Use RAGAs framework with hyperparameter optimisation to boost the quality of your RAG system.

Graphic depicting the idea of “LLMs Evaluating RAGs”. It was generated by the author with help of AI in Canva.
TL;DR
If you develop a RAG system you need to choose between different design options. This is where the ragas library can help you by generating synthetic evaluation data with answers grounded in your documents. This makes possible the rigorous evaluation of a RAG system with the classic split between train/validation/test sets. As the result the quality of your RAG system will get a big boost.
Introduction
The development of Retrieval Augmented Generation (RAG) system in practice involves taking a lot of decisions that are consequential for its ultimate quality, i.e.: about text splitter, chunk size, overlap size, embedding model, metadata to store, distance metric for semantic search, top-k to rerank, reranker model, top-k to context, prompt engineering, etc.
Reality: In most cases such decisions are not grounded in methodologically sound evaluation practices, but rather driven by ad-hoc judgments of developers and product owners, often facing deadlines.
Gold Standard: In contrast the rigorous evaluation of RAG system should involve:
The generic Large Language Model (LLM) benchmarks (GLUE, SuperGlue, MMLU, BIG-Bench, HELM, …) are not of much relevance to evaluate RAGs as the essence of RAGs is to extract information from internal documents unknown to LLMs. If you insist to use LLM benchmarks for RAG system evaluation one route would be to select the task specific to your domain, and quantify the value added of the RAG system on top of bare bones LLM for this chosen task.
The alternative to generic LLM benchmarks is to create human annotated test sets based on internal documents, so that the questions require access to these internal documents in order to answer them correctly. In general such a solution is prohibitively expensive in most cases. In addition, outsourcing annotation may be problematic for internal documents, as they are sensitive or contain private information and can’t be shared with outside parties.
Here comes the RAGAs framework (Retrieval Augmented Generation Assessment) [1] for reference-free RAG evaluation, with Python implementation made available in ragas package:
pip install ragas
It provides essential tools for rigorous RAG evaluation:
Synthetic Evaluation Sets
The LLMs enthusiasts, me included, tend to suggest using LLM as a solution to many problems. Here it means:
RAGAs framework follows up on on the idea of Evol-Instruct framework, which uses LLM to generate a diverse set of instruction data (i.e. Question — Answer pairs, QA) in the evolutionary process.

Picture 1: Depicting evolution of questions in RAGAs. . Image created by the author in Canva and draw.io.
In Evol-Instruct framework LLM starts with an initial set of simple instructions, and gradually rewrites them into more complex instructions, creating a diverse instruction data as the result. Can Xu et al [2] argue that gradual, incremental, evolution instruction data is highly effective in producing high quality results. In RAGAs framework instruction data generated and evolved by LLM are grounded in available documents. The ragas library currently implements three different types of instruction data evolution by depth starting from the simple question:
In addition ragas library also provides the option to generate conversations. Now let’s see ragas in practice.
Examples of Question Evolutions
We will use the Wikipedia page on Large Language Models [3] as the source document for ragas library to generate question — ground truth pairs, one for each evolution type available.
colab-demos/rags/evaluate-rags-rigorously-or-perish.ipynb at main · gox6/colab-demos
# Installing Python packages & hiding
!pip install --quiet \
chromadb \
datasets \
langchain \
langchain_chroma \
optuna \
plotly \
polars \
ragas \
1> /dev/null
# Importing the packages
from functools import reduce
import json
import os
import requests
import warnings
import chromadb
from chromadb.api.models.Collection import Collection as ChromaCollection
from datasets import load_dataset, Dataset
from getpass import getpass
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.runnables.base import RunnableSequence
from langchain_community.document_loaders import WebBaseLoader, PolarsDataFrameLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from operator import itemgetter
import optuna
import pandas as pd
import plotly.express as px
import polars as pl
from ragas import evaluate
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
answer_correctness
)
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context, conditional
# Providing api key for OPENAI
OPENAI_API_KEY = getpass("OPENAI_API_KEY")
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
# Examining question evolution types evailable in ragas library
urls = ["https://en.wikipedia.org/wiki/Large_language_model"]
wikis_loader = WebBaseLoader(urls)
wikis = wikis_loader.load()
llm = ChatOpenAI(model="gpt-3.5-turbo")
generator_llm = llm
critic_llm = llm
embeddings = OpenAIEmbeddings()py
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Change resulting question type distribution
list_of_distributions = [{simple: 1},
{reasoning: 1},
{multi_context: 1},
{conditional: 1}]
# This step COSTS $$$ ...
question_evolution_types = list(
map(lambda x: generator.generate_with_langchain_docs(wikis, 1, x),
list_of_distributions)
)
# Displaying examples
examples = reduce(lambda x, y: pd.concat([x, y], axis=0),
[x.to_pandas() for x in question_evolution_types])
examples = examples.loc[:, ["evolution_type", "question", "ground_truth"]]
examples
Running the above code I received the following synthetic question — answer pairs based on the aforementioned Wikipedia page [3].
