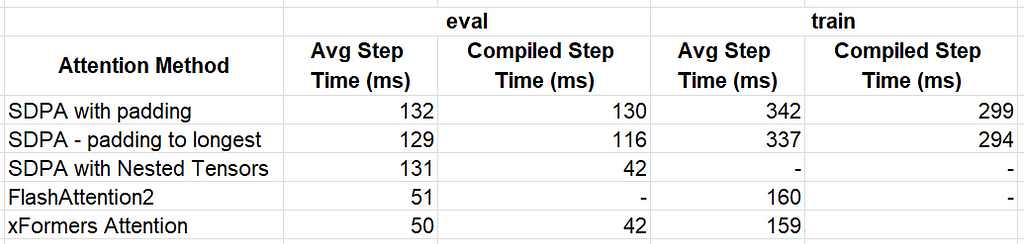
Step time results for different optimization methods (lower is better) — by Author
The best performer for our toy model is xFormer’s memory_efficient_attention which delivered a ~3x performance for evaluation and ~2x performance for training. We caution against deriving any conclusions from these results as the performance impact of different attention functions can vary significantly depending on the specific model and use case.
Optimizing a HuggingFace Model for Variable-Length Input
The tools and techniques described above are easy to implement when creating a model from scratch. However, these days it is not uncommon for ML developers to adopt existing (pretrained) models and finetune them for their use case. While the optimizations we have described can be integrated without changing the set of model weights and without altering the model behavior, it is not entirely clear what the best way to do this is. In an ideal world, our ML framework would allow us to program the use of an attention mechanism that is optimized for variable-length inputs. In this section we demonstrate how to optimize HuggingFace models for variable-length inputs.
A Toy HuggingFace Model - GPT2LMHeadModel
To facilitate the discussion, we create a toy example in which we train a HuggingFace GPT2LMHead model on variable-length sequences. This requires adapting our random dataset and data-padding collation function according to HuggingFace's input specifications.
from transformers import GPT2Config, GPT2LMHeadModel
# Use random data
class HuggingFaceFakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
length = torch.randint(1, MAX_SEQ_LEN, (1,))
input_ids = torch.randint(1, NUM_TOKENS, (length,))
labels = input_ids.clone()
labels[0] = PAD_ID # ignore first token
return {
'input_ids': input_ids,
'labels': labels
}
return input_ids, labels
def hf_collate_with_padding(batch):
padded_inputs = []
padded_labels = []
for b in batch:
input_ids = b['input_ids']
labels = b['labels']
padded_inputs.append(pad_sequence(input_ids, MAX_SEQ_LEN, PAD_ID))
padded_labels.append(pad_sequence(labels, MAX_SEQ_LEN, PAD_ID))
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_labels = torch.stack(padded_labels, dim=0)
return {
'input_ids': padded_inputs,
'labels': padded_labels,
'attention_mask': (padded_inputs != PAD_ID)
}
Training Function
Our training function instantiates a GPT2LMHeadModel based on the requested GPT2Config and proceeds to train it on our variable-length sequences.
def hf_main(
config,
collate_fn=hf_collate_with_padding,
compile=False
):
torch.random.manual_seed(0)
device = torch.device(DEVICE)
torch.set_float32_matmul_precision("high")
# Create dataset and dataloader
data_set = HuggingFaceFakeDataset()
data_loader = DataLoader(
data_set,
batch_size=BATCH_SIZE,
collate_fn=collate_fn,
num_workers=12 if DEVICE == "CUDA" else 0,
pin_memory=True,
drop_last=True
)
model = GPT2LMHeadModel(config).to(device)
if compile:
model = torch.compile(model)
# Define loss and optimizer
criterion = torch.nn.CrossEntropyLoss(ignore_index=PAD_ID)
optimizer = torch.optim.SGD(model.parameters())
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(data_loader):
# Copy data to GPU
data = data_to_device(data, device=device)
input_ids = data['input_ids']
labels = data['labels']
position_ids = data.get('position_ids')
attn_mask = data.get('attention_mask')
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(input_ids=input_ids,
position_ids=position_ids,
attention_mask=attn_mask)
logits = outputs.logits[..., :-1, :].contiguous()
labels = labels[..., 1:].contiguous()
loss = criterion(logits.view(-1, NUM_TOKENS), labels.flatten())
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# Capture step time
batch_time = time.perf_counter() - t0
if step > 20: # Skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step >= 100:
break
print(f'average step time: {summ / count}')
SDPA with Padding
In the callback below we call our training function with the default sequence-padding collator.
config = GPT2Config(
n_layer=DEPTH,
n_embd=DIM,
n_head=NUM_HEADS,
vocab_size=NUM_TOKENS,
)
for compile in [False, True]:
print(f"HF GPT2 train with SDPA, compile={compile}")
hf_main(config=config, compile=compile)
The resultant step times are 815 ms without torch.compile and 440 ms with torch.compile.
