Explore the intricacies of the attention mechanism responsible for fueling the transformers
Attention! Attention!
Because ‘Attention is All You Need’.
No, I am not saying that, the Transformer is.

Image by author (Robtimus Prime seeking attention. As per my son, bright rainbow colors work better for attention and hence the color scheme.)
As of today, the world has been swept over by the power of transformers. Not the likes of ‘Robtimus Prime’ but the ones that constitute neural networks. And that power is because of the concept of ‘attention’. So, what does attention in the context of transformers really mean? Let’s try to find out some answers here:
First and foremost:
What are transformers?
Transformers are neural networks that specialize in learning context from the data. Quite similar to us trying to find the meaning of ‘attention and context’ in terms of transformers.
How do transformers learn context from the data?
By using the attention mechanism.
What is the attention mechanism?
The attention mechanism helps the model scan all parts of a sequence at each step and determine which elements need to be focused on. The attention mechanism was proposed as an alternative to the ‘strict/hard’ solution of fixed-length vectors in the encoder-decoder architecture and provide a ‘soft’ solution focusing only on the relevant parts.
What is self-attention?
The attention mechanism worked to improve the performance of Recurrence Neural Networks (RNNs), with the effect seeping into Convolutional Neural Networks (CNNs). However, with the introduction of the transformer architecture in the year 2017, the need for RNNs and CNNs was quietly obliterated. And the central reason for it was the self-attention mechanism.
The self-attention mechanism was special in the sense that it was built to inculcate the context of the input sequence in order to enhance the attention mechanism. This idea became transformational as it was able to capture the complex nuances of a language.