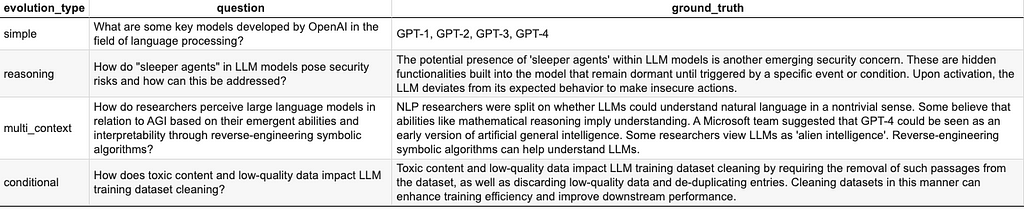
Table 1: Synthetic question — answer pairs generated using ragas library and GPT-3.5-turbo from the Wikipedia page on LLMs [3].
The results presented in the Table 1 seem very appealing, at least to me. The simple evolution performs very well. In the case of the reasoning evolution the first part of question is answered perfectly, but the second part is left unanswered. Inspecting the Wikipedia page [3] it is evident that there is no answer to the second part of the question in the actual document, so it can also be interpreted as the restraint from hallucinations, a good thing in itself. The multi-context question-answer pair seems very good. The conditional evolution type is acceptable if we look at the question-answer pair. One way of looking at these results is that there is always space for better prompt engineering that are behind evolutions. Another way is to use better LLMs, especially for the critic role as is the default in the ragas library.
Metrics
The ragas library is able to not only generate the synthetic evaluation sets, but also provides us with built-in metrics for component-wise evaluation as well as end-to-end evaluation of RAGs.
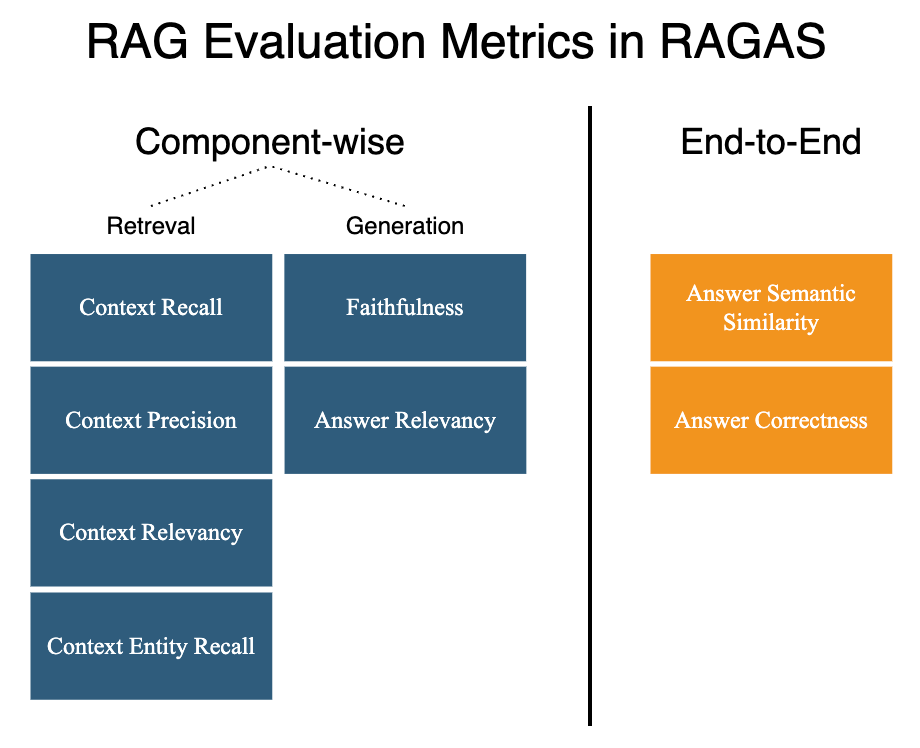
Picture 2: RAG Evaluation Metrics in RAGAS. Image created by the author in draw.io.
As of this writing RAGAS provides out-of-the-box eight metrics for RAG evaluation, see Picture 2, and likely new ones will be added in the future. In general you are about to choose the metrics most suitable for your use case. However, I recommend to select the one most important metric, i.e.:
Focusing on the one end-to-end metric helps to start the optimisation of your RAG system as fast as possible. Once you achieve some improvements in quality you can look at component-wise metrics, focusing on the most important one for each RAG component:
RAG Factory
OK, so we have a RAG ready for optimisation… not so fast, this is not enough. To optimise RAG we need the factory function to generate RAG chains with given set of RAG hyperparameters. Here we define this factory function in 2 steps:
Step 1: A function to store documents in the vector database.