FlashAttention2
We now take advantage of HuggingFace’s built-in support for FlashAttention2, by setting the attn_implementation parameter to “flash_attention_2”. Behind the scenes, HuggingFace will unpad the padded data input and then pass them to the optimized flash_attn_varlen_func function we saw above:
flash_config = GPT2Config(
n_layer=DEPTH,
n_embd=DIM,
n_head=NUM_HEADS,
vocab_size=NUM_TOKENS,
attn_implementation='flash_attention_2'
)
print(f"HF GPT2 train with flash")
hf_main(config=flash_config)
The resultant time step is 620 ms, amounting to a 30% boost (in uncompiled mode) with just a simple flick of a switch.
FlashAttention2 with Unpadded Input
Of course, padding the sequences in the collation function only to have them unpadded, hardly seems sensible. In a recent update to HuggingFace, support was added for passing in concatenated (unpadded) sequences to a select number of models. Unfortunately, (as of the time of this writing) our GPT2 model did not make the cut. However, adding support requires just five small line additions changes to modeling_gpt2.py in order to propagate the sequence position_ids to the flash-attention kernel. The full patch appears in the block below:
@@ -370,0 +371 @@
+ position_ids = None
@@ -444,0 +446 @@
+ position_ids=position_ids
@@ -611,0 +614 @@
+ position_ids=None
@@ -621,0 +625 @@
+ position_ids=position_ids
@@ -1140,0 +1145 @@
+ position_ids=position_ids
We define a collate function that concatenates our sequences and train our hugging face model on unpadded sequences. (Also see the built-in DataCollatorWithFlattening utility.)
def collate_flatten(batch):
input_ids = torch.concat([b['input_ids'] for b in batch]).unsqueeze(0)
labels = torch.concat([b['labels'] for b in batch]).unsqueeze(0)
position_ids = [torch.arange(b['input_ids'].shape[0]) for b in batch]
position_ids = torch.concat(position_ids)
return {
'input_ids': input_ids,
'labels': labels,
'position_ids': position_ids
}
print(f"HF GPT2 train with flash, no padding")
hf_main(config=flash_config, collate_fn=collate_flatten)
The resulting step time is 323 ms, 90% faster than running flash-attention on the padded input.
Results
The results of our HuggingFace experiments are summarized below.

Step time results for different optimization methods (lower is better) — by Author
With little effort, we were able to boost our runtime performance by 2.5x when compared to the uncompiled baseline experiment, and by 36% when compared to the compiled version.
In this section, we demonstrated how the HuggingFace APIs allow us to leverage the optimized kernels in FlashAttention2, significantly boosting the training performance of existing models on sequences of varying length.
Summary
As AI models continue to grow in both popularity and complexity, optimizing their performance has become essential for reducing runtime and costs. This is especially true for compute-intensive components like attention layers. In this post, we have continued our exploration of attention layer optimization, and demonstrated new tools and techniques for enhancing Transformer model performance. For more insights on AI model optimization, be sure to check out the first post in this series as well as our many other posts on this topic.

Optimizing Transformer Models for Variable-Length Input Sequences was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Photo by Tanja Zöllner on Unsplash
As generative AI (genAI) models grow in both popularity and scale, so do the computational demands and costs associated with their training and deployment. Optimizing these models is crucial for enhancing their runtime performance and reducing their operational expenses. At the heart of modern genAI systems is the Transformer architecture and its attention mechanism, which is notably compute-intensive.
In a previous post, we demonstrated how using optimized attention kernels can significantly accelerate the performance of Transformer models. In this post, we continue our exploration by addressing the challenge of variable-length input sequences — an inherent property of real-world data, including documents, code, time-series, and more.
The Challenge of Batching Variable-Length Input
In a typical deep learning workload, individual samples are grouped into batches before being copied to the GPU and fed to the AI model. Batching improves computational efficiency and often aids model convergence during training. Usually, batching involves stacking all of the sample tensors along a new dimension — the batch dimension. However, torch.stack requires that all tensors to have the same shape, which is not the case with variable-length sequences.
