Transformers can generate NFL plays : introducing QB-GPT
Bridging the gap between GenAI and sports analytics

Photo by Zetong Li on Unsplash
Since my first article about StratFormer, I received a relatively great amount of feedbacks and ideas (so first thank you !). This pushed me to deepen my work an try an extra step : building a football plays’ generator. In this article I present QB-GPT, a model that can effectively generate football plays once provided with some elements. A dedicated HuggingFace space can be found here to play with it. I will later in the month share my work and findings on how to better predict NFL plays using this kind of generative models as backbone. The industryy is also watching this field as DeepMind Safety Research is currently doing research on soccer with Liverpool on understanding how players move on the field.
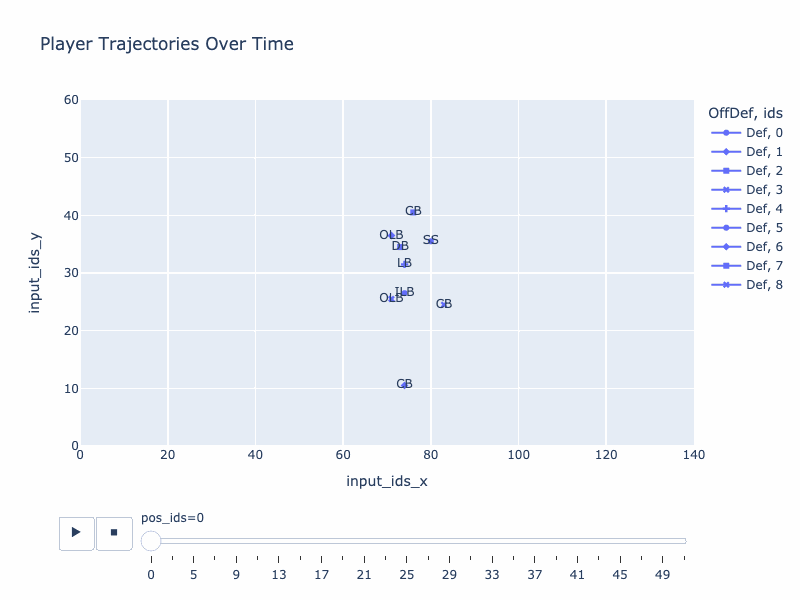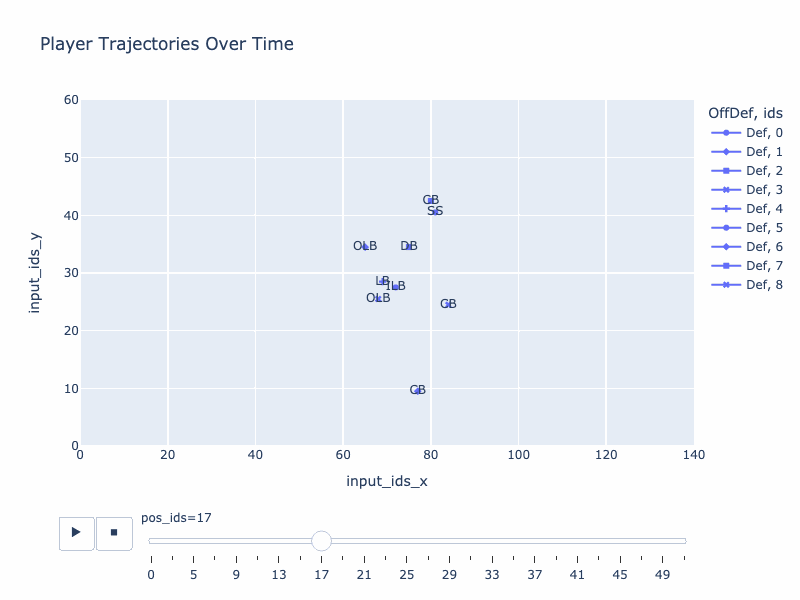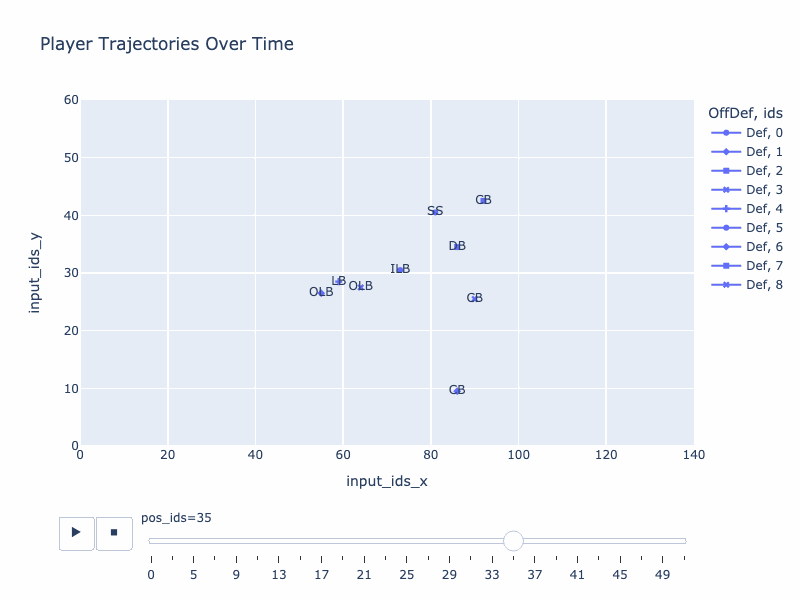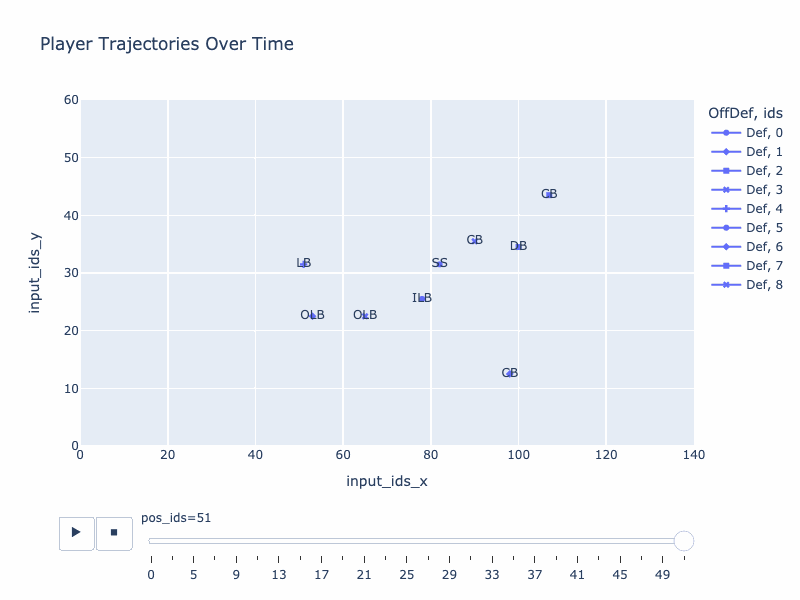
Generated trajectory by QB-GPT
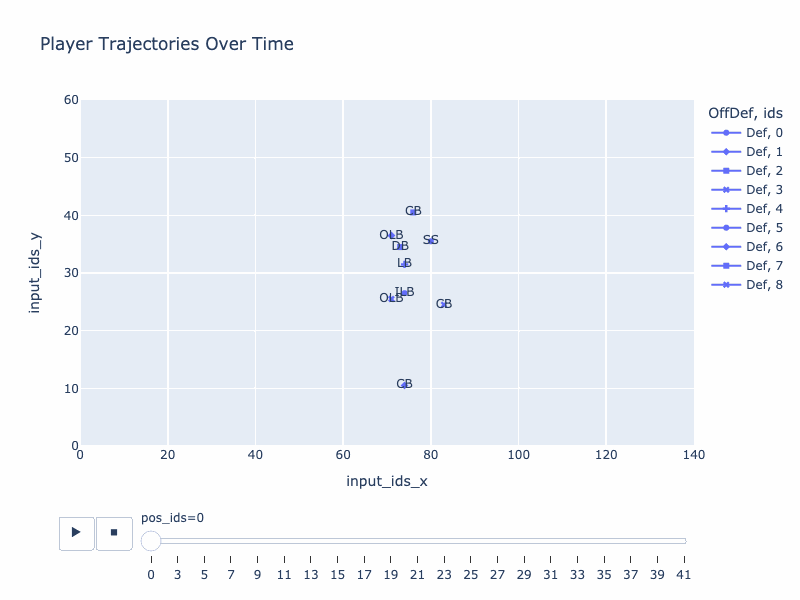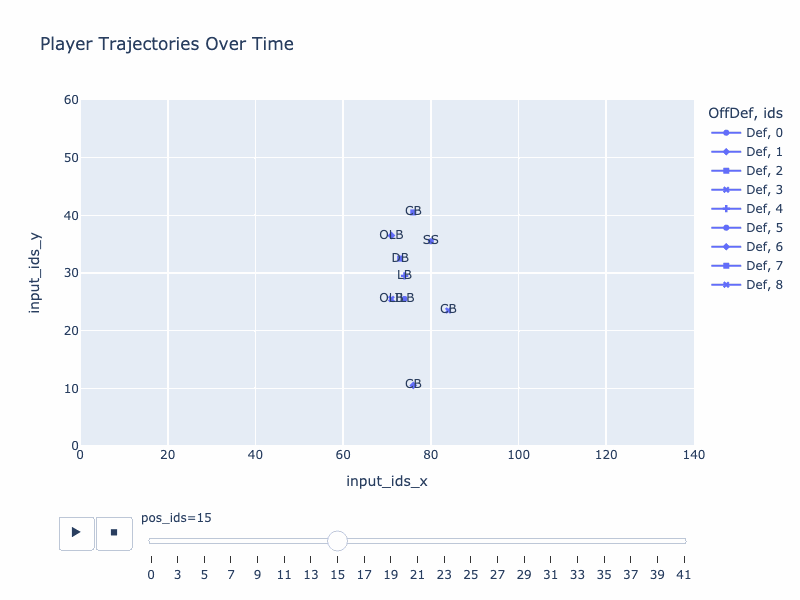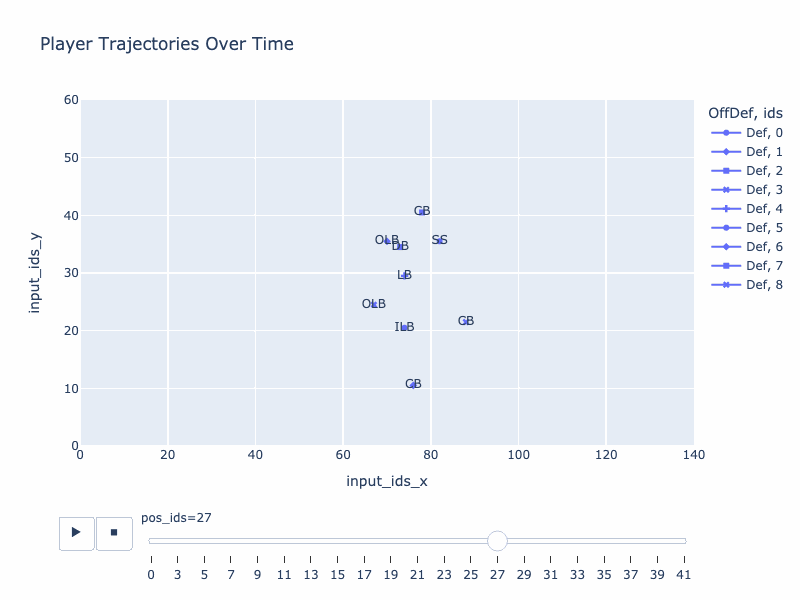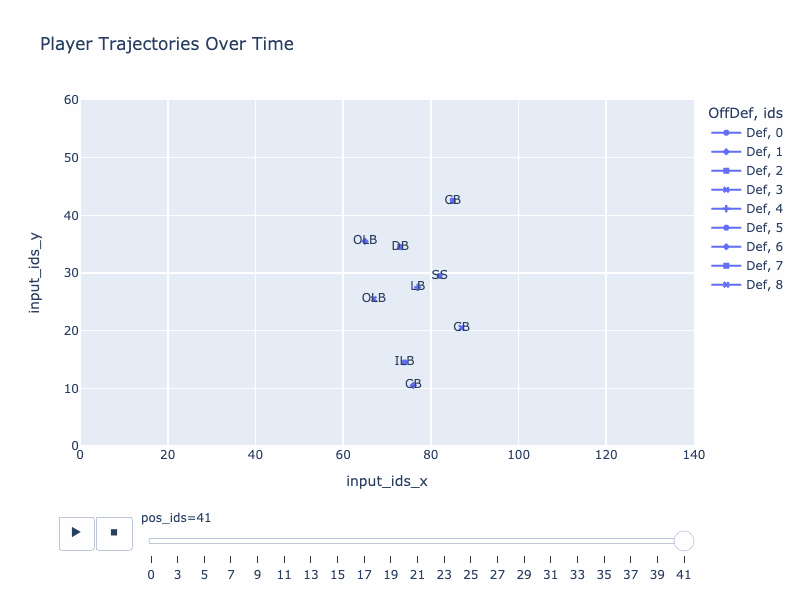
True trajectory
Stratformer, my first idea that I started in Oct 2021, was an encoder-only model which took a trajectory as input, tried to complete it and predicted some contextual elements associated with it (team, positions and plays). While this model showed interesting patterns (such as understanding what makes truly different a RB and a WR), it relied on a “a posteriori” look on the play. What could be even more interesting is to deeply understand how the set up of players, with some contextual elements, effectively affect the paths of the team. In other words, when the teams are facing each others at the scrimmage line, what is going to happen ?
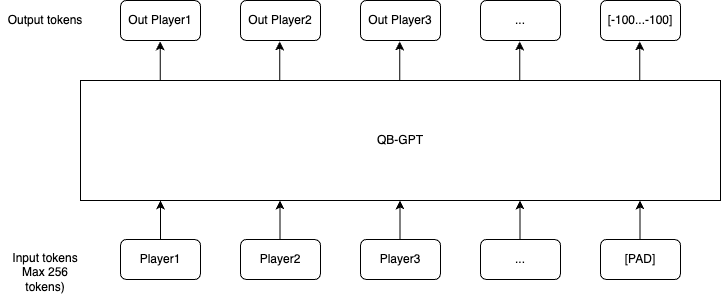
By building such an algorithm, we are now able to build a model that “really” understands the football game, as it is basically trying to recreate plays from few elements. This is the goal of QB-GPT. GPT is here because it relies on the same concepts of decoding that use any GPT models.
This article will cover the model and the few necessary tricks that I had to implement to make it “ok”. An attached HuggingFace space is available here to generate some plays if you wish, I will keep it open a limited time depending on the cost. While I recognized it is limited and prone to a range of improvements, I think such application deserves to be shared with a broader audience. If interested to discuss it or deepen some aspects, my contacts are on the app and at the end of the article. Once again, I did this work on my own, with the dat I could find and the imperfections related to it (If someone working at the NFL/NGS team reads this, DMs more than open)
Part 1 : The data
The data required to perform such task is very very hard to find. I rely on a specific data type provided only by the Next Gen Stats (NGS) tool of the NFL, where, for any given play, I can track up to the 22 players present on the field. The problem is that this data is not accessible via a classic API request. However, since 2019, the NFL is offering a wide range of data competition on Kaggle, often provided with datasets from the NGS. Also, some people on GitHub have scrapped back in the days the NGS browser. I did not try to do it and only relied on available data that had a usable format.
An extensive time has been spent on merging data between themselves (around 200 hours). The most important tasks were to:
I used Polars during all the process. I strongly recommend to any data scientist, ML engineer, data engineer or people working with large volume of tabular data to quickly add this impressive package into their toolkit. TLDR: Polars is better than pandas on small dataset and better than pypsark on large ones.
All in all, I compiled 47,991 different plays representing 870,559 different players’ trajectories on the field (18 players monitored per play on average, unfortunately never one OL…).
I monitor each player’s position at a 0.2 second frame rate, representing 28,147,112 positions on the field in total. I limit the data to the first 10 seconds as the trajectories tend to be more and more chaotic after, and hence difficult to model from a probabilistic point of view.
My dataset starts in 2018 to 2022 and covers 3,190 unique players. The data is not perfect but gives a good sample and may be enough to assess whether transformers are helpful.
To summarize, my data sources are :
Here under you have a scheme representing the input input embedding for a single player:
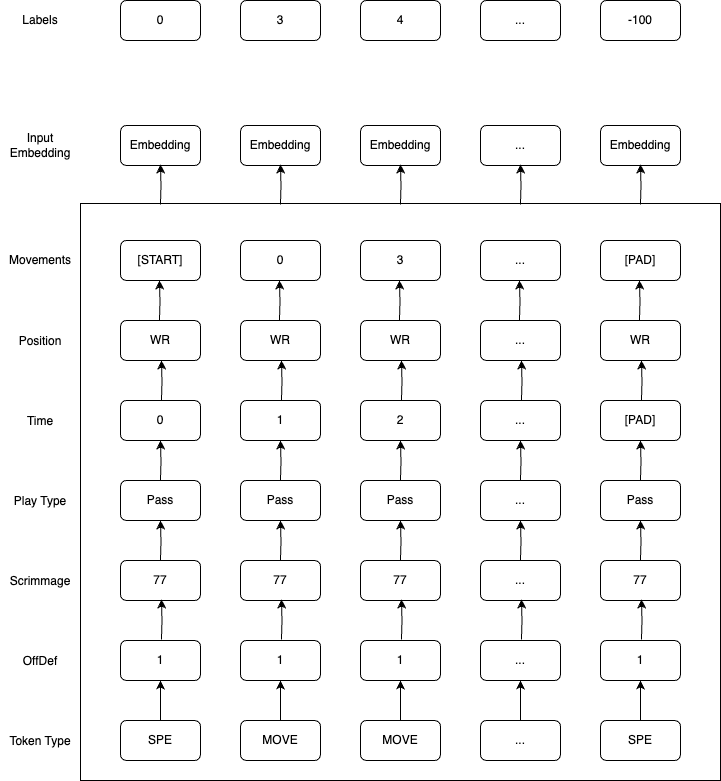
Then the eleven players are concatenated per play and then truncated by frames to always have a number of token equal to 256. I limited the number of frames for one player at 21 (max = 21*11 = 231) to make sure the we have consistently the same number of frames per player. Hence, I had to create new trajectories starting directly at a given moment of a play as most of my plays have more than 21 frames. I created a padding step of 12 frames, meaning the trajectory is now divided in sub trajectories, each time shifted by 12 frames. This process tends to make harder the task of preidction for the frames 12, 24, 36 and 48 as we will see later.
Elements can be discussed. For instance the relevance of dicing the field with a 1 yard basis or why using a 0.2 second frame rate. I think the model (so its training data) is a start and I want to acknowledge that not everything is perfect. Feedbacks and opinions are welcome as long as they are relevant.
Part 2 : The model
The model is completely inspired from the OpenAI GPT architecture. It relies on a embedding layer adding different contextual elements to the input tokens. The embeddings are then fed to a single transformers module using multi-head attention with 3 heads. In the Large model, a second transformers module is applied. The output is then fed into a dense layer with a “relu” activation. To obtain the predictions, we apply a soft-max activation.
Two tricks were needed to adapt the architecture and training :
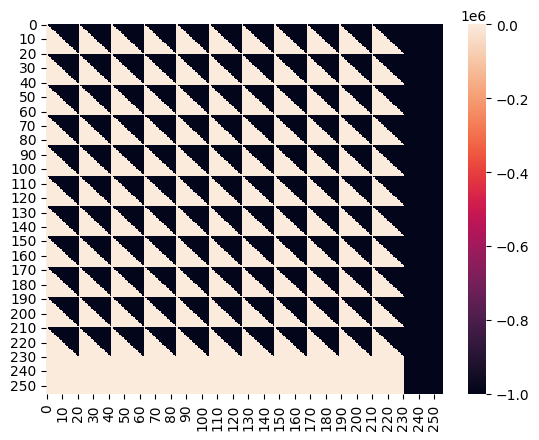
Attention masks
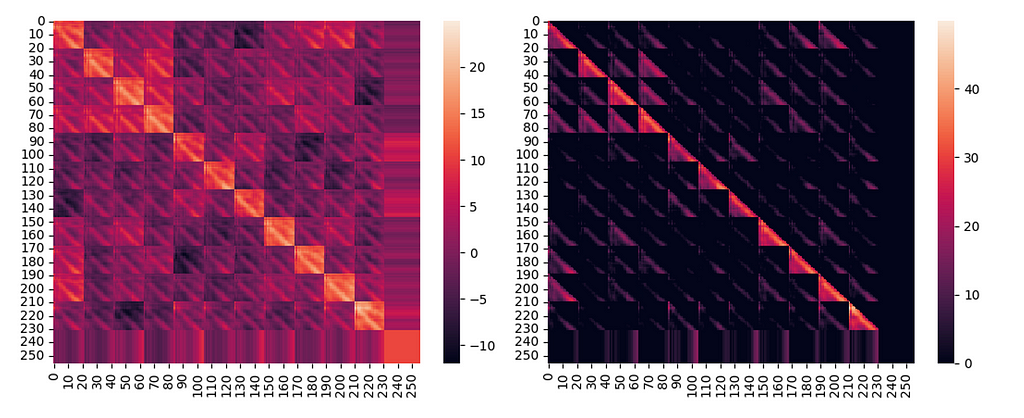
Raw attention scores and after attention masks subtractions
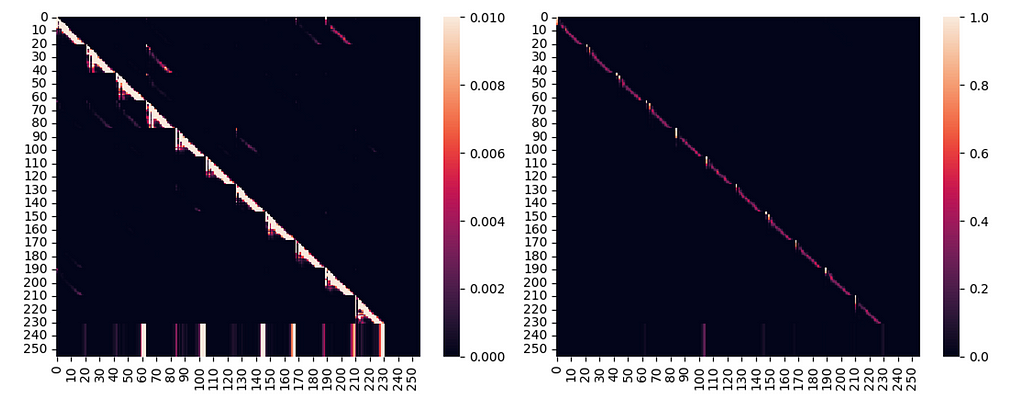
Attention scores with different vmax scale
The model does not require a high number of attention layers as the underlying patterns to model are quite simple. I trained 4 different models’ architectures using the same settings. Results show that embeddings’ dimensions plays a crucial roles in the level of accuracy that we can reach while number of attention modules does not significantly improve accuracy:
I think the large one could reach a better performance with an in-depth review of the scheduler.
(For comparison, GPT3 has 175 billion parameters)
The charts here under show a comparison of accuracy and loss during training between the different models:
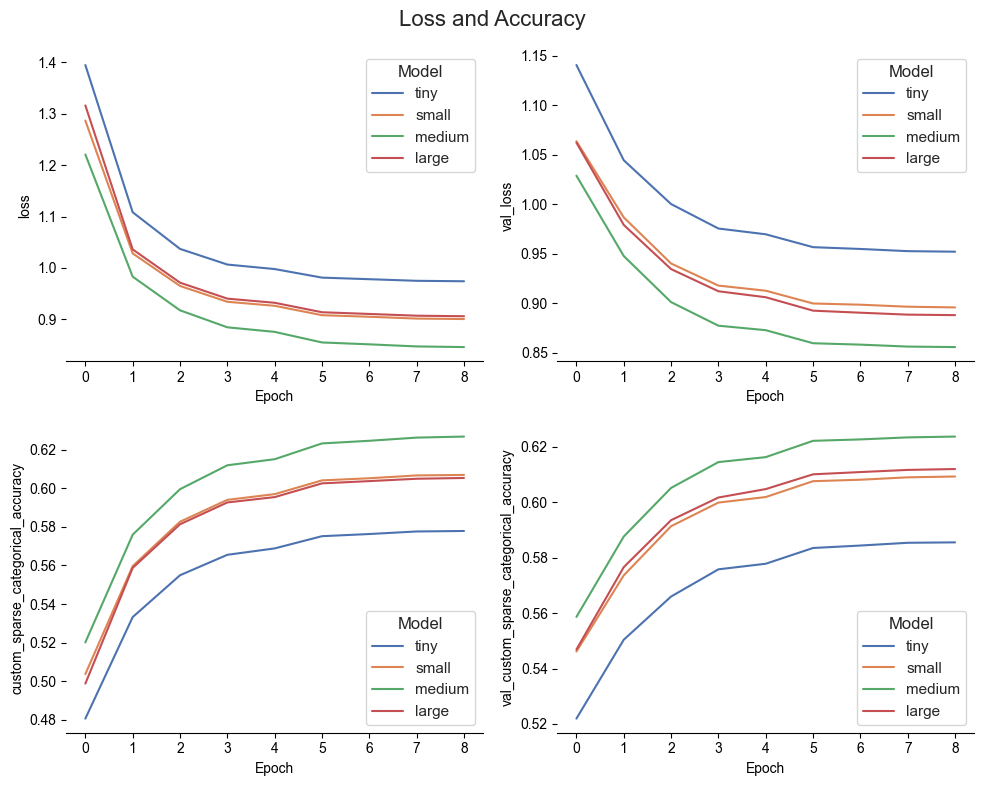
Loss and Accuracy across the four models
Part 3: The training
The train set is made of 80% of the trajectories, representing 205,851 examples. The test set is made of 20% of the trajectories, representing 51,463 examples.
Models are trained using a simple callback scheduler on 9 epochs where the learning rate start at 1e-3 and ends at 5e-4, with a batch size of 32.
The loss is a categorical crossentropy with class weights designed by occurrences’ thresholds on the train set (integers that occur more often weight less in the loss). Labels set at -100 do not count into the loss.
The metrics used are:
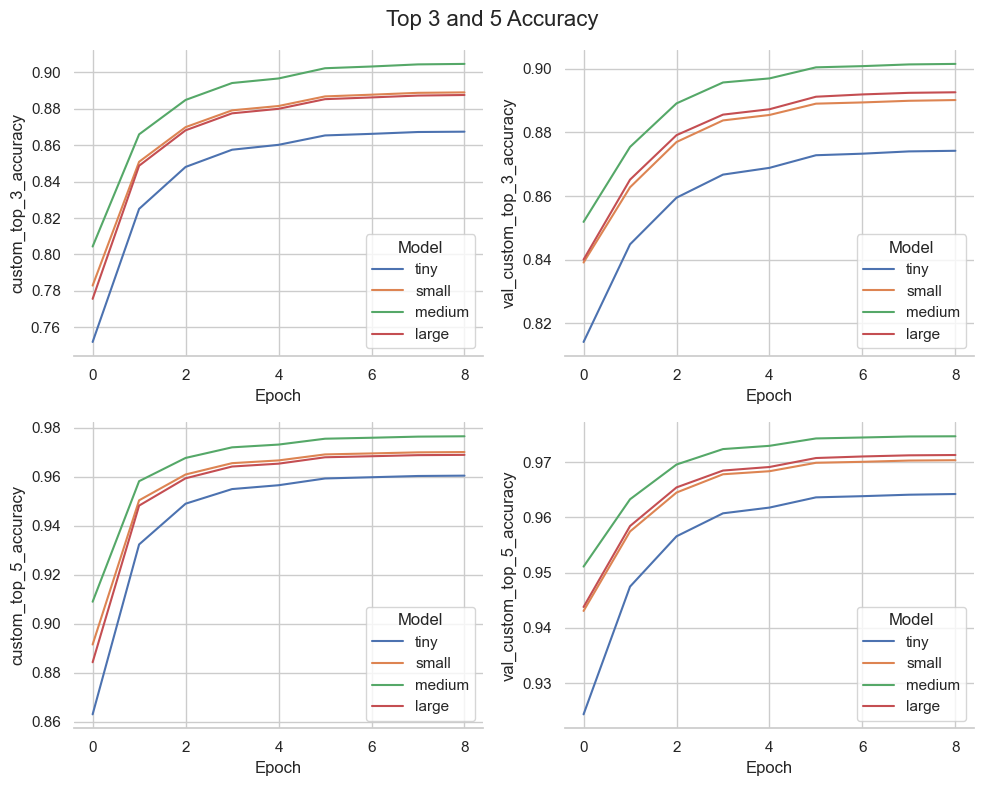
Top 3 and top 5 accuracies across the four models
Eventually, a RMSE check has been performed on the x,y coordinates associated with every movements. This check enables us to monitor that beside not predicting accurately, it does not fall to far from the truth (predicting a 1 yard squared trajectory might be difficult).
Part 4: The results
Overall, the different models still learn underlying dynamic patterns and perform relatively good on my dataset. We can see that increasing embeddings’ dimensions brings increases in the accuracy of the models. The task of guessing a 1-yard squared is definitely challenging as movements on a football field are not driven with such a tiny range.
I decided to slice those predictions in 3 categories : time, play types and positions.
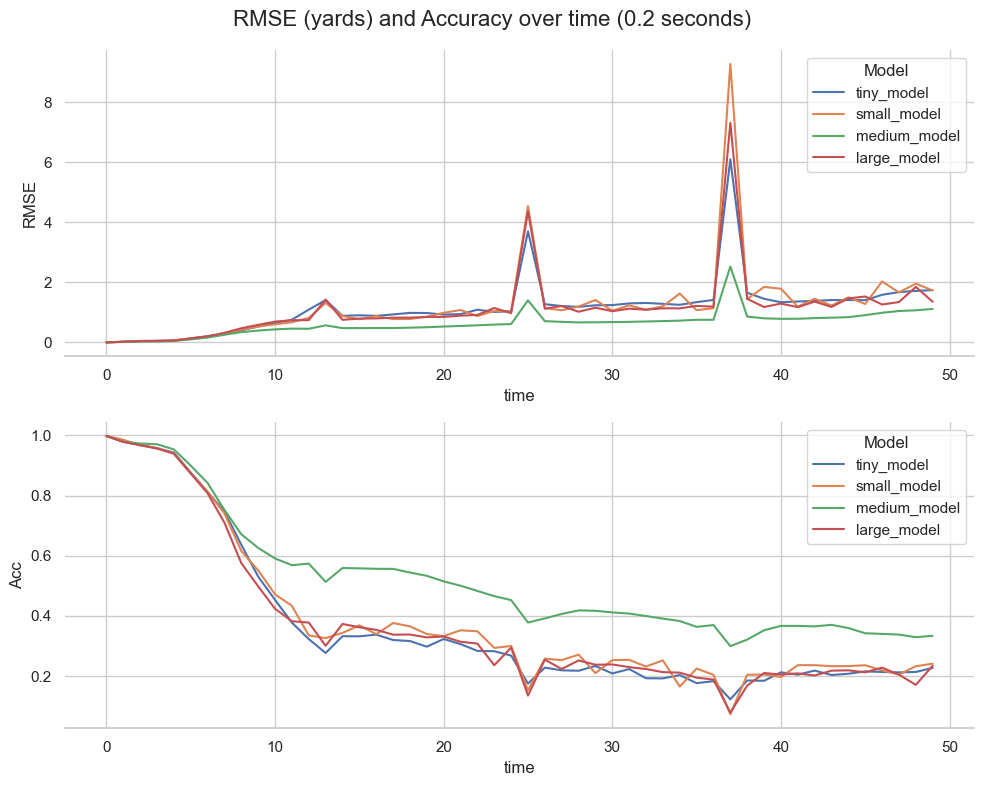
Accuracy and RMSE over time (frames)
The first 5 frames are relatively easy to predict for the model as often players are starting with similar movements. There is a drop in accuracy of 40–50% between frame 5 and 10. This is the moment where plays tend to be different and have their own paths. Among the four models, the tiny one struggles the most especially at the end of the trajectory. The medium one shows a very good performance even on long term (more than 20 frames). The peaks are related to the starts of padded trajectories as these are fed in without any past knowledge of the trajectory.
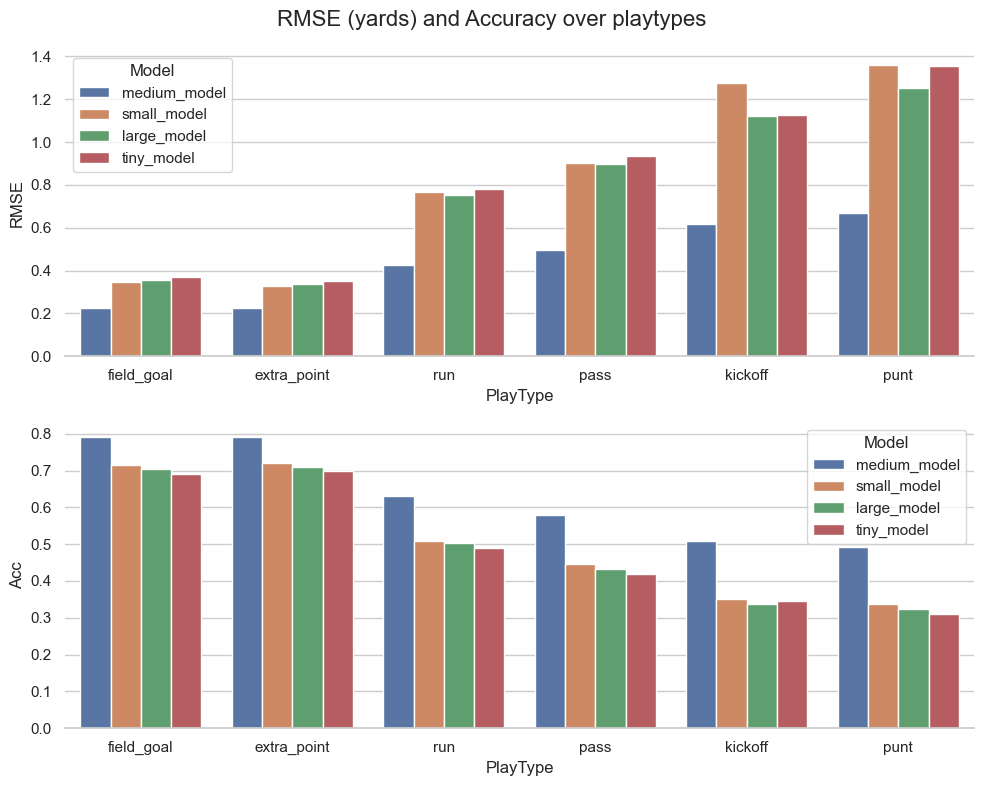
Accuracy and RMSE over play types
Plays that are relatively static are (without surprise) the easier to predict. Runs, passes, kick-offs and punts are (without surprise) the hardest to guess as players move a lot more and with possibly chaotic patterns. No significant differences among models are seen.
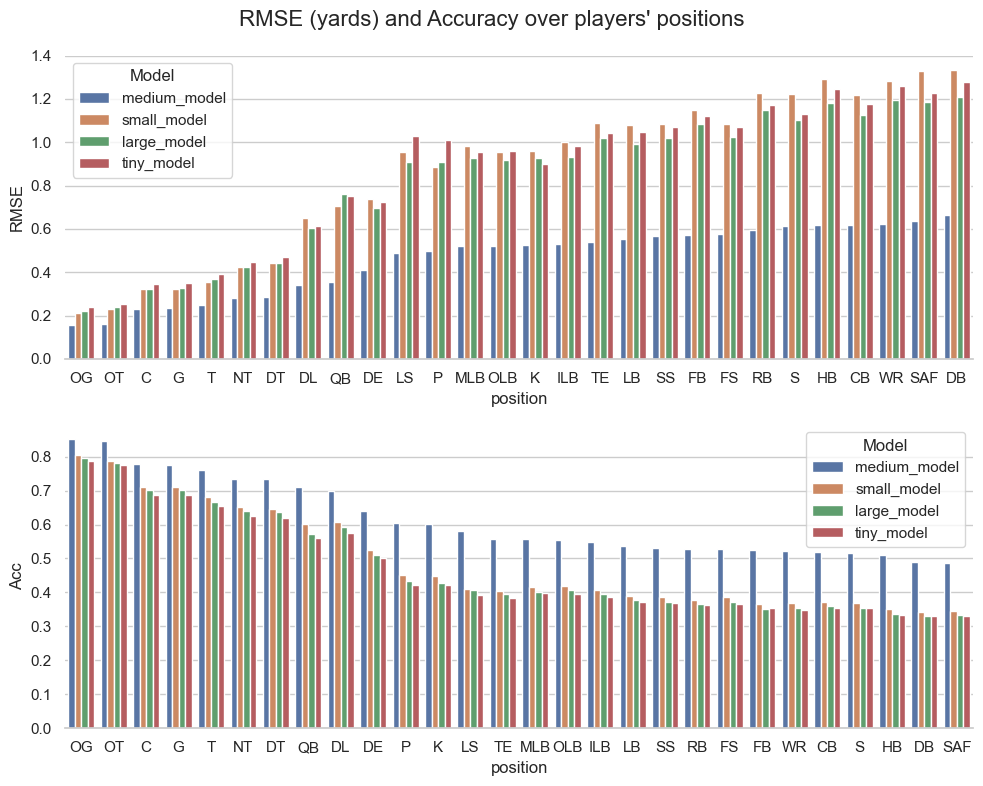
Accuracy and RMSE over positions
Position is a very discriminant factor with positions having difference between 10 to 20% in accuracy. Overall, the positions that move a lot are also the toughest to predict. The tiny and small models tend to be less accurate than the rest in general.
Part 5: What I’ve seen so far by playing with it
The model’s ideal temperature seems to be between 1.5 and 2.5. I tested a selection of 10, 20 and 50. The more you push the temperature and selection, the more it tends to get crazy and yield strange patterns (players getting off the field, changing directions, big gaps between two frames).
However, it seems to give interesting patterns that could be used for simulations and play books recognition.
What’s next ?
This model is raw. It can be used later to explore opponents strategy, define new ones and even use it to enhance the player scouting system.
However, the core idea is to see if this model can effectively predict play results effectively aka yard gains. I will soon share my work about a predicting framework for NFL plays which is based on findings in QBGPT. By using the generative abilities of such model, you can draw a great number of scenarios from which predicting plays is an easier task")
In the meantime you can play with QB-GPT at this hugging face space, if you liked this article, the work and the findings don’t forget to share and like !
(Unless otherwise noted, every images are by the author)
Samuel Chaineau : Linkedin

Transformers can generate NFL plays : introducing QB-GPT was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Bridging the gap between GenAI and sports analytics
Photo by Zetong Li on Unsplash
Since my first article about StratFormer, I received a relatively great amount of feedbacks and ideas (so first thank you !). This pushed me to deepen my work an try an extra step : building a football plays’ generator. In this article I present QB-GPT, a model that can effectively generate football plays once provided with some elements. A dedicated HuggingFace space can be found here to play with it. I will later in the month share my work and findings on how to better predict NFL plays using this kind of generative models as backbone. The industryy is also watching this field as DeepMind Safety Research is currently doing research on soccer with Liverpool on understanding how players move on the field.
Generated trajectory by QB-GPT
True trajectory
Stratformer, my first idea that I started in Oct 2021, was an encoder-only model which took a trajectory as input, tried to complete it and predicted some contextual elements associated with it (team, positions and plays). While this model showed interesting patterns (such as understanding what makes truly different a RB and a WR), it relied on a “a posteriori” look on the play. What could be even more interesting is to deeply understand how the set up of players, with some contextual elements, effectively affect the paths of the team. In other words, when the teams are facing each others at the scrimmage line, what is going to happen ?
By building such an algorithm, we are now able to build a model that “really” understands the football game, as it is basically trying to recreate plays from few elements. This is the goal of QB-GPT. GPT is here because it relies on the same concepts of decoding that use any GPT models.
This article will cover the model and the few necessary tricks that I had to implement to make it “ok”. An attached HuggingFace space is available here to generate some plays if you wish, I will keep it open a limited time depending on the cost. While I recognized it is limited and prone to a range of improvements, I think such application deserves to be shared with a broader audience. If interested to discuss it or deepen some aspects, my contacts are on the app and at the end of the article. Once again, I did this work on my own, with the dat I could find and the imperfections related to it (If someone working at the NFL/NGS team reads this, DMs more than open)
Part 1 : The data
The data required to perform such task is very very hard to find. I rely on a specific data type provided only by the Next Gen Stats (NGS) tool of the NFL, where, for any given play, I can track up to the 22 players present on the field. The problem is that this data is not accessible via a classic API request. However, since 2019, the NFL is offering a wide range of data competition on Kaggle, often provided with datasets from the NGS. Also, some people on GitHub have scrapped back in the days the NGS browser. I did not try to do it and only relied on available data that had a usable format.
An extensive time has been spent on merging data between themselves (around 200 hours). The most important tasks were to:
- Find the players on the field using nflVerse
- Associate their positions
- Define the scrimmage line using the play by play data of nflVerse
- Normalizing the trajectory by subtracting the original position of the player to each instance of the trajectory. Hence each element of the trajectory is a distance between time i and time 0.
- Converting the distances to indices (like building a vocabulary for a BERT)
- Apply some sanity checks (for instance removing players that are not on the pitch)
- Convert the data in arrays and dict format for TensorFlow
I used Polars during all the process. I strongly recommend to any data scientist, ML engineer, data engineer or people working with large volume of tabular data to quickly add this impressive package into their toolkit. TLDR: Polars is better than pandas on small dataset and better than pypsark on large ones.
All in all, I compiled 47,991 different plays representing 870,559 different players’ trajectories on the field (18 players monitored per play on average, unfortunately never one OL…).
I monitor each player’s position at a 0.2 second frame rate, representing 28,147,112 positions on the field in total. I limit the data to the first 10 seconds as the trajectories tend to be more and more chaotic after, and hence difficult to model from a probabilistic point of view.
My dataset starts in 2018 to 2022 and covers 3,190 unique players. The data is not perfect but gives a good sample and may be enough to assess whether transformers are helpful.
To summarize, my data sources are :
- The NFL Big Data Bowl of 2021 link
- The NFL Big Data Bowl of 2022 link
- The NFL Big Data Bowl of 2023 link
- Public git repo NGS Highlights link
Here under you have a scheme representing the input input embedding for a single player:
Then the eleven players are concatenated per play and then truncated by frames to always have a number of token equal to 256. I limited the number of frames for one player at 21 (max = 21*11 = 231) to make sure the we have consistently the same number of frames per player. Hence, I had to create new trajectories starting directly at a given moment of a play as most of my plays have more than 21 frames. I created a padding step of 12 frames, meaning the trajectory is now divided in sub trajectories, each time shifted by 12 frames. This process tends to make harder the task of preidction for the frames 12, 24, 36 and 48 as we will see later.
Elements can be discussed. For instance the relevance of dicing the field with a 1 yard basis or why using a 0.2 second frame rate. I think the model (so its training data) is a start and I want to acknowledge that not everything is perfect. Feedbacks and opinions are welcome as long as they are relevant.
Part 2 : The model
The model is completely inspired from the OpenAI GPT architecture. It relies on a embedding layer adding different contextual elements to the input tokens. The embeddings are then fed to a single transformers module using multi-head attention with 3 heads. In the Large model, a second transformers module is applied. The output is then fed into a dense layer with a “relu” activation. To obtain the predictions, we apply a soft-max activation.
Two tricks were needed to adapt the architecture and training :
- Multi-temporal Causal Masks : In a classic GPT, the embedding’s attention at position i can only attend to the tokens from position 0 to i-1. In our case, as I am decoding the team completely I need the tokens at time i to attend to every tokens available between time 0 and i-1. Instead of having the so-called “lower triangular mask”, you end up with a multi triangular mask.
Attention masks
Raw attention scores and after attention masks subtractions
Attention scores with different vmax scale
- Pre-Layer Normalization: Inspired by the work of Sik-Ho Tsang, I implemented its proposed Transformers module where normalization is done before multi-head attention and before FFN.
The model does not require a high number of attention layers as the underlying patterns to model are quite simple. I trained 4 different models’ architectures using the same settings. Results show that embeddings’ dimensions plays a crucial roles in the level of accuracy that we can reach while number of attention modules does not significantly improve accuracy:
- Tiny : embedding dimension of 64, representing 1,539,452 parameters
- Small : embedding dimension of 128, representing 3,182,716 parameters
- Medium : embedding dimension of 256, representing 6,813,308 parameters
- Large : embedding dimension of 128 but with two attention modules, representing 7,666,556 parameters
I think the large one could reach a better performance with an in-depth review of the scheduler.
(For comparison, GPT3 has 175 billion parameters)
The charts here under show a comparison of accuracy and loss during training between the different models:
Loss and Accuracy across the four models
Part 3: The training
The train set is made of 80% of the trajectories, representing 205,851 examples. The test set is made of 20% of the trajectories, representing 51,463 examples.
Models are trained using a simple callback scheduler on 9 epochs where the learning rate start at 1e-3 and ends at 5e-4, with a batch size of 32.
The loss is a categorical crossentropy with class weights designed by occurrences’ thresholds on the train set (integers that occur more often weight less in the loss). Labels set at -100 do not count into the loss.
The metrics used are:
- Accuracy : Is the next team movement predicted exactly the same that the one labeled ?
- Top 3 accuracy : Is the next labeled movement in the top 3 predictions ?
- Top 5 accuracy : Is the next labeled movement in the top 5 predictions ?
Top 3 and top 5 accuracies across the four models
Eventually, a RMSE check has been performed on the x,y coordinates associated with every movements. This check enables us to monitor that beside not predicting accurately, it does not fall to far from the truth (predicting a 1 yard squared trajectory might be difficult).
Part 4: The results
Overall, the different models still learn underlying dynamic patterns and perform relatively good on my dataset. We can see that increasing embeddings’ dimensions brings increases in the accuracy of the models. The task of guessing a 1-yard squared is definitely challenging as movements on a football field are not driven with such a tiny range.
I decided to slice those predictions in 3 categories : time, play types and positions.
Accuracy and RMSE over time (frames)
The first 5 frames are relatively easy to predict for the model as often players are starting with similar movements. There is a drop in accuracy of 40–50% between frame 5 and 10. This is the moment where plays tend to be different and have their own paths. Among the four models, the tiny one struggles the most especially at the end of the trajectory. The medium one shows a very good performance even on long term (more than 20 frames). The peaks are related to the starts of padded trajectories as these are fed in without any past knowledge of the trajectory.
Accuracy and RMSE over play types
Plays that are relatively static are (without surprise) the easier to predict. Runs, passes, kick-offs and punts are (without surprise) the hardest to guess as players move a lot more and with possibly chaotic patterns. No significant differences among models are seen.
Accuracy and RMSE over positions
Position is a very discriminant factor with positions having difference between 10 to 20% in accuracy. Overall, the positions that move a lot are also the toughest to predict. The tiny and small models tend to be less accurate than the rest in general.
Part 5: What I’ve seen so far by playing with it
The model’s ideal temperature seems to be between 1.5 and 2.5. I tested a selection of 10, 20 and 50. The more you push the temperature and selection, the more it tends to get crazy and yield strange patterns (players getting off the field, changing directions, big gaps between two frames).
However, it seems to give interesting patterns that could be used for simulations and play books recognition.
What’s next ?
This model is raw. It can be used later to explore opponents strategy, define new ones and even use it to enhance the player scouting system.
However, the core idea is to see if this model can effectively predict play results effectively aka yard gains. I will soon share my work about a predicting framework for NFL plays which is based on findings in QBGPT. By using the generative abilities of such model, you can draw a great number of scenarios from which predicting plays is an easier task
In the meantime you can play with QB-GPT at this hugging face space, if you liked this article, the work and the findings don’t forget to share and like !
(Unless otherwise noted, every images are by the author)
Samuel Chaineau : Linkedin
Transformers can generate NFL plays : introducing QB-GPT was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.