There are many variations of how self-attention is performed. But the scaled dot-product mechanism has been one of the most popular ones. This was the one introduced in the original transformer architecture paper in 2017 — “Attention is All You Need”.
Where and how does self-attention feature in transformers?
I like to see the transformer architecture as a combination of two shells — the outer shell and the inner shell.
So, without further delay, let us dive into the details behind the self-attention mechanism and unravel the workings behind it. The Query-Key module and the SoftMax function play a crucial role in this technique.
This discussion is based on Prof. Tom Yeh’s wonderful AI by Hand Series on Self-Attention. (All the images below, unless otherwise noted, are by Prof. Tom Yeh from the above-mentioned LinkedIn post, which I have edited with his permission.)
So here we go:
Self-Attention
To build some context here, here is a pointer to how we process the ‘Attention-Weighting’ in the transformer outer shell.
Attention weight matrix (A)
The attention weight matrix A is obtained by feeding the input features into the Query-Key (QK) module. This matrix tries to find the most relevant parts in the input sequence. Self-Attention comes into play while creating the Attention weight matrix A using the QK-module.
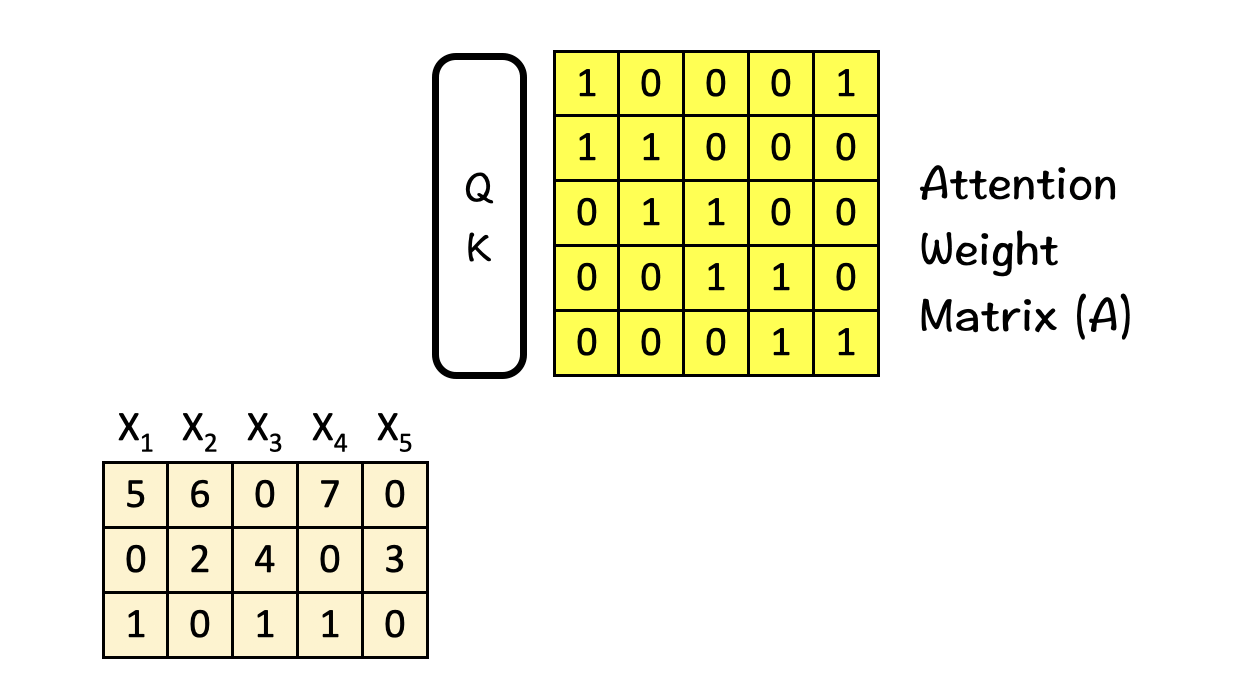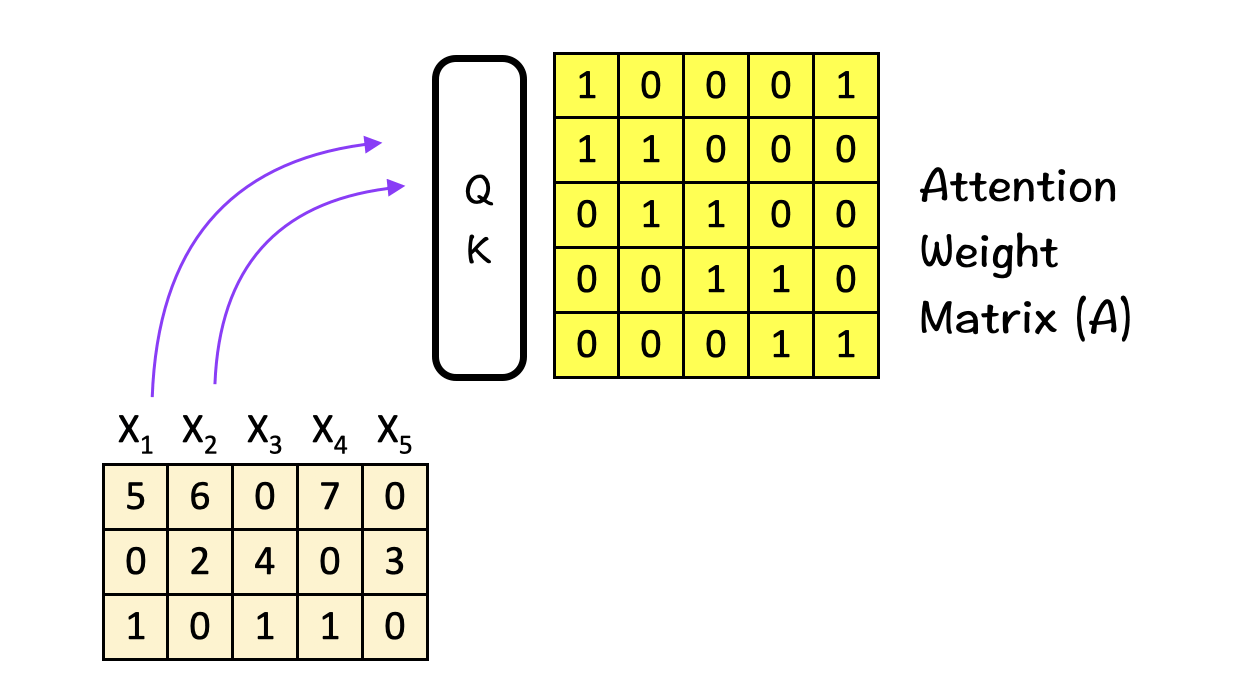
How does the QK-module work?
Let us look at The different components of Self-Attention: Query (Q), Key (K) and Value (V).
I love using the spotlight analogy here as it helps me visualize the model throwing light on each element of the sequence and trying to find the most relevant parts. Taking this analogy a bit further, let us use it to understand the different components of Self-Attention.