Padding and its Inefficiencies
The traditional way to address this challenge is to pad the input sequences to a fixed length and then perform stacking. This solution requires appropriate masking within the model so that the output is not affected by the irrelevant tensor elements. In the case of attention layers, a padding mask indicates which tokens are padding and should not be attended to (e.g., see PyTorch MultiheadAttention). However, padding can waste considerable GPU resources, increasing costs and slowing development. This is especially true for large-scale AI models.
Don’t Pad, Concatenate
One way to avoid padding is to concatenate sequences along an existing dimension instead of stacking them along a new dimension. Contrary to torch.stack, torch.cat allows inputs of different shapes. The output of concatenation is single sequence whose length equals the sum of the lengths of the individual sequences. For this solution to work, our single sequence would need to be supplemented by an attention mask that would ensure that each token only attends to other tokens in the same original sequence, in a process sometimes referred to as document masking. Denoting the sum of the lengths of all of the individual by N and adopting ”big O” notation, the size of this mask would need to be O(N²), as would the compute complexity of a standard attention layer, making this solution highly inefficient.
Attention Layer Optimization
The solution to this problem comes in the form of specialized attention layers. Contrary to the standard attention layer that performs the full set of O(N²) attention scores only to mask out the irrelevant ones, these optimized attention kernels are designed to calculate only the scores that matter. In this post we will explore several solutions, each with their own distinct characteristics. These include:
- PyTorch's SDPA (Scaled Dot Product Attention) with NestedTensors,
- FlashAttention2, and
- xFormers' memory-efficient attention.
For teams working with pre-trained models, transitioning to these optimizations might seem challenging. We will demonstrate how HuggingFace’s APIs simplify this process, enabling developers to integrate these techniques with minimal code changes and effort.
Disclaimers
- Please do not interpret our use of any platforms, libraries, or optimization techniques as an endorsement for their use. The best options for you will depend greatly on the specifics of your own use-case.
- Some of the APIs discussed here are in prototype or beta stages and may change in the future.
- The code examples provided are for demonstrative purposes only. We make no claims regarding their accuracy, optimality, or robustness.
Special thanks to Yitzhak Levi and Peleg Nahaliel for their contributions to this post.
Toy LLM Model
To facilitate our discussion we will define a simple generative model (partially inspired by the GPT model defined here). For a more comprehensive guide on building language models, please see one of the many excellent tutorials available online (e.g., here).
Transformer Block
We begin by constructing a basic Transformer block, specifically designed to facilitate experimentation with different attention mechanisms and optimizations. While our block performs the same computation as standard Transformer blocks, we make slight modifications to the usual choice of operators in order to support the possibility of PyTorch NestedTensor inputs (as described here).
# general imports
import time, functools
# torch imports
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
# Define Transformer settings
BATCH_SIZE = 32
NUM_HEADS = 16
HEAD_DIM = 64
DIM = NUM_HEADS * HEAD_DIM
DEPTH = 24
NUM_TOKENS = 1024
MAX_SEQ_LEN = 1024
PAD_ID = 0
DEVICE = 'cuda'
class MyAttentionBlock(nn.Module):
def __init__(
self,
attn_fn,
dim,
num_heads,
format=None,
**kwargs
):
super().__init__()
self.attn_fn = attn_fn
self.num_heads = num_heads
self.dim = dim
self.head_dim = dim // num_heads
self.norm1 = nn.LayerNorm(dim, bias=False)
self.norm2 = nn.LayerNorm(dim, bias=False)
self.qkv = nn.Linear(dim, dim * 3)
self.proj = nn.Linear(dim, dim)
# mlp layers
self.fc1 = nn.Linear(dim, dim * 4)
self.act = nn.GELU()
self.fc2 = nn.Linear(dim * 4, dim)
self.permute = functools.partial(torch.transpose, dim0=1, dim1=2)
if format == 'bshd':
self.permute = nn.Identity()
def mlp(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.fc2(x)
return x
def reshape_and_permute(self,x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.head_dim)
return self.permute(x)
def forward(self, x_in, attn_mask=None):
batch_size = x_in.size(0)
x = self.norm1(x_in)
qkv = self.qkv(x)
# rather than first reformatting and then splitting the input
# state, we first split and then reformat q, k, v in order to
# support PyTorch Nested Tensors
q, k, v = qkv.chunk(3, -1)
q = self.reshape_and_permute(q, batch_size)
k = self.reshape_and_permute(k, batch_size)
v = self.reshape_and_permute(v, batch_size)
# call the attn_fn with the input attn_mask
x = self.attn_fn(q, k, v, attn_mask=attn_mask)
# reformat output
x = self.permute(x).reshape(batch_size, -1, self.dim)
x = self.proj(x)
x = x + x_in
x = x + self.mlp(self.norm2(x))
return x
Transformer Decoder Model
Building on our programmable Transformer block, we construct a typical Transformer decoder model.
