A cheaper and faster unified fine-tuning technique

Image generated with DALL-E 3 by author
ORPO is a new exciting fine-tuning technique that combines the traditional supervised fine-tuning and preference alignment stages into a single process. This reduces the computational resources and time required for training. Moreover, empirical results demonstrate that ORPO outperforms other alignment methods on various model sizes and benchmarks.
In this article, we will fine-tune the new Llama 3 8B model using ORPO with the TRL library. The code is available on Google Colab and in the LLM Course on GitHub.
⚖️ ORPO
Instruction tuning and preference alignment are essential techniques for adapting Large Language Models (LLMs) to specific tasks. Traditionally, this involves a multi-stage process: 1/ Supervised Fine-Tuning (SFT) on instructions to adapt the model to the target domain, followed by 2/ preference alignment methods like Reinforcement Learning with Human Feedback (RLHF) or Direct Preference Optimization (DPO) to increase the likelihood of generating preferred responses over rejected ones.
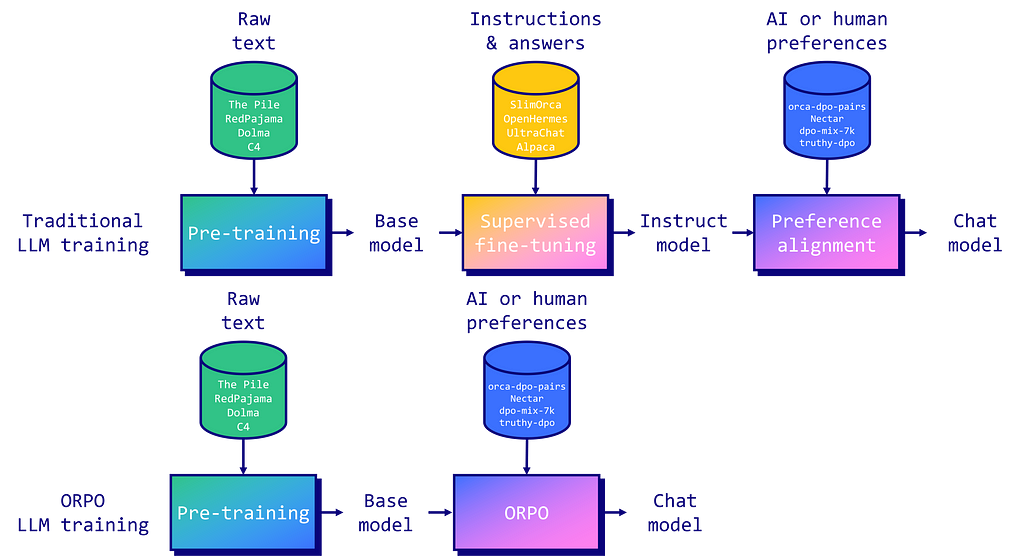
Image by author
However, researchers have identified a limitation in this approach. While SFT effectively adapts the model to the desired domain, it inadvertently increases the probability of generating undesirable answers alongside preferred ones. This is why the preference alignment stage is necessary to widen the gap between the likelihoods of preferred and rejected outputs.
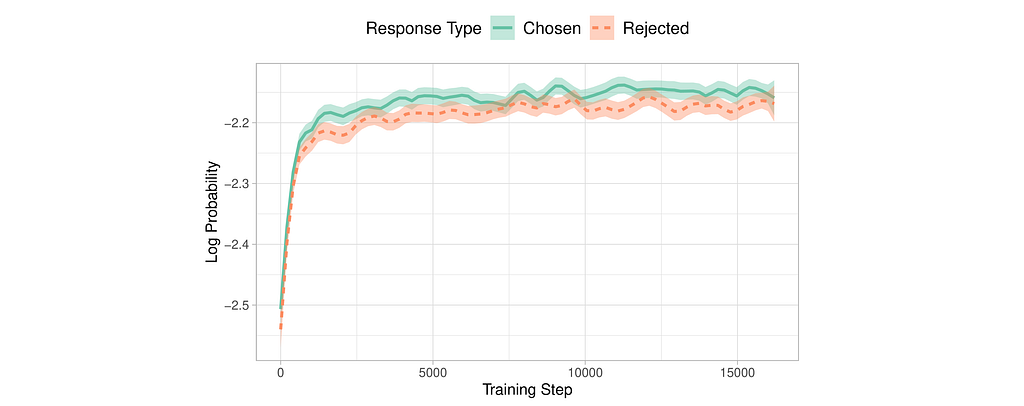
Note how the probability of rejected responses increases during supervised fine-tuning (image from the ORPO paper).