Imagine a big stage getting ready for the world’s largest Macbeth production. The audience outside is teeming with excitement.
And with that is created one of the world’s finest performances, that remains etched in the minds of the awestruck audience for the years to come.
Now that we have witnessed the role of Q, K, V in the fantastical world of performing arts, let’s return to planet matrices and learn the mathematical nitty-gritty behind the QK-module. This is the roadmap that we will follow:
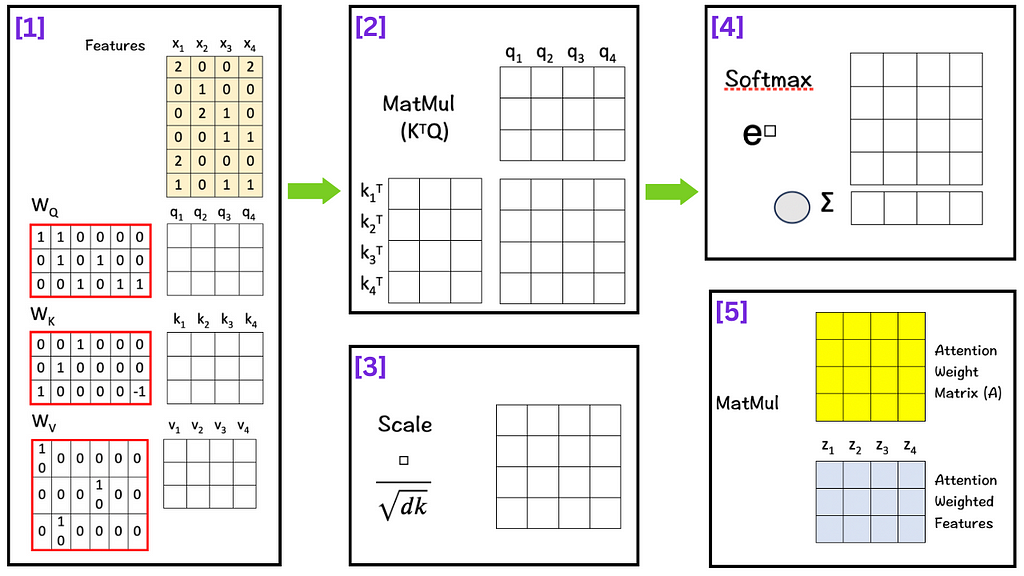
Roadmap for the Self-Attention mechanism
And so the process begins.
We are given:
A set of 4-feature vectors (Dimension 6)
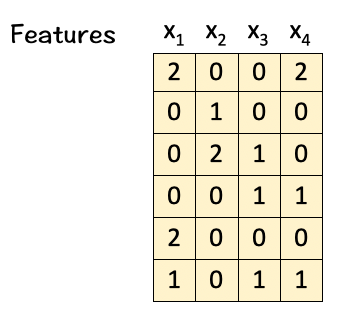
Our goal :
Transform the given features into Attention Weighted Features.
[1] Create Query, Key, Value Matrices