class MyDecoder(nn.Module):
def __init__(
self,
block_fn,
num_tokens,
dim,
num_heads,
num_layers,
max_seq_len,
pad_idx=None
):
super().__init__()
self.num_heads = num_heads
self.pad_idx = pad_idx
self.embedding = nn.Embedding(num_tokens, dim, padding_idx=pad_idx)
self.positional_embedding = nn.Embedding(max_seq_len, dim)
self.blocks = nn.ModuleList([
block_fn(
dim=dim,
num_heads=num_heads
)
for _ in range(num_layers)])
self.output = nn.Linear(dim, num_tokens)
def embed_tokens(self, input_ids, position_ids=None):
x = self.embedding(input_ids)
if position_ids is None:
position_ids = torch.arange(input_ids.shape[1],
device=x.device)
x = x + self.positional_embedding(position_ids)
return x
def forward(self, input_ids, position_ids=None, attn_mask=None):
# Embed tokens and add positional encoding
x = self.embed_tokens(input_ids, position_ids)
if self.pad_idx is not None:
assert attn_mask is None
# create a padding mask - we assume boolean masking
attn_mask = (input_ids != self.pad_idx)
attn_mask = attn_mask.view(BATCH_SIZE, 1, 1, -1) \
.expand(-1, self.num_heads, -1, -1)
for b in self.blocks:
x = b(x, attn_mask)
logits = self.output(x)
return logits
Variable Length Sequence Input
Next, we create a dataset containing sequences of variable lengths, where each sequence is made up of randomly generated tokens. For simplicity, we (arbitrarily) select a fixed distribution for the sequence lengths. In real-world scenarios, the distribution of sequence lengths typically reflects the nature of the data, such as the length of documents or audio segments. Note, that the distribution of lengths directly affects the computational inefficiencies caused by padding.
# Use random data
class FakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
length = torch.randint(1, MAX_SEQ_LEN, (1,))
sequence = torch.randint(1, NUM_TOKENS, (length + 1,))
input = sequence[:-1]
target = sequence[1:]
return input, target
def pad_sequence(sequence, length, pad_val):
return torch.nn.functional.pad(
sequence,
(0, length - sequence.shape[0]),
value=pad_val
)
def collate_with_padding(batch):
padded_inputs = []
padded_targets = []
for b in batch:
padded_inputs.append(pad_sequence(b[0], MAX_SEQ_LEN, PAD_ID))
padded_targets.append(pad_sequence(b[1], MAX_SEQ_LEN, PAD_ID))
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_targets = torch.stack(padded_targets, dim=0)
return {
'inputs': padded_inputs,
'targets': padded_targets
}
def data_to_device(data, device):
if isinstance(data, dict):
return {
key: data_to_device(val,device)
for key, val in data.items()
}
elif isinstance(data, (list, tuple)):
return type(data)(
data_to_device(val, device) for val in data
)
elif isinstance(data, torch.Tensor):
return data.to(device=device, non_blocking=True)
else:
return data.to(device=device)
Training/Evaluation Loop
Lastly, we implement a main function that performs training/evaluation on input sequences of varying length.