Introduced by Hong and Lee (2024), ORPO offers an elegant solution to this problem by combining instruction tuning and preference alignment into a single, monolithic training process. ORPO modifies the standard language modeling objective, combining the negative log-likelihood loss with an odds ratio (OR) term. This OR loss weakly penalizes rejected responses while strongly rewarding preferred ones, allowing the model to simultaneously learn the target task and align with human preferences.
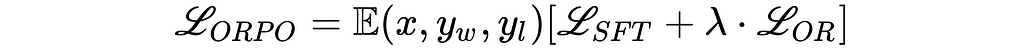
ORPO has been implemented in the major fine-tuning libraries, like TRL, Axolotl, and LLaMA-Factory. In the next section, we will see how to use with TRL.
? Fine-tuning Llama 3 with ORPO
Llama 3 is the latest family of LLMs developed by Meta. The models were trained on an extensive dataset of 15 trillion tokens (compared to 2T tokens for Llama 2). Two model sizes have been released: a 70 billion parameter model and a smaller 8 billion parameter model. The 70B model has already demonstrated impressive performance, scoring 82 on the MMLU benchmark and 81.7 on the HumanEval benchmark.
Llama 3 models also increased the context length up to 8,192 tokens (4,096 tokens for Llama 2), and potentially scale up to 32k with RoPE. Additionally, the models use a new tokenizer with a 128K-token vocabulary, reducing the number of tokens required to encode text by 15%. This vocabulary also explains the bump from 7B to 8B parameters.
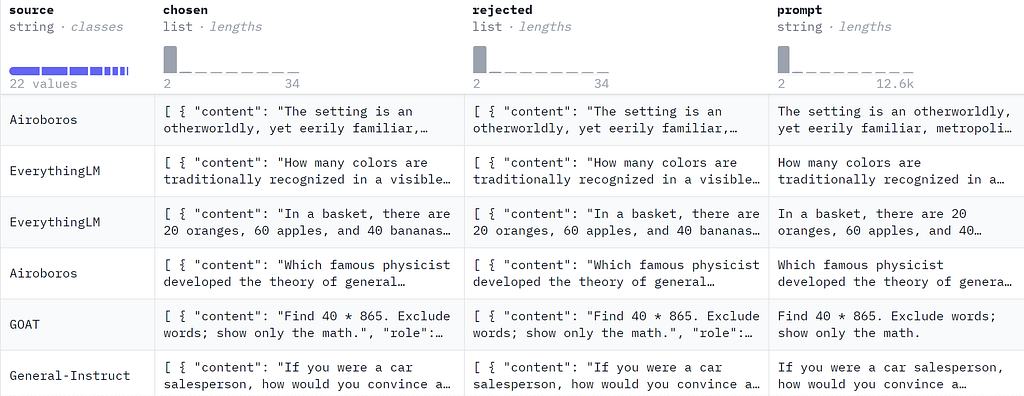
Samples from ORPO-DPO-mix-40k (image by author).
ORPO requires a preference dataset, including a prompt, a chosen answer, and a rejected answer. In this example, we will use mlabonne/orpo-dpo-mix-40k, a combination of the following high-quality DPO datasets:
Thanks to argilla, unalignment, M4-ai, and jondurbin for providing the source datasets.
As per usual, let’s start by installing the required libraries:
pip install -U transformers datasets accelerate peft trl bitsandbytes wandb
Once it’s installed, we can import the necessary libraries and log in to W&B (optional):
import gc
import os
import torch
import wandb
from datasets import load_dataset
from google.colab import userdata
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
)
from trl import ORPOConfig, ORPOTrainer, setup_chat_format
wb_token = userdata.get('wandb')
wandb.login(key=wb_token)
If you have a recent GPU, you should also be able to use the Flash Attention library to replace the default eager attention implementation with a more efficient one.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
attn_implementation = "flash_attention_2"
torch_dtype = torch.bfloat16
else:
attn_implementation = "eager"
torch_dtype = torch.float16
In the following, we will load the Llama 3 8B model in 4-bit precision thanks to bitsandbytes. We then set the LoRA configuration using PEFT for QLoRA. I’m also using the convenient setup_chat_format() function to modify the model and tokenizer for ChatML support. It automatically applies this chat template, adds special tokens, and resizes the model's embedding layer to match the new vocabulary size.