To do so, we multiply the features with linear transformation matrices W_Q, W_K, and W_V, to obtain query vectors (q1,q2,q3,q4), key vectors (k1,k2,k3,k4), and value vectors (v1,v2,v3,v4) respectively as shown below:
To get Q, multiply W_Q with X:
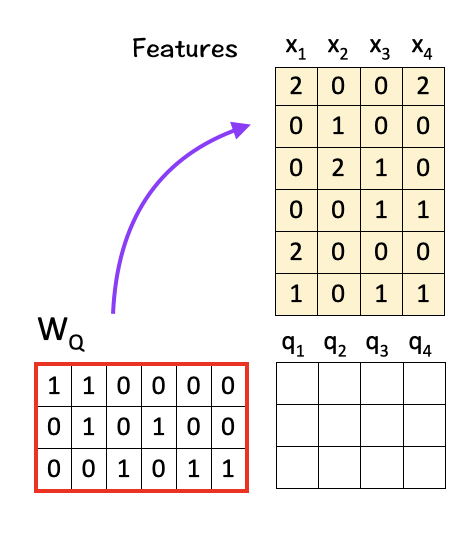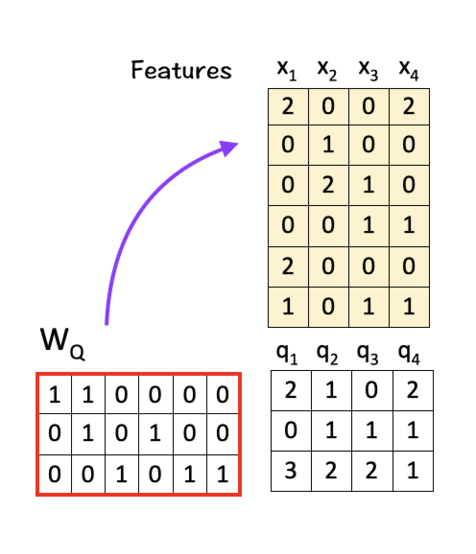
To get K, multiply W_K with X:
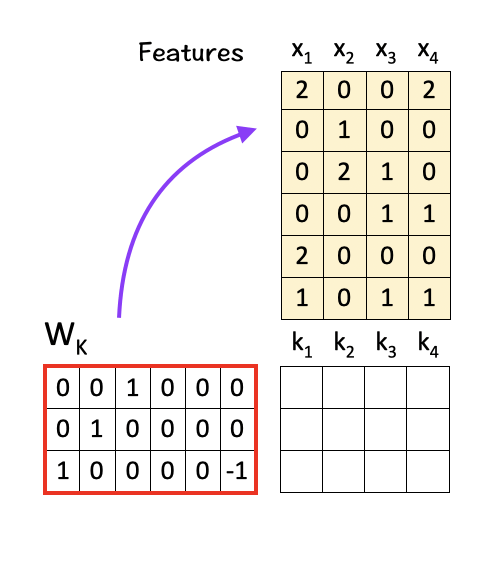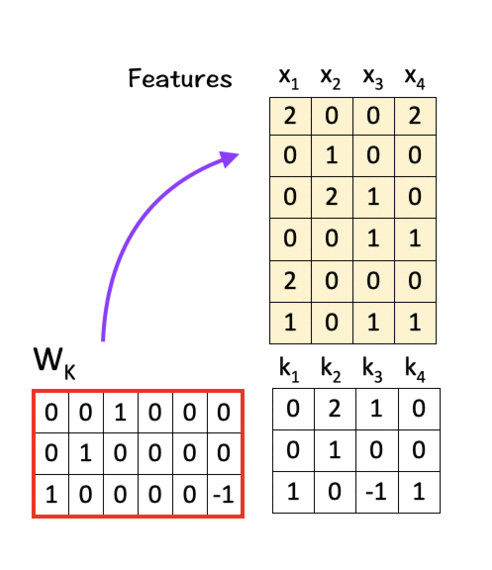
Similarly, to get V, multiply W_V with X.
To be noted:
[2] Matrix Multiplication
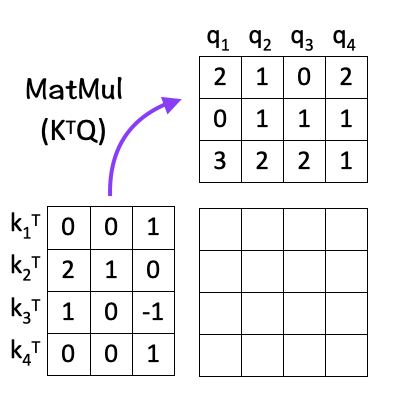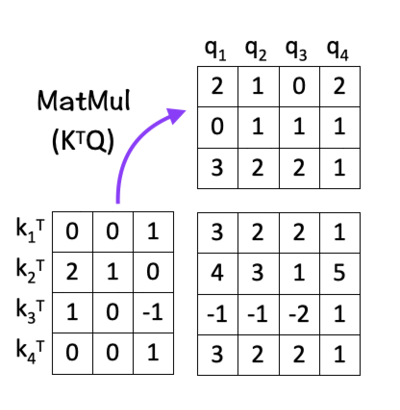
The next step is to multiply the transpose of K with Q i.e. K^T . Q.
The idea here is to calculate the dot product between every pair of query and key vectors. Calculating the dot product gives us an estimate of the matching score between every “key-query” pair, by using the idea of Cosine Similarity between the two vectors. This is the ‘dot-product’ part of the scaled dot-product attention.
[3] Scale
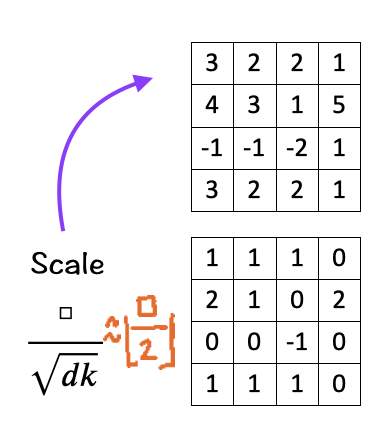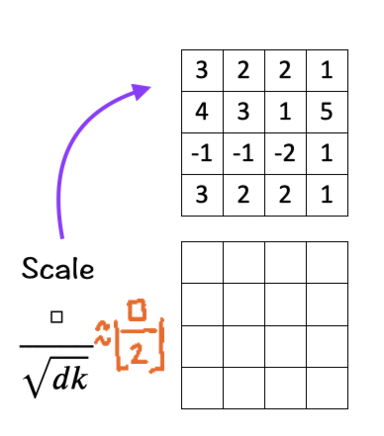
The next step is to scale/normalize each element by the square root of the dimension ‘d_k’. In our case the number is 3. Scaling down helps to keep the impact of the dimension on the matching score in check.
How does it do so? As per the original Transformer paper and going back to Probability 101, if two independent and identically distributed (i.i.d) variables q and k with mean 0 and variance 1 with dimension d are multiplied, the result is a new random variable with mean remaining 0 but variance changing to d_k.
Now imagine how the matching score would look if our dimension is increased to 32, 64, 128 or even 4960 for that matter. The larger dimension would make the variance higher and push the values into regions ‘unknown’.
To keep the calculation simple here, since sqrt [3] is approximately 1.73205, we replace it with [ floor(□/2) ].
This the ‘scaled’ part of the scaled dot-product attention.
[4] Softmax
There are three parts to this step:
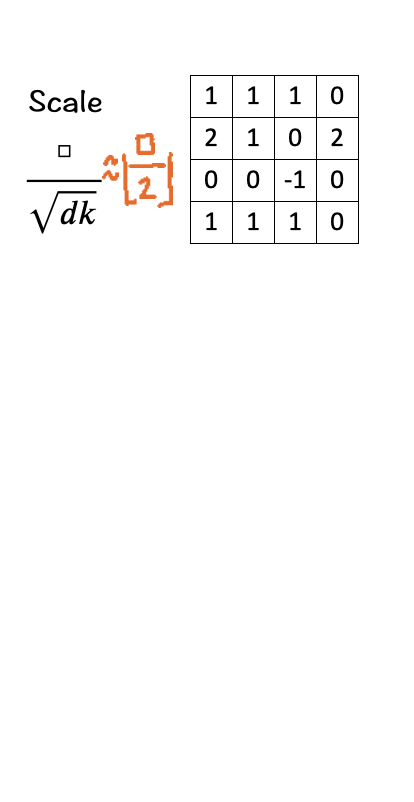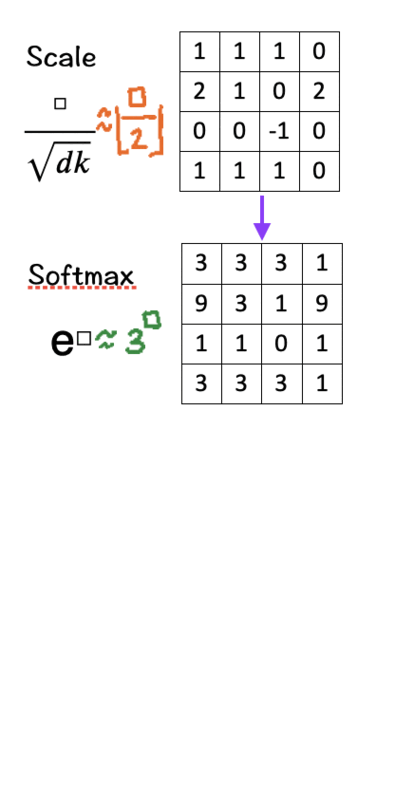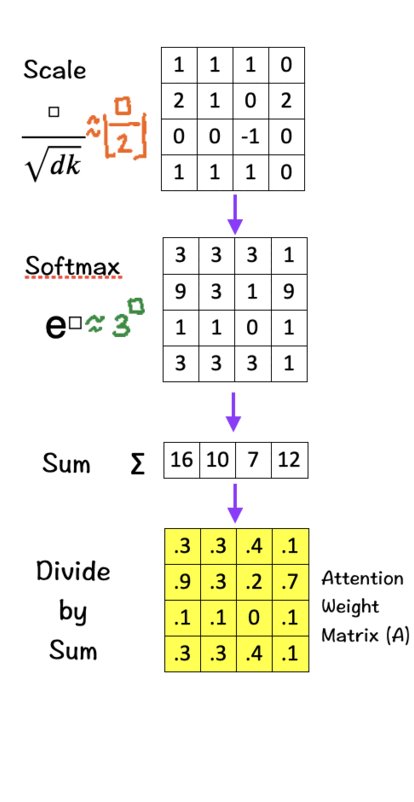
This Attention Weight Matrix is what we had obtained after passing our feature matrix through the QK-module in Step 2 in the Transformers section.
The Softmax step is important as it assigns probabilities to the score obtained in the previous steps and thus helps the model decide how much importance (higher/lower attention weights) needs to be given to each word given the current query. As is to be expected, higher attention weights signify greater relevance allowing the model to capture dependencies more accurately.
Once again, the scaling in the previous step becomes important here. Without the scaling, the values of the resultant matrix gets pushed out into regions that are not processed well by the Softmax function and may result in vanishing gradients.
[5] Matrix Multiplication
Finally we multiply the value vectors (Vs) with the Attention Weight Matrix (A). These value vectors are important as they contain the information associated with each word in the sequence.
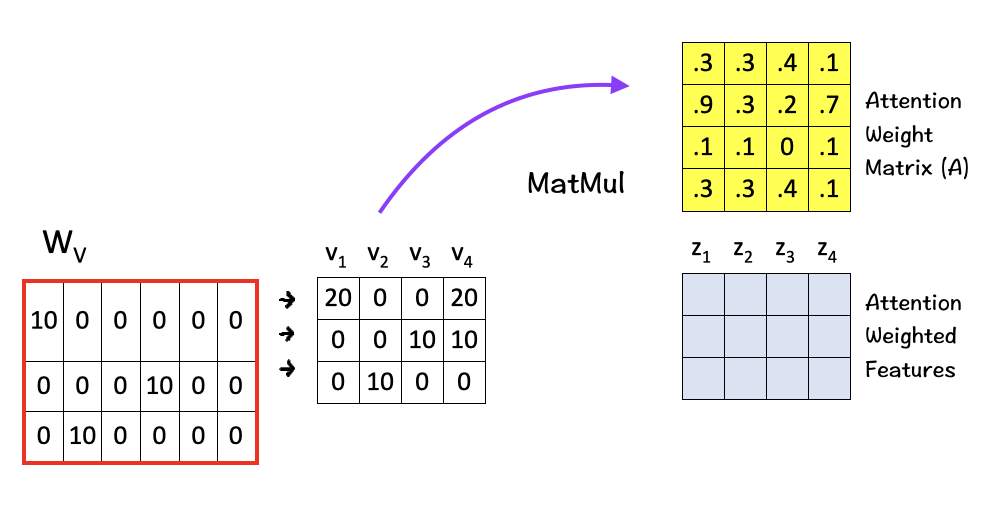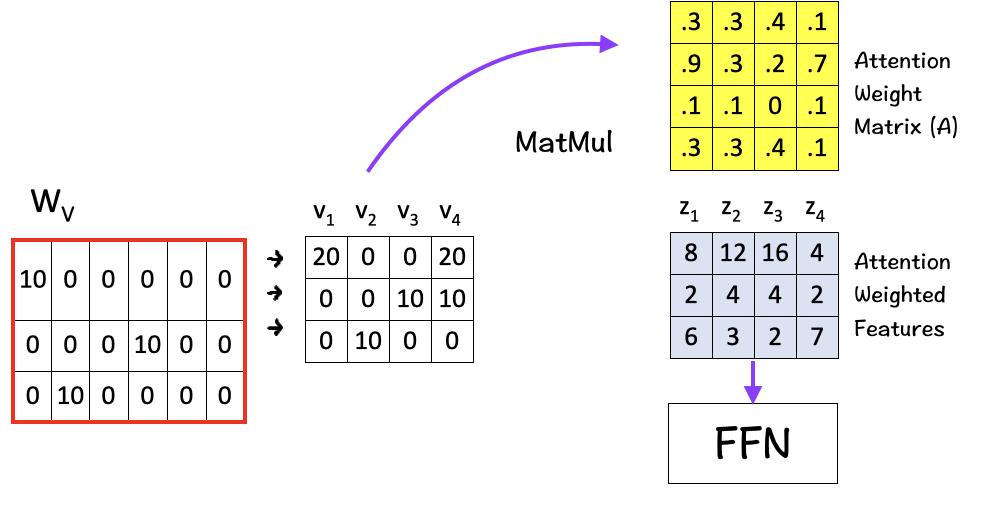
And the result of the final multiplication in this step are the attention weighted features Zs which are the ultimate solution of the self-attention mechanism. These attention-weighted features essentially contain a weighted representation of the features assigning higher weights for features with higher relevance as per the context.
Now with this information available, we continue to the next step in the transformer architecture where the feed-forward layer processes this information further.
And this brings us to the end of the brilliant self-attention technique!
Reviewing all the key points based on the ideas we talked about above:
To cater to a varied and overall representation of the sequence, multiple copies of the self-attention mechanism are implemented in parallel which are then concatenated to produce the final attention-weighted values. This is called the Multi-Head Attention.
Transformer in a Nutshell
This is how the inner-shell of the transformer architecture works. And bringing it together with the outer shell, here is a summary of the Transformer mechanism:
Transformers have been here for only a few years and the field of AI has already seen tremendous progress based on it. And the effort is still ongoing. When the authors of the paper used that title for their paper, they were not kidding.
It is interesting to see once again how a fundamental idea — the ‘dot product’ coupled with certain embellishments can turn out to be so powerful!

Image by author
P.S. If you would like to work through this exercise on your own, here are the blank templates for you to use.
Blank Template for hand-exercise
Now go have some fun with the exercise while paying attention to your Robtimus Prime!
Related Work:
Here are the other articles in the Deep Dive by Hand Series:

Deep Dive into Self-Attention by Hand✍︎ was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
Attention! Attention!
Because ‘Attention is All You Need’.
No, I am not saying that, the Transformer is.
Image by author (Robtimus Prime seeking attention. As per my son, bright rainbow colors work better for attention and hence the color scheme.)
As of today, the world has been swept over by the power of transformers. Not the likes of ‘Robtimus Prime’ but the ones that constitute neural networks. And that power is because of the concept of ‘attention’. So, what does attention in the context of transformers really mean? Let’s try to find out some answers here:
First and foremost:
What are transformers?
Transformers are neural networks that specialize in learning context from the data. Quite similar to us trying to find the meaning of ‘attention and context’ in terms of transformers.
How do transformers learn context from the data?
By using the attention mechanism.
What is the attention mechanism?
The attention mechanism helps the model scan all parts of a sequence at each step and determine which elements need to be focused on. The attention mechanism was proposed as an alternative to the ‘strict/hard’ solution of fixed-length vectors in the encoder-decoder architecture and provide a ‘soft’ solution focusing only on the relevant parts.
What is self-attention?
The attention mechanism worked to improve the performance of Recurrence Neural Networks (RNNs), with the effect seeping into Convolutional Neural Networks (CNNs). However, with the introduction of the transformer architecture in the year 2017, the need for RNNs and CNNs was quietly obliterated. And the central reason for it was the self-attention mechanism.
The self-attention mechanism was special in the sense that it was built to inculcate the context of the input sequence in order to enhance the attention mechanism. This idea became transformational as it was able to capture the complex nuances of a language.
As an example:
When I ask my 4-year old what transformers are, his answer only contains the words robots and cars. Because that is the only context he has. But for me, transformers also mean neural networks as this second context is available to the slightly more experienced mind of mine. And that is how different contexts provide different solutions and so tend to be very important.
The word ‘self’ refers to the fact that the attention mechanism examines the same input sequence that it is processing.There are many variations of how self-attention is performed. But the scaled dot-product mechanism has been one of the most popular ones. This was the one introduced in the original transformer architecture paper in 2017 — “Attention is All You Need”.
Where and how does self-attention feature in transformers?
I like to see the transformer architecture as a combination of two shells — the outer shell and the inner shell.
- The outer shell is a combination of the attention-weighting mechanism and the feed forward layer about which I talk in detail in this article.
- The inner shell consists of the self-attention mechanism and is part of the attention-weighting feature.
So, without further delay, let us dive into the details behind the self-attention mechanism and unravel the workings behind it. The Query-Key module and the SoftMax function play a crucial role in this technique.
This discussion is based on Prof. Tom Yeh’s wonderful AI by Hand Series on Self-Attention. (All the images below, unless otherwise noted, are by Prof. Tom Yeh from the above-mentioned LinkedIn post, which I have edited with his permission.)
So here we go:
Self-Attention
To build some context here, here is a pointer to how we process the ‘Attention-Weighting’ in the transformer outer shell.
Attention weight matrix (A)
The attention weight matrix A is obtained by feeding the input features into the Query-Key (QK) module. This matrix tries to find the most relevant parts in the input sequence. Self-Attention comes into play while creating the Attention weight matrix A using the QK-module.
How does the QK-module work?
Let us look at The different components of Self-Attention: Query (Q), Key (K) and Value (V).
I love using the spotlight analogy here as it helps me visualize the model throwing light on each element of the sequence and trying to find the most relevant parts. Taking this analogy a bit further, let us use it to understand the different components of Self-Attention.
Imagine a big stage getting ready for the world’s largest Macbeth production. The audience outside is teeming with excitement.
- The lead actor walks onto the stage, the spotlight shines on him and he asks in his booming voice “Should I seize the crown?”. The audience whispers in hushed tones and wonders which path this question will lead to. Thus, Macbeth himself represents the role of Query (Q) as he asks pivotal questions and drives the story forward.
- Based on Macbeth’s query, the spotlight shifts to other crucial characters that hold information to the answer. The influence of other crucial characters in the story, like Lady Macbeth, triggers Macbeth’s own ambitions and actions. These other characters can be seen as the Key (K) as they unravel different facets of the story based on the particular they know.
- Finally, these characters provide enough motivation and information to Macbeth by their actions and perspectives. These can be seen as Value (V). The Value (V) pushes Macbeth towards his decisions and shapes the fate of the story.
And with that is created one of the world’s finest performances, that remains etched in the minds of the awestruck audience for the years to come.
Now that we have witnessed the role of Q, K, V in the fantastical world of performing arts, let’s return to planet matrices and learn the mathematical nitty-gritty behind the QK-module. This is the roadmap that we will follow:
Roadmap for the Self-Attention mechanism
And so the process begins.
We are given:
A set of 4-feature vectors (Dimension 6)
Our goal :
Transform the given features into Attention Weighted Features.
[1] Create Query, Key, Value Matrices
To do so, we multiply the features with linear transformation matrices W_Q, W_K, and W_V, to obtain query vectors (q1,q2,q3,q4), key vectors (k1,k2,k3,k4), and value vectors (v1,v2,v3,v4) respectively as shown below:
To get Q, multiply W_Q with X:
To get K, multiply W_K with X:
Similarly, to get V, multiply W_V with X.
To be noted:
- As can be seen from the calculation above, we use the same set of features for both queries and keys. And that is how the idea of “self” comes into play here, i.e. the model uses the same set of features to create its query vector as well as the key vector.
- The query vector represents the current word (or token) for which we want to compute attention scores relative to other words in the sequence.
- The key vector represents the other words (or tokens) in the input sequence and we compute the attention score for each of them with respect to the current word.
[2] Matrix Multiplication
The next step is to multiply the transpose of K with Q i.e. K^T . Q.
The idea here is to calculate the dot product between every pair of query and key vectors. Calculating the dot product gives us an estimate of the matching score between every “key-query” pair, by using the idea of Cosine Similarity between the two vectors. This is the ‘dot-product’ part of the scaled dot-product attention.
Cosine-Similarity
Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths. It roughly measures if two vectors are pointing in the same direction thus implying the two vectors are similar.
Remember cos(0°) = 1, cos(90°) = 0 , cos(180°) =-1
- If the dot product between the two vectors is approximately 1, it implies we are looking at an almost zero angle between the two vectors meaning they are very close to each other.
- If the dot product between the two vectors is approximately 0, it implies we are looking at vectors that are orthogonal to each other and not very similar.
- If the dot product between the two vectors is approximately -1, it implies we are looking at an almost an 180° angle between the two vectors meaning they are opposites.
[3] