An Exploration with Potential Solutions

Llama: Photo by Liudmila Shuvalova
The launch of Llama 2 by Meta has ignited excitement within the community, marking the dawn of an era for well performed large language models that were previously only accessible through company-specific APIs.
However, it is important to acknowledge some imperfections inherent in these models. Among them, the stop generation issue stands out prominently. My personal experiences have shown that these models often struggle to determine the appropriate ‘stop’ point, leaving them uncertain about when to end a text generation.
In this blog post, I will delve into the issue of stop generation failures in the smallest Llama 2 model, the Llama 2–7b model, and discuss several potential remedies. The implementation in the coming sections can be found in this GoogleGolab notebook with the runtime type T4.
Stop generation failure
In this section, we will harness the power of a Llama 2–7b model using a T4 GPU equipped with ample high RAM resources in Google Colab (2.21 credits/hour). It is essential to bear in mind that the T4 GPU comes with a VRAM capacity of 16 GB, precisely enough to house Llama 2–7b’s weights (7b × 2 bytes = 14 GB in FP16).
To efficiently manage VRAM usage, we will employ a technique called quantization. Quantization is an approach that focuses on minimizing both computational and memory requirements during inference by representing weights and activations using low-precision data types.
Let’s now delve into the following code snippet. Here, we’ll demonstrate how to load the “meta-llama/Llama-2–7b-chat-hf” model with a Bite and Byte configuration and set up a text generation pipeline based on this loaded model.
# bit and byte configuration
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True, # 4-bit quantization
bnb_4bit_quant_type='nf4', # Normalized float 4
bnb_4bit_use_double_quant=True, # Second quantization after the first
bnb_4bit_compute_dtype=bfloat16 # Computation type
)
model_id= "meta-llama/Llama-2-7b-chat-hf"
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
# Llama 2 Tokenizer
tokenizer =transformers.AutoTokenizer.from_pretrained(model_id)
# Llama 2 Model
model = transformers.AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
quantization_config=bnb_config,
device_map='auto',
)
model.eval()
# Difine pipeline
transformers.pipeline(model=model,
tokenizer=tokenizer,
return_full_text=True, # langchain expects the full text
task='text-generation',
# we pass model parameters here too
max_new_tokens=500, # max number of tokens to generate in the output
temperature=0.1,
)
This configuration enables us to generate text for a given prompt in under one minute. Let’s put it to the test with a straightforward question: “What can I do in Paris?” Below, you’ll find the answer (Please keep in mind that your results might vary due to temperature settings).
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. everybody's dream destination. Here are some of the top things to do in Paris:
1. Visit iconic landmarks: The Eiffel Tower, the Louvre Museum, Notre-Dame Cathedral, Arc de Triomphe, and the Champs-Élysées are must-visit attractions.
2. Explore museums and art galleries: The Louvre, Musée d'Orsay, and Centre Pompidou are some of the world's most famous museums.
3. Take a river cruise: A Seine River cruise is a great way to see the city's landmarks and bridges while learning about its history and culture.
4. Discover the city's neighborhoods: From the fashionable Champs-Élysées to the charming Montmartre, each Parisian neighborhood has its own unique character and charm.
# I skipped some text here because of the limt of space#
Of course, there are countless
It’s apparent that the model struggles to produce a satisfactory response; it appears to have difficulty knowing when to conclude its output. Upon tokenizing the generated text, it becomes evident that the final token is not a 2, which represents the eos (end-of-sequence) token in the model’s tokenizer.
Upon closer examination of the token scores (probabilities) provided by the model, I noticed that the token_id 2 (eso_token_id) has a score of “-inf.” This implies that it has no possibility of being generated.
Attempts of problem resolution
In this section, we will explore several potential solutions aimed at addressing the issue at hand. It’s essential to keep in mind that the solutions discussed herein represent proactive efforts, but they may not always provide resolutions to the problems in question.