# Model
base_model = "meta-llama/Meta-Llama-3-8B"
new_model = "OrpoLlama-3-8B"
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = prepare_model_for_kbit_training(model)
Now that the model is ready for training, we can take care of the dataset. We load mlabonne/orpo-dpo-mix-40k and use the apply_chat_template() function to convert the "chosen" and "rejected" columns into the ChatML format. Note that I'm only using 1,000 samples and not the entire dataset, as it would take too long to run.
dataset_name = "mlabonne/orpo-dpo-mix-40k"
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=42).select(range(10))
def format_chat_template(row):
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= os.cpu_count(),
)
dataset = dataset.train_test_split(test_size=0.01)
First, we need to set a few hyperparameters:
Finally, we can train the model using the ORPOTrainer, which acts as a wrapper.
orpo_args = ORPOConfig(
learning_rate=8e-6,
beta=0.1,
lr_scheduler_type="linear",
max_length=1024,
max_prompt_length=512,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_8bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
report_to="wandb",
output_dir="./results/",
)
trainer = ORPOTrainer(
model=model,
args=orpo_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(new_model)
Training the model on these 1,000 samples took about 2 hours on an L4 GPU. Let’s check the W&B plots:
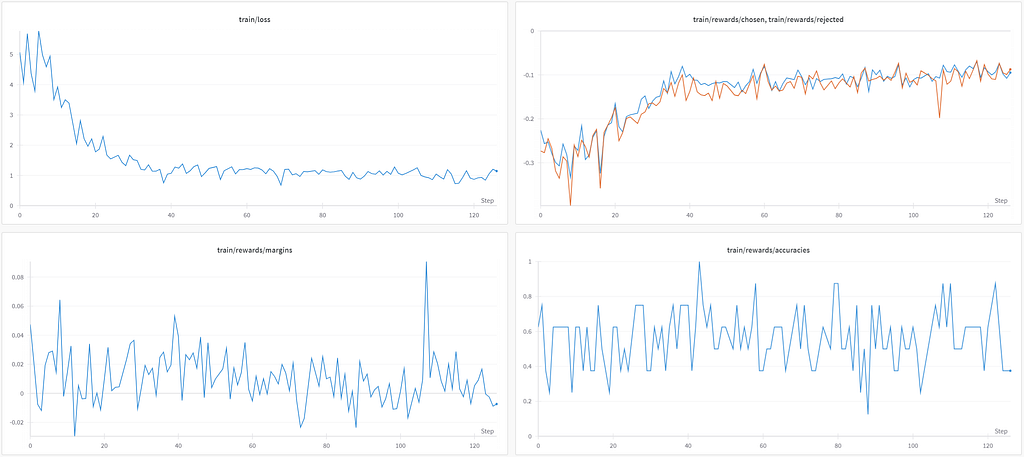
While the loss goes down, the difference between the chosen and rejects answers is not clear: the average margin and accuracy are only slightly above zero and 0.5, respectively.
In the original paper, the authors trained models on the Anthropic/hh-rlhf dataset (161k samples) for 10 epochs, which is a lot longer than our quick run. They also experimented with Llama 3 and kindly shared their logs with me (thanks Jiwoo Hong).
To end this tutorial, let’s merge the QLoRA adapter with the base model and push it to the Hugging Face Hub.
# Flush memory
del trainer, model
gc.collect()
torch.cuda.empty_cache()
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)
model, tokenizer = setup_chat_format(model, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(model, new_model)
model = model.merge_and_unload()
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
Congrats, we finished this quick fine-tune of Llama 3: mlabonne/OrpoLlama-3–8B. You can play with it using this Hugging Face Space (here’s a notebook to make your own). Although the model is undertrained, as highlighted by the W&B curves, I ran some evaluations on Nous’ benchmark suite using LLM AutoEval.
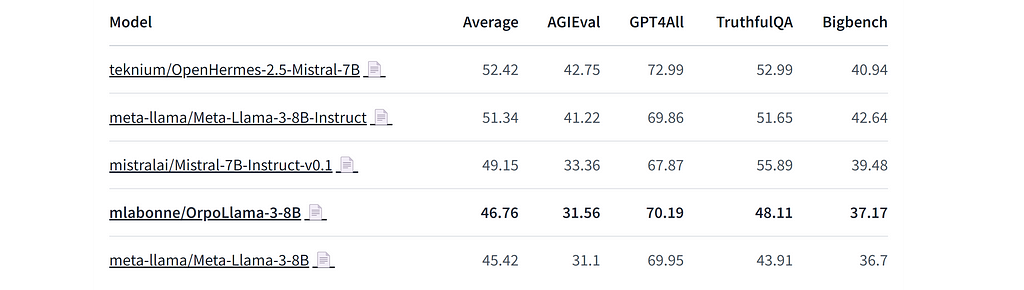
Our ORPO fine-tune is actually pretty decent and improves the base model’s performance on every benchmark. This is encouraging and likely means that a fine-tune on the entire 40k samples would yield great results.
This is an exciting time for the open-source community, with more and more high-quality open-weight models being released. The gap between closed-source and open-weight models is slowly closing, and fine-tuning is an essential tool to get the best performance for your use cases.
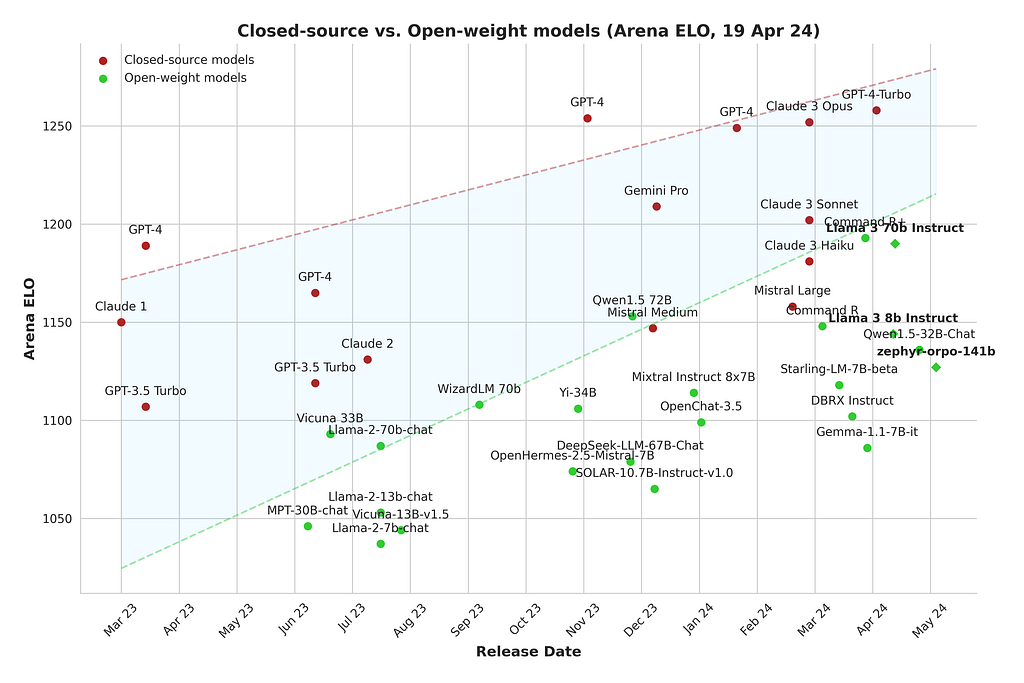
Image by author
Conclusion
In this article, we introduced the ORPO algorithm and explained how it unifies the SFT and preference alignment stages into a single process. Then, we used TRL to fine-tune a Llama 3 8B model on a custom preference dataset. The final model shows encouraging results and highlights ORPO’s potential as a new fine-tuning paradigm.
I hope it was useful, and I recommend running the Colab notebook to fine-tune your own Llama 3 models. In future articles, we will see how to create high-quality datasets — a point that is often overlooked. If you liked this article, please follow me on Hugging Face and Twitter @maximelabonne.
References

Fine-tune Llama 3 with ORPO was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Image generated with DALL-E 3 by author
ORPO is a new exciting fine-tuning technique that combines the traditional supervised fine-tuning and preference alignment stages into a single process. This reduces the computational resources and time required for training. Moreover, empirical results demonstrate that ORPO outperforms other alignment methods on various model sizes and benchmarks.
In this article, we will fine-tune the new Llama 3 8B model using ORPO with the TRL library. The code is available on Google Colab and in the LLM Course on GitHub.
⚖️ ORPO
Instruction tuning and preference alignment are essential techniques for adapting Large Language Models (LLMs) to specific tasks. Traditionally, this involves a multi-stage process: 1/ Supervised Fine-Tuning (SFT) on instructions to adapt the model to the target domain, followed by 2/ preference alignment methods like Reinforcement Learning with Human Feedback (RLHF) or Direct Preference Optimization (DPO) to increase the likelihood of generating preferred responses over rejected ones.
Image by author
However, researchers have identified a limitation in this approach. While SFT effectively adapts the model to the desired domain, it inadvertently increases the probability of generating undesirable answers alongside preferred ones. This is why the preference alignment stage is necessary to widen the gap between the likelihoods of preferred and rejected outputs.
Note how the probability of rejected responses increases during supervised fine-tuning (image from the ORPO paper).
Introduced by Hong and Lee (2024), ORPO offers an elegant solution to this problem by combining instruction tuning and preference alignment into a single, monolithic training process. ORPO modifies the standard language modeling objective, combining the negative log-likelihood loss with an odds ratio (OR) term. This OR loss weakly penalizes rejected responses while strongly rewarding preferred ones, allowing the model to simultaneously learn the target task and align with human preferences.
ORPO has been implemented in the major fine-tuning libraries, like TRL, Axolotl, and LLaMA-Factory. In the next section, we will see how to use with TRL.
? Fine-tuning Llama 3 with ORPO
Llama 3 is the latest family of LLMs developed by Meta. The models were trained on an extensive dataset of 15 trillion tokens (compared to 2T tokens for Llama 2). Two model sizes have been released: a 70 billion parameter model and a smaller 8 billion parameter model. The 70B model has already demonstrated impressive performance, scoring 82 on the MMLU benchmark and 81.7 on the HumanEval benchmark.
Llama 3 models also increased the context length up to 8,192 tokens (4,096 tokens for Llama 2), and potentially scale up to 32k with RoPE. Additionally, the models use a new tokenizer with a 128K-token vocabulary, reducing the number of tokens required to encode text by 15%. This vocabulary also explains the bump from 7B to 8B parameters.
Samples from ORPO-DPO-mix-40k (image by author).
ORPO requires a preference dataset, including a prompt, a chosen answer, and a rejected answer. In this example, we will use mlabonne/orpo-dpo-mix-40k, a combination of the following high-quality DPO datasets:
- argilla/distilabel-capybara-dpo-7k-binarized: highly scored chosen answers >=5 (2,882 samples)
- argilla/distilabel-intel-orca-dpo-pairs: highly scored chosen answers >=9, not in GSM8K (2,299 samples)
- argilla/ultrafeedback-binarized-preferences-cleaned: highly scored chosen answers >=5 (22,799 samples)
- argilla/distilabel-math-preference-dpo: highly scored chosen answers >=9 (2,181 samples)
- unalignment/toxic-dpo-v0.2 (541 samples)
- M4-ai/prm_dpo_pairs_cleaned (7,958 samples)
- jondurbin/truthy-dpo-v0.1 (1,016 samples)
Thanks to argilla, unalignment, M4-ai, and jondurbin for providing the source datasets.
As per usual, let’s start by installing the required libraries:
pip install -U transformers datasets accelerate peft trl bitsandbytes wandb
Once it’s installed, we can import the necessary libraries and log in to W&B (optional):
import gc
import os
import torch
import wandb
from datasets import load_dataset
from google.colab import userdata
from peft import LoraConfig, PeftModel, prepare_model_for_kbit_training
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
)
from trl import ORPOConfig, ORPOTrainer, setup_chat_format
wb_token = userdata.get('wandb')
wandb.login(key=wb_token)
If you have a recent GPU, you should also be able to use the Flash Attention library to replace the default eager attention implementation with a more efficient one.
if torch.cuda.get_device_capability()[0] >= 8:
!pip install -qqq flash-attn
attn_implementation = "flash_attention_2"
torch_dtype = torch.bfloat16
else:
attn_implementation = "eager"
torch_dtype = torch.float16
In the following, we will load the Llama 3 8B model in 4-bit precision thanks to bitsandbytes. We then set the LoRA configuration using PEFT for QLoRA. I’m also using the convenient setup_chat_format() function to modify the model and tokenizer for ChatML support. It automatically applies this chat template, adds special tokens, and resizes the model's embedding layer to match the new vocabulary size.
# Model
base_model = "meta-llama/Meta-Llama-3-8B"
new_model = "OrpoLlama-3-8B"
# QLoRA config
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch_dtype,
bnb_4bit_use_double_quant=True,
)
# LoRA config
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['up_proj', 'down_proj', 'gate_proj', 'k_proj', 'q_proj', 'v_proj', 'o_proj']
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model)
# Load model
model = AutoModelForCausalLM.from_pretrained(
base_model,
quantization_config=bnb_config,
device_map="auto",
attn_implementation=attn_implementation
)
model, tokenizer = setup_chat_format(model, tokenizer)
model = prepare_model_for_kbit_training(model)
Now that the model is ready for training, we can take care of the dataset. We load mlabonne/orpo-dpo-mix-40k and use the apply_chat_template() function to convert the "chosen" and "rejected" columns into the ChatML format. Note that I'm only using 1,000 samples and not the entire dataset, as it would take too long to run.
dataset_name = "mlabonne/orpo-dpo-mix-40k"
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=42).select(range(10))
def format_chat_template(row):
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= os.cpu_count(),
)
dataset = dataset.train_test_split(test_size=0.01)
First, we need to set a few hyperparameters:
- learning_rate: ORPO uses very low learning rates compared to traditional SFT or even DPO. This value of 8e-6 comes from the original paper, and roughly corresponds to an SFT learning rate of 1e-5 and a DPO learning rate of 5e-6. I would recommend increasing it around 1e-6 for a real fine-tune.
- beta: It is the $\lambda$ parameter in the paper, with a default value of 0.1. An appendix from the original paper shows how it's been selected with an ablation study.
- Other parameters, like max_length and batch size are set to use as much VRAM as available (~20 GB in this configuration). Ideally, we would train the model for 3-5 epochs, but we'll stick to 1 here.
Finally, we can train the model using the ORPOTrainer, which acts as a wrapper.
orpo_args = ORPOConfig(
learning_rate=8e-6,
beta=0.1,
lr_scheduler_type="linear",
max_length=1024,
max_prompt_length=512,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_8bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
report_to="wandb",
output_dir="./results/",
)
trainer = ORPOTrainer(
model=model,
args=orpo_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(new_model)
Training the model on these 1,000 samples took about 2 hours on an L4 GPU. Let’s check the W&B plots:
While the loss goes down, the difference between the chosen and rejects answers is not clear: the average margin and accuracy are only slightly above zero and 0.5, respectively.
In the original paper, the authors trained models on the Anthropic/hh-rlhf dataset (161k samples) for 10 epochs, which is a lot longer than our quick run. They also experimented with Llama 3 and kindly shared their logs with me (thanks Jiwoo Hong).
To end this tutorial, let’s merge the QLoRA adapter with the base model and push it to the Hugging Face Hub.
# Flush memory
del trainer, model
gc.collect()
torch.cuda.empty_cache()
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
low_cpu_mem_usage=True,
return_dict=True,
torch_dtype=torch.float16,
device_map="auto",
)
model, tokenizer = setup_chat_format(model, tokenizer)
# Merge adapter with base model
model = PeftModel.from_pretrained(model, new_model)
model = model.merge_and_unload()
model.push_to_hub(new_model, use_temp_dir=False)
tokenizer.push_to_hub(new_model, use_temp_dir=False)
Congrats, we finished this quick fine-tune of Llama 3: mlabonne/OrpoLlama-3–8B. You can play with it using this Hugging Face Space (here’s a notebook to make your own). Although the model is undertrained, as highlighted by the W&B curves, I ran some evaluations on Nous’ benchmark suite using LLM AutoEval.
Our ORPO fine-tune is actually pretty decent and improves the base model’s performance on every benchmark. This is encouraging and likely means that a fine-tune on the entire 40k samples would yield great results.
This is an exciting time for the open-source community, with more and more high-quality open-weight models being released. The gap between closed-source and open-weight models is slowly closing, and fine-tuning is an essential tool to get the best performance for your use cases.
Image by author
Conclusion
In this article, we introduced the ORPO algorithm and explained how it unifies the SFT and preference alignment stages into a single process. Then, we used TRL to fine-tune a Llama 3 8B model on a custom preference dataset. The final model shows encouraging results and highlights ORPO’s potential as a new fine-tuning paradigm.
I hope it was useful, and I recommend running the Colab notebook to fine-tune your own Llama 3 models. In future articles, we will see how to create high-quality datasets — a point that is often overlooked. If you liked this article, please follow me on Hugging Face and Twitter @maximelabonne.
References
- J. Hong, N. Lee, and J. Thorne, ORPO: Monolithic Preference Optimization without Reference Model. 2024.
- L. von Werra et al., TRL: Transformer Reinforcement Learning. GitHub, 2020. [Online]. Available: https://github.com/huggingface/trl
- Bartolome, A., Martin, G., & Vila, D. (2023). Notus. In GitHub Repository. GitHub. https://github.com/argilla-io/notus
- AI at Meta, Introducing Meta Llama 3, 2024.
Fine-tune Llama 3 with ORPO was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.