# Defining a function to get document collection from vector db with given hyperparemeters
# The function embeds the documents only if collection is missing
# This development version as for production one would rather implement document level check
def get_vectordb_collection(chroma_client,
documents,
embedding_model="text-embedding-ada-002",
chunk_size=None, overlap_size=0) -> ChromaCollection:
if chunk_size is None:
collection_name = "full_text"
docs_pp = documents
else:
collection_name = f"{embedding_model}_chunk{chunk_size}_overlap{overlap_size}"
text_splitter = CharacterTextSplitter(
separator=".",
chunk_size=chunk_size,
chunk_overlap=overlap_size,
length_function=len,
is_separator_regex=False,
)
docs_pp = text_splitter.transform_documents(documents)
embedding = OpenAIEmbeddings(model=embedding_model)
langchain_chroma = Chroma(client=chroma_client,
collection_name=collection_name,
embedding_function=embedding,
)
existing_collections = [collection.name for collection in chroma_client.list_collections()]
if chroma_client.get_collection(collection_name).count() == 0:
langchain_chroma.from_documents(collection_name=collection_name,
documents=docs_pp,
embedding=embedding)
return langchain_chroma
Step 2: A function to generate RAG in LangChain with document collection, or the proper RAG factory function.
# Defininig a function to get a simple RAG as Langchain chain with given hyperparemeters
# RAG returns also the context documents retrieved for evaluation purposes in RAGAs
def get_chain(chroma_client,
documents,
embedding_model="text-embedding-ada-002",
llm_model="gpt-3.5-turbo",
chunk_size=None,
overlap_size=0,
top_k=4,
lambda_mult=0.25) -> RunnableSequence:
vectordb_collection = get_vectordb_collection(chroma_client=chroma_client,
documents=documents,
embedding_model=embedding_model,
chunk_size=chunk_size,
overlap_size=overlap_size)
retriever = vectordb_collection.as_retriever(top_k=top_k, lambda_mult=lambda_mult)
template = """Answer the question based only on the following context.
If the context doesn't contain entities present in the question say you don't know.
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(model=llm_model)
def format_docs(docs):
return "\n\n".join([doc.page_content for doc in docs])
chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
chain_with_context_and_ground_truth = RunnableParallel(
context=itemgetter("question") | retriever,
question=itemgetter("question"),
ground_truth=itemgetter("ground_truth"),
).assign(answer=chain_from_docs)
return chain_with_context_and_ground_truth
The former function get_vectordb_collection is incorporated into the latter function get_chain, which generates our RAG chain for given set of parameters, i.e: embedding_model, llm_model, chunk_size, overlap_size, top_k, lambda_mult. With our factory function we are just scratching the surface of possibilities what hyperparmeters of our RAG system we optimise. Note also that RAG chain will require 2 arguments: question and ground_truth, where the latter is just passed through the RAG chain as it is required for evaluation using RAGAs.
# Setting up a ChromaDB client
chroma_client = chromadb.EphemeralClient()
# Testing full text rag
with warnings.catch_warnings():
rag_prototype = get_chain(chroma_client=chroma_client,
documents=news,
chunk_size=1000,
overlap_size=200)
rag_prototype.invoke({"question": 'What happened in Minneapolis to the bridge?',
"ground_truth": "x"})["answer"]
RAG Evaluation
To evaluate our RAG we will use the diverse dataset of news articles from CNN and Daily Mail, which is available on Hugging Face [4]. Most articles in this dataset are below 1000 words. In addition we will use the tiny extract from the dataset of just 100 news articles. This is all done to limit the costs and time needed to run the demo.
# Getting the tiny extract of CCN Daily Mail dataset
synthetic_evaluation_set_url = "View: https://gist.github.com/gox6/0858a1ae2d6e3642aa132674650f9c76/raw/synthetic-evaluation-set-cnn-daily-mail.csv
"
synthetic_evaluation_set_pl = pl.read_csv(synthetic_evaluation_set_url, separator=",").drop("index")