Logits Processor
A language model like Llama 2 processes a sequence of text tokens as input and produces a sequence of conditional probabilities for the next token, based on the context from the initial token to the current one. In light of this, it’s worth considering manual adjustments to these probabilities as we approach the maximum token limit, with the goal of increasing the likelihood of encountering the eos token. We do it by defining our customized LogitsProcessor called “EosTokenRewardLogitsProcessor” swith two initial inputs eos_token_id and max_length where the latter represents the max length at which the model should generate a eos token:
class EosTokenRewardLogitsProcessor(LogitsProcessor):
def __init__(self, eos_token_id: int, max_length: int):
if not isinstance(eos_token_id, int) or eos_token_id < 0:
raise ValueError(f"`eos_token_id` has to be a positive integer, but is {eos_token_id}")
if not isinstance(max_length, int) or max_length < 1:
raise ValueError(f"`max_length` has to be a integer bigger than 1, but is {max_length}")
self.eos_token_id = eos_token_id
self.max_length=max_length
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
cur_len = input_ids.shape[-1]
# start to increese the reward of the eos_tokekn from 80% max length progressively on length
for cur_len in (max(0,int(self.max_length*0.8)), self.max_length ):
ratio = cur_len/self.max_length
num_tokens = scores.shape[1] # size of vocab
scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]] =\
scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]]*ratio*10*torch.exp(-torch.sign(scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]]))
scores[:, self.eos_token_id] = 1e2*ratio
return scores
In the “__call__” method of the class, we enhance the probability (score) of the eos_token based on the sequence’s length. When the length approaches 80% of the specified maximum length, we set the eos_token_id’s score to 1e2 multiplied by a length ratio and adjust the scores of other tokens downward accordingly.
Now declare the logits processor in the pipeline’s definition:
pipe = transformers.pipeline(model=model,
tokenizer=tokenizer,
return_full_text=True, # langchain expects the full text
task='text-generation',
# we pass model parameters here too
#stopping_criteria=stopping_criteria, # without this model rambles during chat
logits_processor=logits_process_list,
max_new_tokens=500, # max number of tokens to generate in the output
temperature=0.1,
)
Run the pipeline again with same prompt “What Can I do in Paris” and we get:
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere.
It works well! We have got a complete answer even if it might look short.
Fine-Tuning
If the model fails to generate the EOS token, why not consider instructing it to do so? The concept of enhancing the model’s performance by fine-tuning it with a dataset that includes answers concluding with the EOS token is certainly a promising avenue to explore.
In this section, I will use shamelessly the groundwork laid out in this blog post that employed a parameter-efficient fine-tuning (PEFT) method, such as QLoRA, to fine-tune the Llama 2–7b model. Much like its predecessor, LoRA, QLoRA utilizes a small set of trainable parameters (adapters) while keeping the core model parameters unchanged. It introduces two noteworthy innovations: 4-bit NormalFloat (NF4), an information-theoretically optimal data quantization method for normal data, and Double Quantization. For a more in-depth understanding, please consult the original paper, should you have any further interest in this topic.
Let us train the model on a dataset called ‘timdettmers/openassistant-guanaco’ where you can find on hugging face database. This dataset has the following format where the human and assistant’s conversation is separated by “###”.

Image author: “timdettmers/openassistant-guanaco’/ dataset
Before training, we have to transform the data into the Llama 2 prompt template:
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>> {user_message_1} [/INST]
I will skip the detail of the dataset transformation here. Now let us take a look of the main part of training given by the following code:
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer.train()
In the context of a dataset comprising instructions and responses, our approach involved the use of a Supervised Trainer (SFTainer) in conjunction with the QLoRA method to fine-tune the weight parameters within the Language Model (LLM). Our primary objective was to minimize the discrepancies between the generated answers and the ground-truth responses, which served as our reference labels.
A significant parameter within this configuration is “lora r,” representing a relatively small value pertaining to both the second and first dimensions of the pairs of rank-decomposition weight matrices. Training occurred exclusively on these two matrices, complementing the existing weights.
We train the model for 250 steps with training loss given in the plot below:
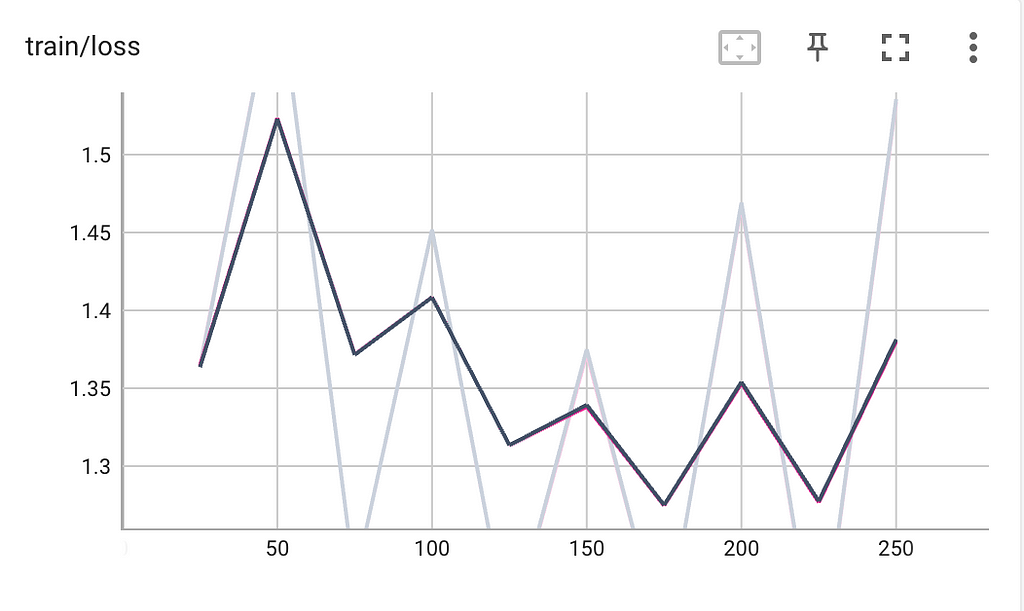
Image by author: training loss of llama 2 for 250 steps
Now let us run the pipeline with the fine-tuned model. This time, we get:
Paris, the capital of France, is known for its stunning architecture, rich history, and cultural attractions. Here are some popular things to do in Paris:
1. Visit iconic landmarks: The Eiffel Tower, Arc de Triomphe, Notre-Dame Cathedral, and the Louvre Museum are some of the most famous landmarks in Paris.
2. Explore museums and art galleries: Paris is home to many world-class museums and art galleries, including the Louvre, the Musée d'Orsay, and the Pompidou Center.
3. Enjoy the city's gardens and parks: Paris has several beautiful gardens and parks, including the Luxembourg Gardens, the Tuileries Garden, and the Champ de Mars.
4. Take a river cruise: A river cruise along the Seine is a great way to see the city's sights and learn about its history.
5. Shop on the Champs-Élysées: The famous avenue is lined with high-end boutiques, department stores, and cafes.
6. Attend a cabaret show: The Moulin Rouge is a famous cabaret that offers a lively and entertaining show.
7. Visit Montmartre: The charming neighborhood of Montmartre is known for its artistic vibe, street performers, and stunning views of the city.
8. Take a food tour: Paris is known for its culinary delights, and a food tour is a great way to sample the city's famous cuisine.
9. Visit the Palace of Versailles: The Palace of Versailles is a beautiful royal palace located just outside of Paris.
10. Attend a fashion show: Paris is the fashion capital of the world, and attending a fashion show is a great way to see the latest trends and styles.
These are just a few of the many things to do in Paris. The city has something for everyone, from history and culture to food and entertainment.
This is rather a beautiful answer!
Bonus: give a different prompt
Ultimately, there’s a straightforward yet effective trick at our disposal, especially when the model’s verbosity is not a concern. We can explicitly mention in the prompt that we require a concise response. For instance, when I ask the model, “What can I do in Paris? Respond in five sentences or fewer,” it provides:
Sure! Here are five things you can do in Paris: 1. Visit the Eiffel Tower, a iconic landmark that offers stunning views of the city. 2. Explore the Louvre Museum and see famous artworks like the Mona Lisa. 3. Stroll along the Seine River and enjoy the city's picturesque bridges and charming streets. 4. Visit the Notre-Dame Cathedral, a beautiful and historic church. 5. Enjoy a delicious French meal at a traditional bistro or restaurant.
It is a short but clean and complete answer.
Stopping Criteria: an unsucessful attempt
For those who are interested, Hugging Face has introduced another API called StoppingCriteria, intended for establishing specific conditions that compel a sequence to halt. However, when it comes to defining a customized criterion that stops the model upon encountering certain tokens (e.g., ‘\n’), it may not provide a comprehensive solution to the issue. As an example, I attempted to create a StopOnTokens class:
# define custom stopping criteria object
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
for stop_ids in stop_token_ids:
if torch.eq(input_ids[0][-len(stop_ids):], stop_ids).all():
return True
return False
stopping_criteria = StoppingCriteriaList([StopOnTokens()])
However, the model still fails to give a complete answer.
Conclusion
In this blog post, I highlighted the issue of generation stop in Llama 2 and introduced several interim solutions. Again, I skip lots of details of implementations and I recommend you to have a deeper look of my notebook.

Image by Jose Aragones
However, it’s important to note that these solutions are meant to enhance the user-friendliness of the responses in the short term, but we are eagerly anticipating a permanent fix to address this matter.

Challenges in Stop Generation within Llama 2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Llama: Photo by Liudmila Shuvalova
The launch of Llama 2 by Meta has ignited excitement within the community, marking the dawn of an era for well performed large language models that were previously only accessible through company-specific APIs.
However, it is important to acknowledge some imperfections inherent in these models. Among them, the stop generation issue stands out prominently. My personal experiences have shown that these models often struggle to determine the appropriate ‘stop’ point, leaving them uncertain about when to end a text generation.
In this blog post, I will delve into the issue of stop generation failures in the smallest Llama 2 model, the Llama 2–7b model, and discuss several potential remedies. The implementation in the coming sections can be found in this GoogleGolab notebook with the runtime type T4.
Stop generation failure
In this section, we will harness the power of a Llama 2–7b model using a T4 GPU equipped with ample high RAM resources in Google Colab (2.21 credits/hour). It is essential to bear in mind that the T4 GPU comes with a VRAM capacity of 16 GB, precisely enough to house Llama 2–7b’s weights (7b × 2 bytes = 14 GB in FP16).
To efficiently manage VRAM usage, we will employ a technique called quantization. Quantization is an approach that focuses on minimizing both computational and memory requirements during inference by representing weights and activations using low-precision data types.
Let’s now delve into the following code snippet. Here, we’ll demonstrate how to load the “meta-llama/Llama-2–7b-chat-hf” model with a Bite and Byte configuration and set up a text generation pipeline based on this loaded model.
# bit and byte configuration
bnb_config = transformers.BitsAndBytesConfig(
load_in_4bit=True, # 4-bit quantization
bnb_4bit_quant_type='nf4', # Normalized float 4
bnb_4bit_use_double_quant=True, # Second quantization after the first
bnb_4bit_compute_dtype=bfloat16 # Computation type
)
model_id= "meta-llama/Llama-2-7b-chat-hf"
device = f'cuda:{cuda.current_device()}' if cuda.is_available() else 'cpu'
# Llama 2 Tokenizer
tokenizer =transformers.AutoTokenizer.from_pretrained(model_id)
# Llama 2 Model
model = transformers.AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
quantization_config=bnb_config,
device_map='auto',
)
model.eval()
# Difine pipeline
transformers.pipeline(model=model,
tokenizer=tokenizer,
return_full_text=True, # langchain expects the full text
task='text-generation',
# we pass model parameters here too
max_new_tokens=500, # max number of tokens to generate in the output
temperature=0.1,
)
This configuration enables us to generate text for a given prompt in under one minute. Let’s put it to the test with a straightforward question: “What can I do in Paris?” Below, you’ll find the answer (Please keep in mind that your results might vary due to temperature settings).
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. everybody's dream destination. Here are some of the top things to do in Paris:
1. Visit iconic landmarks: The Eiffel Tower, the Louvre Museum, Notre-Dame Cathedral, Arc de Triomphe, and the Champs-Élysées are must-visit attractions.
2. Explore museums and art galleries: The Louvre, Musée d'Orsay, and Centre Pompidou are some of the world's most famous museums.
3. Take a river cruise: A Seine River cruise is a great way to see the city's landmarks and bridges while learning about its history and culture.
4. Discover the city's neighborhoods: From the fashionable Champs-Élysées to the charming Montmartre, each Parisian neighborhood has its own unique character and charm.
# I skipped some text here because of the limt of space#
Of course, there are countless
It’s apparent that the model struggles to produce a satisfactory response; it appears to have difficulty knowing when to conclude its output. Upon tokenizing the generated text, it becomes evident that the final token is not a 2, which represents the eos (end-of-sequence) token in the model’s tokenizer.
Upon closer examination of the token scores (probabilities) provided by the model, I noticed that the token_id 2 (eso_token_id) has a score of “-inf.” This implies that it has no possibility of being generated.
Attempts of problem resolution
In this section, we will explore several potential solutions aimed at addressing the issue at hand. It’s essential to keep in mind that the solutions discussed herein represent proactive efforts, but they may not always provide resolutions to the problems in question.
Logits Processor
A language model like Llama 2 processes a sequence of text tokens as input and produces a sequence of conditional probabilities for the next token, based on the context from the initial token to the current one. In light of this, it’s worth considering manual adjustments to these probabilities as we approach the maximum token limit, with the goal of increasing the likelihood of encountering the eos token. We do it by defining our customized LogitsProcessor called “EosTokenRewardLogitsProcessor” swith two initial inputs eos_token_id and max_length where the latter represents the max length at which the model should generate a eos token:
class EosTokenRewardLogitsProcessor(LogitsProcessor):
def __init__(self, eos_token_id: int, max_length: int):
if not isinstance(eos_token_id, int) or eos_token_id < 0:
raise ValueError(f"`eos_token_id` has to be a positive integer, but is {eos_token_id}")
if not isinstance(max_length, int) or max_length < 1:
raise ValueError(f"`max_length` has to be a integer bigger than 1, but is {max_length}")
self.eos_token_id = eos_token_id
self.max_length=max_length
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
cur_len = input_ids.shape[-1]
# start to increese the reward of the eos_tokekn from 80% max length progressively on length
for cur_len in (max(0,int(self.max_length*0.8)), self.max_length ):
ratio = cur_len/self.max_length
num_tokens = scores.shape[1] # size of vocab
scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]] =\
scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]]*ratio*10*torch.exp(-torch.sign(scores[:, [i for i in range(num_tokens) if i != self.eos_token_id]]))
scores[:, self.eos_token_id] = 1e2*ratio
return scores
In the “__call__” method of the class, we enhance the probability (score) of the eos_token based on the sequence’s length. When the length approaches 80% of the specified maximum length, we set the eos_token_id’s score to 1e2 multiplied by a length ratio and adjust the scores of other tokens downward accordingly.
Now declare the logits processor in the pipeline’s definition:
pipe = transformers.pipeline(model=model,
tokenizer=tokenizer,
return_full_text=True, # langchain expects the full text
task='text-generation',
# we pass model parameters here too
#stopping_criteria=stopping_criteria, # without this model rambles during chat
logits_processor=logits_process_list,
max_new_tokens=500, # max number of tokens to generate in the output
temperature=0.1,
)
Run the pipeline again with same prompt “What Can I do in Paris” and we get:
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere.
It works well! We have got a complete answer even if it might look short.
Fine-Tuning
If the model fails to generate the EOS token, why not consider instructing it to do so? The concept of enhancing the model’s performance by fine-tuning it with a dataset that includes answers concluding with the EOS token is certainly a promising avenue to explore.
In this section, I will use shamelessly the groundwork laid out in this blog post that employed a parameter-efficient fine-tuning (PEFT) method, such as QLoRA, to fine-tune the Llama 2–7b model. Much like its predecessor, LoRA, QLoRA utilizes a small set of trainable parameters (adapters) while keeping the core model parameters unchanged. It introduces two noteworthy innovations: 4-bit NormalFloat (NF4), an information-theoretically optimal data quantization method for normal data, and Double Quantization. For a more in-depth understanding, please consult the original paper, should you have any further interest in this topic.
Let us train the model on a dataset called ‘timdettmers/openassistant-guanaco’ where you can find on hugging face database. This dataset has the following format where the human and assistant’s conversation is separated by “###”.
Image author: “timdettmers/openassistant-guanaco’/ dataset
Before training, we have to transform the data into the Llama 2 prompt template:
<s>[INST] <<SYS>>
{your_system_message}
<</SYS>> {user_message_1} [/INST]
I will skip the detail of the dataset transformation here. Now let us take a look of the main part of training given by the following code:
# Load LoRA configuration
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
)
# Set supervised fine-tuning parameters
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer.train()
In the context of a dataset comprising instructions and responses, our approach involved the use of a Supervised Trainer (SFTainer) in conjunction with the QLoRA method to fine-tune the weight parameters within the Language Model (LLM). Our primary objective was to minimize the discrepancies between the generated answers and the ground-truth responses, which served as our reference labels.
A significant parameter within this configuration is “lora r,” representing a relatively small value pertaining to both the second and first dimensions of the pairs of rank-decomposition weight matrices. Training occurred exclusively on these two matrices, complementing the existing weights.
We train the model for 250 steps with training loss given in the plot below:
Image by author: training loss of llama 2 for 250 steps
Now let us run the pipeline with the fine-tuned model. This time, we get:
Paris, the capital of France, is known for its stunning architecture, rich history, and cultural attractions. Here are some popular things to do in Paris:
1. Visit iconic landmarks: The Eiffel Tower, Arc de Triomphe, Notre-Dame Cathedral, and the Louvre Museum are some of the most famous landmarks in Paris.
2. Explore museums and art galleries: Paris is home to many world-class museums and art galleries, including the Louvre, the Musée d'Orsay, and the Pompidou Center.
3. Enjoy the city's gardens and parks: Paris has several beautiful gardens and parks, including the Luxembourg Gardens, the Tuileries Garden, and the Champ de Mars.
4. Take a river cruise: A river cruise along the Seine is a great way to see the city's sights and learn about its history.
5. Shop on the Champs-Élysées: The famous avenue is lined with high-end boutiques, department stores, and cafes.
6. Attend a cabaret show: The Moulin Rouge is a famous cabaret that offers a lively and entertaining show.
7. Visit Montmartre: The charming neighborhood of Montmartre is known for its artistic vibe, street performers, and stunning views of the city.
8. Take a food tour: Paris is known for its culinary delights, and a food tour is a great way to sample the city's famous cuisine.
9. Visit the Palace of Versailles: The Palace of Versailles is a beautiful royal palace located just outside of Paris.
10. Attend a fashion show: Paris is the fashion capital of the world, and attending a fashion show is a great way to see the latest trends and styles.
These are just a few of the many things to do in Paris. The city has something for everyone, from history and culture to food and entertainment.
This is rather a beautiful answer!
Bonus: give a different prompt
Ultimately, there’s a straightforward yet effective trick at our disposal, especially when the model’s verbosity is not a concern. We can explicitly mention in the prompt that we require a concise response. For instance, when I ask the model, “What can I do in Paris? Respond in five sentences or fewer,” it provides:
Sure! Here are five things you can do in Paris: 1. Visit the Eiffel Tower, a iconic landmark that offers stunning views of the city. 2. Explore the Louvre Museum and see famous artworks like the Mona Lisa. 3. Stroll along the Seine River and enjoy the city's picturesque bridges and charming streets. 4. Visit the Notre-Dame Cathedral, a beautiful and historic church. 5. Enjoy a delicious French meal at a traditional bistro or restaurant.
It is a short but clean and complete answer.
Stopping Criteria: an unsucessful attempt
For those who are interested, Hugging Face has introduced another API called StoppingCriteria, intended for establishing specific conditions that compel a sequence to halt. However, when it comes to defining a customized criterion that stops the model upon encountering certain tokens (e.g., ‘\n’), it may not provide a comprehensive solution to the issue. As an example, I attempted to create a StopOnTokens class:
# define custom stopping criteria object
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
for stop_ids in stop_token_ids:
if torch.eq(input_ids[0][-len(stop_ids):], stop_ids).all():
return True
return False
stopping_criteria = StoppingCriteriaList([StopOnTokens()])
However, the model still fails to give a complete answer.
Conclusion
In this blog post, I highlighted the issue of generation stop in Llama 2 and introduced several interim solutions. Again, I skip lots of details of implementations and I recommend you to have a deeper look of my notebook.
Image by Jose Aragones
However, it’s important to note that these solutions are meant to enhance the user-friendliness of the responses in the short term, but we are eagerly anticipating a permanent fix to address this matter.
Challenges in Stop Generation within Llama 2 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.