def main(
block_fn,
data_collate_fn=collate_with_padding,
pad_idx=None,
train=True,
compile=False
):
torch.random.manual_seed(0)
device = torch.device(DEVICE)
torch.set_float32_matmul_precision("high")
# Create dataset and dataloader
data_set = FakeDataset()
data_loader = DataLoader(
data_set,
batch_size=BATCH_SIZE,
collate_fn=data_collate_fn,
num_workers=12,
pin_memory=True,
drop_last=True
)
model = MyDecoder(
block_fn=block_fn,
num_tokens=NUM_TOKENS,
dim=DIM,
num_heads=NUM_HEADS,
num_layers=DEPTH,
max_seq_len=MAX_SEQ_LEN,
pad_idx=pad_idx
).to(device)
if compile:
model = torch.compile(model)
# Define loss and optimizer
criterion = torch.nn.CrossEntropyLoss(ignore_index=PAD_ID)
optimizer = torch.optim.SGD(model.parameters())
def train_step(model, inputs, targets,
position_ids=None, attn_mask=None):
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(inputs, position_ids, attn_mask)
outputs = outputs.view(-1, NUM_TOKENS)
targets = targets.flatten()
loss = criterion(outputs, targets)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
@torch.no_grad()
def eval_step(model, inputs, targets,
position_ids=None, attn_mask=None):
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(inputs, position_ids, attn_mask)
if outputs.is_nested:
outputs = outputs.data._values
targets = targets.data._values
else:
outputs = outputs.view(-1, NUM_TOKENS)
targets = targets.flatten()
loss = criterion(outputs, targets)
return loss
if train:
model.train()
step_fn = train_step
else:
model.eval()
step_fn = eval_step
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(data_loader):
# Copy data to GPU
data = data_to_device(data, device=device)
step_fn(model, data['inputs'], data['targets'],
position_ids=data.get('indices'),
attn_mask=data.get('attn_mask'))
# Capture step time
batch_time = time.perf_counter() - t0
if step > 20: # Skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step >= 100:
break
print(f'average step time: {summ / count}')
PyTorch SDPA with Padding
For our baseline experiments, we configure our Transformer block to utilize PyTorch’s SDPA mechanism. In our experiments, we run both training and evaluation, both with and without torch.compile. These were run on an NVIDIA H100 with CUDA 12.4 and PyTorch 2.5.1
from torch.nn.functional import scaled_dot_product_attention as sdpa
block_fn = functools.partial(MyAttentionBlock, attn_fn=sdpa)
causal_block_fn = functools.partial(
MyAttentionBlock,
attn_fn=functools.partial(sdpa, is_causal=True)
)
for mode in ['eval', 'train']:
for compile in [False, True]:
block_func = causal_block_fn\
if mode == 'train' else block_fn
print(f'{mode} with {collate}, '
f'{"compiled" if compile else "uncompiled"}')
main(block_fn=block_func,
pad_idx=PAD_ID,
train=mode=='train',
compile=compile)
Performance Results:
- Evaluation: 132 milliseconds (ms) without torch.compile, 130 ms with torch.compile
- Training: 342 ms without torch.compile, 299 ms with torch.compile
In this section, we will explore several optimization techniques for handling variable-length input sequences in Transformer models.
Padding Optimization
Our first optimization relates not to the attention kernel but to our padding mechanism. Rather than padding the sequences in each batch to a constant length, we pad to the length of the longest sequence in the batch. The following block of code consists of our revised collation function and updated experiments.
def collate_pad_to_longest(batch):
padded_inputs = []
padded_targets = []
max_length = max([b[0].shape[0] for b in batch])
for b in batch:
padded_inputs.append(pad_sequence(b[0], max_length, PAD_ID))
padded_targets.append(pad_sequence(b[1], max_length, PAD_ID))
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_targets = torch.stack(padded_targets, dim=0)
return {
'inputs': padded_inputs,
'targets': padded_targets
}
for mode in ['eval', 'train']:
for compile in [False, True]:
block_func = causal_block_fn\
if mode == 'train' else block_fn
print(f'{mode} with {collate}, '
f'{"compiled" if compile else "uncompiled"}')
main(block_fn=block_func,
data_collate_fn=collate_pad_to_longest,
pad_idx=PAD_ID,
train=mode=='train',
compile=compile)
Padding to the longest sequence in each batch results in a slight performance acceleration:
- Evaluation: 129 ms without torch.compile, 116 ms with torch.compile
- Training: 337 ms without torch.compile, 294 ms with torch.compile
Next, we take advantage of the built-in support for PyTorch NestedTensors in SDPA in evaluation mode. Currently a prototype feature, PyTorch NestedTensors allows for grouping together tensors of varying length. These are sometimes referred to as jagged or ragged tensors. In the code block below, we define a collation function for grouping our sequences into NestedTensors. We also define an indices entry so that we can properly calculate the positional embeddings.
PyTorch NestedTensors are supported by a limited number of PyTorch ops. Working around these limitations can require some creativity. For example, addition between NestedTensors is only supported when they share precisely the same “jagged” shape. In the code below we use a workaround to ensure that the indices entry shares the same shape as the model inputs.
def nested_tensor_collate(batch):
inputs = torch.nested.as_nested_tensor([b[0] for b in batch],
layout=torch.jagged)
targets = torch.nested.as_nested_tensor([b[1] for b in batch],
layout=torch.jagged)
indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])
# workaround for creating a NestedTensor with identical "jagged" shape
xx = torch.empty_like(inputs)
xx.data._values[:] = indices
return {
'inputs': inputs,
'targets': targets,
'indices': xx
}
for compile in [False, True]:
print(f'eval with nested tensors, '
f'{"compiled" if compile else "uncompiled"}')
main(
block_fn=block_fn,
data_collate_fn=nested_tensor_collate,
train=False,
compile=compile
)
Although, with torch.compile, the NestedTensor optimization results in a step time of 131 ms, similar to our baseline result, in compiled mode the step time drops to 42 ms for an impressive ~3x improvement.
FlashAttention2
In our previous post we demonstrated the use of FlashAttention and its impact on the performance of a transformer model. In this post we demonstrate the use of flash_attn_varlen_func from flash-attn (2.7.0), an API designed for use with variable-sized inputs. To use this function, we concatenate all of the sequences in the batch into a single sequence. We also create a cu_seqlens tensor that points to the indices within the concatenated tensor where each of the individual sequences start. The code block below includes our collation function followed by evaluation and training experiments. Note, that flash_attn_varlen_func does not support torch.compile (at the time of this writing).
def collate_concat(batch):
inputs = torch.concat([b[0] for b in batch]).unsqueeze(0)
targets = torch.concat([b[1] for b in batch]).unsqueeze(0)
indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])
seqlens = torch.tensor([b[0].shape[0] for b in batch])
seqlens = torch.cumsum(seqlens, dim=0, dtype=torch.int32)
cu_seqlens = torch.nn.functional.pad(seqlens, (1, 0))
return {
'inputs': inputs,
'targets': targets,
'indices': indices,
'attn_mask': cu_seqlens
}
from flash_attn import flash_attn_varlen_func
fa_varlen = lambda q, k, v, attn_mask: flash_attn_varlen_func(
q.squeeze(0),
k.squeeze(0),
v.squeeze(0),
cu_seqlens_q=attn_mask,
cu_seqlens_k=attn_mask,
max_seqlen_q=MAX_SEQ_LEN,
max_seqlen_k=MAX_SEQ_LEN
).unsqueeze(0)
fa_varlen_causal = lambda q, k, v, attn_mask: flash_attn_varlen_func(
q.squeeze(0),
k.squeeze(0),
v.squeeze(0),
cu_seqlens_q=attn_mask,
cu_seqlens_k=attn_mask,
max_seqlen_q=MAX_SEQ_LEN,
max_seqlen_k=MAX_SEQ_LEN,
causal=True
).unsqueeze(0)
block_fn = functools.partial(MyAttentionBlock,
attn_fn=fa_varlen,
format='bshd')
causal_block_fn = functools.partial(MyAttentionBlock,
attn_fn=fa_varlen_causal,
format='bshd')
print('flash-attn eval')
main(
block_fn=block_fn,
data_collate_fn=collate_concat,
train=False
)
print('flash-attn train')
main(
block_fn=causal_block_fn,
data_collate_fn=collate_concat,
train=True,
)
The impact of this optimization is dramatic, 51 ms for evaluation and 160 ms for training, amounting to 2.6x and 2.1x performance boosts compared to our baseline experiment.
XFormers Memory Efficient Attention
In our previous post we demonstrated the use of the memory_efficient_attention operator from xFormers (0.0.28). Here we demonstrate the use of BlockDiagonalMask, specifically designed for input sequences of arbitrary length. The required collation function appears in the code block below followed by the evaluation and training experiments. Note, that torch.compile failed in training mode.
from xformers.ops import fmha
from xformers.ops import memory_efficient_attention as mea
def collate_xformer(batch):
inputs = torch.concat([b[0] for b in batch]).unsqueeze(0)
targets = torch.concat([b[1] for b in batch]).unsqueeze(0)
indices = torch.concat([torch.arange(b[0].shape[0]) for b in batch])
seqlens = [b[0].shape[0] for b in batch]
batch_sizes = [1 for b in batch]
block_diag = fmha.BlockDiagonalMask.from_seqlens(seqlens, device='cpu')
block_diag._batch_sizes = batch_sizes
return {
'inputs': inputs,
'targets': targets,
'indices': indices,
'attn_mask': block_diag
}
mea_eval = lambda q, k, v, attn_mask: mea(
q,k,v, attn_bias=attn_mask)
mea_train = lambda q, k, v, attn_mask: mea(
q,k,v, attn_bias=attn_mask.make_causal())
block_fn = functools.partial(MyAttentionBlock,
attn_fn=mea_eval,
format='bshd')
causal_block_fn = functools.partial(MyAttentionBlock,
attn_fn=mea_train,
format='bshd')
print(f'xFormer Attention ')
for compile in [False, True]:
print(f'eval with xFormer Attention, '
f'{"compiled" if compile else "uncompiled"}')
main(block_fn=block_fn,
train=False,
data_collate_fn=collate_xformer,
compile=compile)
print(f'train with xFormer Attention')
main(block_fn=causal_block_fn,
train=True,
data_collate_fn=collate_xformer)
The resultant step time were 50 ms and 159 ms for evaluation and training without torch.compile. Evaluation with torch.compile resulted in a step time of 42 ms.
Results
The table below summarizes the results of our optimization methods.
Step time results for different optimization methods (lower is better) — by Author
The best performer for our toy model is xFormer’s memory_efficient_attention which delivered a ~3x performance for evaluation and ~2x performance for training. We caution against deriving any conclusions from these results as the performance impact of different attention functions can vary significantly depending on the specific model and use case.
Optimizing a HuggingFace Model for Variable-Length Input
The tools and techniques described above are easy to implement when creating a model from scratch. However, these days it is not uncommon for ML developers to adopt existing (pretrained) models and finetune them for their use case. While the optimizations we have described can be integrated without changing the set of model weights and without altering the model behavior, it is not entirely clear what the best way to do this is. In an ideal world, our ML framework would allow us to program the use of an attention mechanism that is optimized for variable-length inputs. In this section we demonstrate how to optimize HuggingFace models for variable-length inputs.
A Toy HuggingFace Model - GPT2LMHeadModel
To facilitate the discussion, we create a toy example in which we train a HuggingFace GPT2LMHead model on variable-length sequences. This requires adapting our random dataset and data-padding collation function according to HuggingFace's input specifications.
from transformers import GPT2Config, GPT2LMHeadModel
# Use random data
class HuggingFaceFakeDataset(Dataset):
def __len__(self):
return 1000000
def __getitem__(self, index):
length = torch.randint(1, MAX_SEQ_LEN, (1,))
input_ids = torch.randint(1, NUM_TOKENS, (length,))
labels = input_ids.clone()
labels[0] = PAD_ID # ignore first token
return {
'input_ids': input_ids,
'labels': labels
}
return input_ids, labels
def hf_collate_with_padding(batch):
padded_inputs = []
padded_labels = []
for b in batch:
input_ids = b['input_ids']
labels = b['labels']
padded_inputs.append(pad_sequence(input_ids, MAX_SEQ_LEN, PAD_ID))
padded_labels.append(pad_sequence(labels, MAX_SEQ_LEN, PAD_ID))
padded_inputs = torch.stack(padded_inputs, dim=0)
padded_labels = torch.stack(padded_labels, dim=0)
return {
'input_ids': padded_inputs,
'labels': padded_labels,
'attention_mask': (padded_inputs != PAD_ID)
}
Training Function
Our training function instantiates a GPT2LMHeadModel based on the requested GPT2Config and proceeds to train it on our variable-length sequences.
def hf_main(
config,
collate_fn=hf_collate_with_padding,
compile=False
):
torch.random.manual_seed(0)
device = torch.device(DEVICE)
torch.set_float32_matmul_precision("high")
# Create dataset and dataloader
data_set = HuggingFaceFakeDataset()
data_loader = DataLoader(
data_set,
batch_size=BATCH_SIZE,
collate_fn=collate_fn,
num_workers=12 if DEVICE == "CUDA" else 0,
pin_memory=True,
drop_last=True
)
model = GPT2LMHeadModel(config).to(device)
if compile:
model = torch.compile(model)
# Define loss and optimizer
criterion = torch.nn.CrossEntropyLoss(ignore_index=PAD_ID)
optimizer = torch.optim.SGD(model.parameters())
model.train()
t0 = time.perf_counter()
summ = 0
count = 0
for step, data in enumerate(data_loader):
# Copy data to GPU
data = data_to_device(data, device=device)
input_ids = data['input_ids']
labels = data['labels']
position_ids = data.get('position_ids')
attn_mask = data.get('attention_mask')
with torch.amp.autocast(DEVICE, dtype=torch.bfloat16):
outputs = model(input_ids=input_ids,
position_ids=position_ids,
attention_mask=attn_mask)
logits = outputs.logits[..., :-1, :].contiguous()
labels = labels[..., 1:].contiguous()
loss = criterion(logits.view(-1, NUM_TOKENS), labels.flatten())
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# Capture step time
batch_time = time.perf_counter() - t0
if step > 20: # Skip first steps
summ += batch_time
count += 1
t0 = time.perf_counter()
if step >= 100:
break
print(f'average step time: {summ / count}')
SDPA with Padding
In the callback below we call our training function with the default sequence-padding collator.
config = GPT2Config(
n_layer=DEPTH,
n_embd=DIM,
n_head=NUM_HEADS,
vocab_size=NUM_TOKENS,
)
for compile in [False, True]:
print(f"HF GPT2 train with SDPA, compile={compile}")
hf_main(config=config, compile=compile)
The resultant step times are 815 ms without torch.compile and 440 ms with torch.compile.
FlashAttention2
We now take advantage of HuggingFace’s built-in support for FlashAttention2, by setting the attn_implementation parameter to “flash_attention_2”. Behind the scenes, HuggingFace will unpad the padded data input and then pass them to the optimized flash_attn_varlen_func function we saw above:
flash_config = GPT2Config(
n_layer=DEPTH,
n_embd=DIM,
n_head=NUM_HEADS,
vocab_size=NUM_TOKENS,
attn_implementation='flash_attention_2'
)
print(f"HF GPT2 train with flash")
hf_main(config=flash_config)
The resultant time step is 620 ms, amounting to a 30% boost (in uncompiled mode) with just a simple flick of a switch.
FlashAttention2 with Unpadded Input
Of course, padding the sequences in the collation function only to have them unpadded, hardly seems sensible. In a recent update to HuggingFace, support was added for passing in concatenated (unpadded) sequences to a select number of models. Unfortunately, (as of the time of this writing) our GPT2 model did not make the cut. However, adding support requires just five small line additions changes to modeling_gpt2.py in order to propagate the sequence position_ids to the flash-attention kernel. The full patch appears in the block below:
@@ -370,0 +371 @@
+ position_ids = None
@@ -444,0 +446 @@
+ position_ids=position_ids
@@ -611,0 +614 @@
+ position_ids=None
@@ -621,0 +625 @@
+ position_ids=position_ids
@@ -1140,0 +1145 @@
+ position_ids=position_ids
We define a collate function that concatenates our sequences and train our hugging face model on unpadded sequences. (Also see the built-in DataCollatorWithFlattening utility.)
def collate_flatten(batch):
input_ids = torch.concat([b['input_ids'] for b in batch]).unsqueeze(0)
labels = torch.concat([b['labels'] for b in batch]).unsqueeze(0)
position_ids = [torch.arange(b['input_ids'].shape[0]) for b in batch]
position_ids = torch.concat(position_ids)
return {
'input_ids': input_ids,
'labels': labels,
'position_ids': position_ids
}
print(f"HF GPT2 train with flash, no padding")
hf_main(config=flash_config, collate_fn=collate_flatten)
The resulting step time is 323 ms, 90% faster than running flash-attention on the padded input.
Results
The results of our HuggingFace experiments are summarized below.
Step time results for different optimization methods (lower is better) — by Author
With little effort, we were able to boost our runtime performance by 2.5x when compared to the uncompiled baseline experiment, and by 36% when compared to the compiled version.
In this section, we demonstrated how the HuggingFace APIs allow us to leverage the optimized kernels in FlashAttention2, significantly boosting the training performance of existing models on sequences of varying length.
Summary
As AI models continue to grow in both popularity and complexity, optimizing their performance has become essential for reducing runtime and costs. This is especially true for compute-intensive components like attention layers. In this post, we have continued our exploration of attention layer optimization, and demonstrated new tools and techniques for enhancing Transformer model performance. For more insights on AI model optimization, be sure to check out the first post in this series as well as our many other posts on this topic.
Optimizing Transformer Models for Variable-Length Input Sequences was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.