# Train/test split
# We need at least 2 sets: train and test for RAG optimization.
shuffled = synthetic_evaluation_set_pl.sample(fraction=1,
shuffle=True,
seed=6)
test_fraction = 0.5
test_n = round(len(synthetic_evaluation_set_pl) * test_fraction)
train, test = (shuffled.head(-test_n),
shuffled.head( test_n))
As we will consider many different RAG prototypes beyond the one define above we need a function to collect answers generated by the RAG on our synthetic evaluation set:
# We create the helper function to generate the RAG ansers together with Ground Truth based on synthetic evaluation set
# The dataset for RAGAS evaluation should contain the columns: question, answer, ground_truth, contexts
# RAGAs expects the data in Huggingface Dataset format
def generate_rag_answers_for_synthetic_questions(chain,
synthetic_evaluation_set) -> pl.DataFrame:
df = pl.DataFrame()
for row in synthetic_evaluation_set.iter_rows(named=True):
rag_output = chain.invoke({"question": row["question"],
"ground_truth": row["ground_truth"]})
rag_output["contexts"] = [doc.page_content for doc
in rag_output["context"]]
del rag_output["context"]
rag_output_pp = {k: [v] for k, v in rag_output.items()}
df = pl.concat([df, pl.DataFrame(rag_output_pp)], how="vertical")
return df
RAG Optimisation with RAGAs and Optuna
First, it is worth emphasising that the proper optimisation of RAG system should involve global optimisation, where all parameters are optimised at once, in contrast to the sequential or greedy approach, where parameters are optimised one by one. The sequential approach ignores the fact that there can be interactions between the parameters, which can result in sub-optimal solution.
Now at last we are ready to optimise our RAG system. We will use hyperparameter optimisation framework Optuna. To this end we define the objective function for the Optuna’s study specifying the allowed hyperparameter space as well as computing the evaluation metric, see the code below:
def objective(trial):
embedding_model = trial.suggest_categorical(name="embedding_model",
choices=["text-embedding-ada-002", 'text-embedding-3-small'])
chunk_size = trial.suggest_int(name="chunk_size",
low=500,
high=1000,
step=100)
overlap_size = trial.suggest_int(name="overlap_size",
low=100,
high=400,
step=50)
top_k = trial.suggest_int(name="top_k",
low=1,
high=10,
step=1)
challenger_chain = get_chain(chroma_client,
news,
embedding_model=embedding_model,
llm_model="gpt-3.5-turbo",
chunk_size=chunk_size,
overlap_size= overlap_size ,
top_k=top_k,
lambda_mult=0.25)
challenger_answers_pl = generate_rag_answers_for_synthetic_questions(challenger_chain , train)
challenger_answers_hf = Dataset.from_pandas(challenger_answers_pl.to_pandas())
challenger_result = evaluate(challenger_answers_hf,
metrics=[answer_correctness],
)
return challenger_result['answer_correctness']
Finally, having the objective function we define and run the study to optimise our RAG system in Optuna. It’s worth noting that we can add to the study our educated guesses of hyperparameters with the method enqueue_trial, as well as limit the study by time or number of trials, see the Optuna’s docs for more tips.
sampler = optuna.samplers.TPESampler(seed=6)
study = optuna.create_study(study_name="RAG Optimisation",
direction="maximize",
sampler=sampler)
study.set_metric_names(['answer_correctness'])
educated_guess = {"embedding_model": "text-embedding-3-small",
"chunk_size": 1000,
"overlap_size": 200,
"top_k": 3}
study.enqueue_trial(educated_guess)
print(f"Sampler is {study.sampler.__class__.__name__}")
study.optimize(objective, timeout=180)
In our study the educated guess wasn’t confirmed, but I’m sure that with rigorous approach as the one proposed above it will get better.
Best trial with answer_correctness: 0.700130617593832
Hyper-parameters for the best trial: {'embedding_model': 'text-embedding-ada-002', 'chunk_size': 700, 'overlap_size': 400, 'top_k': 9}
Limitations of RAGAs
After experimenting with ragas library to synthesise evaluations sets and to evaluate RAGs I have some caveats:
The first 2 caveats are quality related. The root cause of them may be in the LLM used, and obviously GPT-4 gives better results than GPT-3.5-Turbo. At the same time it seems that this could be improved by some prompt engineering for evolutions used to generate synthetic evaluation sets.
As for issues with rate-limiting and network overflows it is advisable to use: 1) checkpointing during generation of synthetic evaluation sets to prevent loss of of created data, and 2) exponential backoff to make sure you complete the whole task.
Finally and most importantly, more built-in evolutions would be welcome addition for the ragas package. Not to mention the possibility of creating custom evolutions more easily.
Other Useful Features of RAGAs
Conclusions
Despite RAGAs limitations do NOT miss the most important thing:
Acknowledgements
Obviously this project & article would be impossible if I didn’t stand on the shoulders of giants. It is impossible to mention all influences, but the following were directly related:
[1] S. Es, J. James, L. Espinosa-Anke, S. Schockaert, RAGAS: Automated Evaluation of Retrieval Augmented Generation (2023),
arXiv:2309.15217
[2] C. Xu, Q. Sun, K. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, D. Jiang, WizardLM: Empowering Large Language Models to Follow Complex Instructions (2023), arXiv:2304.12244
[3] Community, Large Language Models, Wikipedia (2024), https://en.wikipedia.org/wiki/Large_language_model
[4] CNN & Daily Mail Dataset available on Hugging Face, for more info see: https://huggingface.co/datasets/cnn_dailymail

Evaluate RAGs Rigorously or Perish was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Graphic depicting the idea of “LLMs Evaluating RAGs”. It was generated by the author with help of AI in Canva.
TL;DR
If you develop a RAG system you need to choose between different design options. This is where the ragas library can help you by generating synthetic evaluation data with answers grounded in your documents. This makes possible the rigorous evaluation of a RAG system with the classic split between train/validation/test sets. As the result the quality of your RAG system will get a big boost.
Introduction
The development of Retrieval Augmented Generation (RAG) system in practice involves taking a lot of decisions that are consequential for its ultimate quality, i.e.: about text splitter, chunk size, overlap size, embedding model, metadata to store, distance metric for semantic search, top-k to rerank, reranker model, top-k to context, prompt engineering, etc.
Reality: In most cases such decisions are not grounded in methodologically sound evaluation practices, but rather driven by ad-hoc judgments of developers and product owners, often facing deadlines.
Gold Standard: In contrast the rigorous evaluation of RAG system should involve:
- a large evaluation set, so that performance metrics are estimated with low confidence intervals
- diverse questions in an evaluation set
- answers specific to the internal documents
- separate evaluation of retrieval and generation
- evaluation of the RAG as the whole
- train/validation/test split to ensure good generalisation ability
- hyperparameter optimisation
Most RAG systems are NOT evaluated rigorously up to the Gold Standard due to lack of evaluation sets with answers grounded in the private documents!
The generic Large Language Model (LLM) benchmarks (GLUE, SuperGlue, MMLU, BIG-Bench, HELM, …) are not of much relevance to evaluate RAGs as the essence of RAGs is to extract information from internal documents unknown to LLMs. If you insist to use LLM benchmarks for RAG system evaluation one route would be to select the task specific to your domain, and quantify the value added of the RAG system on top of bare bones LLM for this chosen task.
The alternative to generic LLM benchmarks is to create human annotated test sets based on internal documents, so that the questions require access to these internal documents in order to answer them correctly. In general such a solution is prohibitively expensive in most cases. In addition, outsourcing annotation may be problematic for internal documents, as they are sensitive or contain private information and can’t be shared with outside parties.
Here comes the RAGAs framework (Retrieval Augmented Generation Assessment) [1] for reference-free RAG evaluation, with Python implementation made available in ragas package:
pip install ragas
It provides essential tools for rigorous RAG evaluation:
- generation of synthetic evaluation sets
- metrics specialised for RAG evaluation
- prompt adaptation to deal with non-English languages
- integration with LangChain and Llama-Index
Synthetic Evaluation Sets
The LLMs enthusiasts, me included, tend to suggest using LLM as a solution to many problems. Here it means:
LLMs are not autonomous, but may be useful. RAGAs employs LLMs to generate synthetic evaluation sets to evaluate RAG systems.
RAGAs framework follows up on on the idea of Evol-Instruct framework, which uses LLM to generate a diverse set of instruction data (i.e. Question — Answer pairs, QA) in the evolutionary process.
Picture 1: Depicting evolution of questions in RAGAs. . Image created by the author in Canva and draw.io.
In Evol-Instruct framework LLM starts with an initial set of simple instructions, and gradually rewrites them into more complex instructions, creating a diverse instruction data as the result. Can Xu et al [2] argue that gradual, incremental, evolution instruction data is highly effective in producing high quality results. In RAGAs framework instruction data generated and evolved by LLM are grounded in available documents. The ragas library currently implements three different types of instruction data evolution by depth starting from the simple question:
- Reasoning: Rewrite the question to increase the need for reasoning.
- Conditioning: Rewrite the question to introduce a conditional element.
- Multi-Context: Rewrite the question to requires many documents or chunks to answer it.
In addition ragas library also provides the option to generate conversations. Now let’s see ragas in practice.
Examples of Question Evolutions
We will use the Wikipedia page on Large Language Models [3] as the source document for ragas library to generate question — ground truth pairs, one for each evolution type available.
To run the code: You can follow the code snippets in the article or access the notebook with all the related code on Github to run on Colab or locally:
colab-demos/rags/evaluate-rags-rigorously-or-perish.ipynb at main · gox6/colab-demos
# Installing Python packages & hiding
!pip install --quiet \
chromadb \
datasets \
langchain \
langchain_chroma \
optuna \
plotly \
polars \
ragas \
1> /dev/null
# Importing the packages
from functools import reduce
import json
import os
import requests
import warnings
import chromadb
from chromadb.api.models.Collection import Collection as ChromaCollection
from datasets import load_dataset, Dataset
from getpass import getpass
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.runnables.base import RunnableSequence
from langchain_community.document_loaders import WebBaseLoader, PolarsDataFrameLoader
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from operator import itemgetter
import optuna
import pandas as pd
import plotly.express as px
import polars as pl
from ragas import evaluate
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
answer_correctness
)
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple, reasoning, multi_context, conditional
# Providing api key for OPENAI
OPENAI_API_KEY = getpass("OPENAI_API_KEY")
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
# Examining question evolution types evailable in ragas library
urls = ["https://en.wikipedia.org/wiki/Large_language_model"]
wikis_loader = WebBaseLoader(urls)
wikis = wikis_loader.load()
llm = ChatOpenAI(model="gpt-3.5-turbo")
generator_llm = llm
critic_llm = llm
embeddings = OpenAIEmbeddings()py
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings
)
# Change resulting question type distribution
list_of_distributions = [{simple: 1},
{reasoning: 1},
{multi_context: 1},
{conditional: 1}]
# This step COSTS $$$ ...
question_evolution_types = list(
map(lambda x: generator.generate_with_langchain_docs(wikis, 1, x),
list_of_distributions)
)
# Displaying examples
examples = reduce(lambda x, y: pd.concat([x, y], axis=0),
[x.to_pandas() for x in question_evolution_types])
examples = examples.loc[:, ["evolution_type", "question", "ground_truth"]]
examples
Running the above code I received the following synthetic question — answer pairs based on the aforementioned Wikipedia page [3].
Table 1: Synthetic question — answer pairs generated using ragas library and GPT-3.5-turbo from the Wikipedia page on LLMs [3].
The results presented in the Table 1 seem very appealing, at least to me. The simple evolution performs very well. In the case of the reasoning evolution the first part of question is answered perfectly, but the second part is left unanswered. Inspecting the Wikipedia page [3] it is evident that there is no answer to the second part of the question in the actual document, so it can also be interpreted as the restraint from hallucinations, a good thing in itself. The multi-context question-answer pair seems very good. The conditional evolution type is acceptable if we look at the question-answer pair. One way of looking at these results is that there is always space for better prompt engineering that are behind evolutions. Another way is to use better LLMs, especially for the critic role as is the default in the ragas library.
Metrics
The ragas library is able to not only generate the synthetic evaluation sets, but also provides us with built-in metrics for component-wise evaluation as well as end-to-end evaluation of RAGs.
Picture 2: RAG Evaluation Metrics in RAGAS. Image created by the author in draw.io.
As of this writing RAGAS provides out-of-the-box eight metrics for RAG evaluation, see Picture 2, and likely new ones will be added in the future. In general you are about to choose the metrics most suitable for your use case. However, I recommend to select the one most important metric, i.e.:
Answer Correctness — the end-to-end metric with scores between 0 and 1, the higher the better, measuring the accuracy of the generated answer as compared to the ground truth.
Focusing on the one end-to-end metric helps to start the optimisation of your RAG system as fast as possible. Once you achieve some improvements in quality you can look at component-wise metrics, focusing on the most important one for each RAG component:
Faithfulness — the generation metric with scores between 0 and 1, the higher the better, measuring the factual consistency of the generated answer relative to the provided context. It is about grounding the generated answer as much as possible in the provided context, and by doing so prevent hallucinations.
Context Relevance — the retrieval metric with scores between 0 and 1, the higher the better, measuring the relevancy of retrieved context relative to the question.
RAG Factory
OK, so we have a RAG ready for optimisation… not so fast, this is not enough. To optimise RAG we need the factory function to generate RAG chains with given set of RAG hyperparameters. Here we define this factory function in 2 steps:
Step 1: A function to store documents in the vector database.
# Defining a function to get document collection from vector db with given hyperparemeters
# The function embeds the documents only if collection is missing
# This development version as for production one would rather implement document level check
def get_vectordb_collection(chroma_client,
documents,
embedding_model="text-embedding-ada-002",
chunk_size=None, overlap_size=0) -> ChromaCollection:
if chunk_size is None:
collection_name = "full_text"
docs_pp = documents
else:
collection_name = f"{embedding_model}_chunk{chunk_size}_overlap{overlap_size}"
text_splitter = CharacterTextSplitter(
separator=".",
chunk_size=chunk_size,
chunk_overlap=overlap_size,
length_function=len,
is_separator_regex=False,
)
docs_pp = text_splitter.transform_documents(documents)
embedding = OpenAIEmbeddings(model=embedding_model)
langchain_chroma = Chroma(client=chroma_client,
collection_name=collection_name,
embedding_function=embedding,
)
existing_collections = [collection.name for collection in chroma_client.list_collections()]
if chroma_client.get_collection(collection_name).count() == 0:
langchain_chroma.from_documents(collection_name=collection_name,
documents=docs_pp,
embedding=embedding)
return langchain_chroma
Step 2: A function to generate RAG in LangChain with document collection, or the proper RAG factory function.
# Defininig a function to get a simple RAG as Langchain chain with given hyperparemeters
# RAG returns also the context documents retrieved for evaluation purposes in RAGAs
def get_chain(chroma_client,
documents,
embedding_model="text-embedding-ada-002",
llm_model="gpt-3.5-turbo",
chunk_size=None,
overlap_size=0,
top_k=4,
lambda_mult=0.25) -> RunnableSequence:
vectordb_collection = get_vectordb_collection(chroma_client=chroma_client,
documents=documents,
embedding_model=embedding_model,
chunk_size=chunk_size,
overlap_size=overlap_size)
retriever = vectordb_collection.as_retriever(top_k=top_k, lambda_mult=lambda_mult)
template = """Answer the question based only on the following context.
If the context doesn't contain entities present in the question say you don't know.
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(model=llm_model)
def format_docs(docs):
return "\n\n".join([doc.page_content for doc in docs])
chain_from_docs = (
RunnablePassthrough.assign(context=(lambda x: format_docs(x["context"])))
| prompt
| llm
| StrOutputParser()
)
chain_with_context_and_ground_truth = RunnableParallel(
context=itemgetter("question") | retriever,
question=itemgetter("question"),
ground_truth=itemgetter("ground_truth"),
).assign(answer=chain_from_docs)
return chain_with_context_and_ground_truth
The former function get_vectordb_collection is incorporated into the latter function get_chain, which generates our RAG chain for given set of parameters, i.e: embedding_model, llm_model, chunk_size, overlap_size, top_k, lambda_mult. With our factory function we are just scratching the surface of possibilities what hyperparmeters of our RAG system we optimise. Note also that RAG chain will require 2 arguments: question and ground_truth, where the latter is just passed through the RAG chain as it is required for evaluation using RAGAs.
# Setting up a ChromaDB client
chroma_client = chromadb.EphemeralClient()
# Testing full text rag
with warnings.catch_warnings():
rag_prototype = get_chain(chroma_client=chroma_client,
documents=news,
chunk_size=1000,
overlap_size=200)
rag_prototype.invoke({"question": 'What happened in Minneapolis to the bridge?',
"ground_truth": "x"})["answer"]
RAG Evaluation
To evaluate our RAG we will use the diverse dataset of news articles from CNN and Daily Mail, which is available on Hugging Face [4]. Most articles in this dataset are below 1000 words. In addition we will use the tiny extract from the dataset of just 100 news articles. This is all done to limit the costs and time needed to run the demo.
# Getting the tiny extract of CCN Daily Mail dataset
synthetic_evaluation_set_url = "View: https://gist.github.com/gox6/0858a1ae2d6e3642aa132674650f9c76/raw/synthetic-evaluation-set-cnn-daily-mail.csv
"
synthetic_evaluation_set_pl = pl.read_csv(synthetic_evaluation_set_url, separator=",").drop("index")
# Train/test split
# We need at least 2 sets: train and test for RAG optimization.
shuffled = synthetic_evaluation_set_pl.sample(fraction=1,
shuffle=True,
seed=6)
test_fraction = 0.5
test_n = round(len(synthetic_evaluation_set_pl) * test_fraction)
train, test = (shuffled.head(-test_n),
shuffled.head( test_n))
As we will consider many different RAG prototypes beyond the one define above we need a function to collect answers generated by the RAG on our synthetic evaluation set:
# We create the helper function to generate the RAG ansers together with Ground Truth based on synthetic evaluation set
# The dataset for RAGAS evaluation should contain the columns: question, answer, ground_truth, contexts
# RAGAs expects the data in Huggingface Dataset format
def generate_rag_answers_for_synthetic_questions(chain,
synthetic_evaluation_set) -> pl.DataFrame:
df = pl.DataFrame()
for row in synthetic_evaluation_set.iter_rows(named=True):
rag_output = chain.invoke({"question": row["question"],
"ground_truth": row["ground_truth"]})
rag_output["contexts"] = [doc.page_content for doc
in rag_output["context"]]
del rag_output["context"]
rag_output_pp = {k: [v] for k, v in rag_output.items()}
df = pl.concat([df, pl.DataFrame(rag_output_pp)], how="vertical")
return df
RAG Optimisation with RAGAs and Optuna
First, it is worth emphasising that the proper optimisation of RAG system should involve global optimisation, where all parameters are optimised at once, in contrast to the sequential or greedy approach, where parameters are optimised one by one. The sequential approach ignores the fact that there can be interactions between the parameters, which can result in sub-optimal solution.
Now at last we are ready to optimise our RAG system. We will use hyperparameter optimisation framework Optuna. To this end we define the objective function for the Optuna’s study specifying the allowed hyperparameter space as well as computing the evaluation metric, see the code below:
def objective(trial):
embedding_model = trial.suggest_categorical(name="embedding_model",
choices=["text-embedding-ada-002", 'text-embedding-3-small'])
chunk_size = trial.suggest_int(name="chunk_size",
low=500,
high=1000,
step=100)
overlap_size = trial.suggest_int(name="overlap_size",
low=100,
high=400,
step=50)
top_k = trial.suggest_int(name="top_k",
low=1,
high=10,
step=1)
challenger_chain = get_chain(chroma_client,
news,
embedding_model=embedding_model,
llm_model="gpt-3.5-turbo",
chunk_size=chunk_size,
overlap_size= overlap_size ,
top_k=top_k,
lambda_mult=0.25)
challenger_answers_pl = generate_rag_answers_for_synthetic_questions(challenger_chain , train)
challenger_answers_hf = Dataset.from_pandas(challenger_answers_pl.to_pandas())
challenger_result = evaluate(challenger_answers_hf,
metrics=[answer_correctness],
)
return challenger_result['answer_correctness']
Finally, having the objective function we define and run the study to optimise our RAG system in Optuna. It’s worth noting that we can add to the study our educated guesses of hyperparameters with the method enqueue_trial, as well as limit the study by time or number of trials, see the Optuna’s docs for more tips.
sampler = optuna.samplers.TPESampler(seed=6)
study = optuna.create_study(study_name="RAG Optimisation",
direction="maximize",
sampler=sampler)
study.set_metric_names(['answer_correctness'])
educated_guess = {"embedding_model": "text-embedding-3-small",
"chunk_size": 1000,
"overlap_size": 200,
"top_k": 3}
study.enqueue_trial(educated_guess)
print(f"Sampler is {study.sampler.__class__.__name__}")
study.optimize(objective, timeout=180)
In our study the educated guess wasn’t confirmed, but I’m sure that with rigorous approach as the one proposed above it will get better.
Best trial with answer_correctness: 0.700130617593832
Hyper-parameters for the best trial: {'embedding_model': 'text-embedding-ada-002', 'chunk_size': 700, 'overlap_size': 400, 'top_k': 9}
Limitations of RAGAs
After experimenting with ragas library to synthesise evaluations sets and to evaluate RAGs I have some caveats:
- The question may contain the answer.
- The ground-truth is just the literal excerpt from the document.
- Issues with RateLimitError as well as network overflows on Colab.
- Built-in evolutions are few and there is no easy way to add new, ones.
- There is room for improvements in documentation.
The first 2 caveats are quality related. The root cause of them may be in the LLM used, and obviously GPT-4 gives better results than GPT-3.5-Turbo. At the same time it seems that this could be improved by some prompt engineering for evolutions used to generate synthetic evaluation sets.
As for issues with rate-limiting and network overflows it is advisable to use: 1) checkpointing during generation of synthetic evaluation sets to prevent loss of of created data, and 2) exponential backoff to make sure you complete the whole task.
Finally and most importantly, more built-in evolutions would be welcome addition for the ragas package. Not to mention the possibility of creating custom evolutions more easily.
Other Useful Features of RAGAs
- Custom Prompts. The ragas package provides you with the option to change the prompts used in the provided abstractions. The example of custom prompts for metrics in the evaluation task is described in the docs. Below I use custom prompts for modifying evolutions to mitigate quality issues.
- Automatic Language Adaptation. RAGAs has you covered for non-English languages. It has a great feature called automatic language adaptation supporting RAG evaluation in the languages other than English, see the docs for more info.
Conclusions
Despite RAGAs limitations do NOT miss the most important thing:
RAGAs is already very useful tool despite its young age. It enables generation of synthetic evaluation set for rigorous RAG evaluation, a critical aspect for successful RAG development.
If you enjoyed reading this article consider helping me promote it to the other readers, please clap or respond. I invite You to look at my other articles! Consider subscribing to my new content.
Acknowledgements
Obviously this project & article would be impossible if I didn’t stand on the shoulders of giants. It is impossible to mention all influences, but the following were directly related:
[1] S. Es, J. James, L. Espinosa-Anke, S. Schockaert, RAGAS: Automated Evaluation of Retrieval Augmented Generation (2023),
arXiv:2309.15217
[2] C. Xu, Q. Sun, K. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, D. Jiang, WizardLM: Empowering Large Language Models to Follow Complex Instructions (2023), arXiv:2304.12244
[3] Community, Large Language Models, Wikipedia (2024), https://en.wikipedia.org/wiki/Large_language_model
[4] CNN & Daily Mail Dataset available on Hugging Face, for more info see: https://huggingface.co/datasets/cnn_dailymail
Evaluate RAGs Rigorously or Perish was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.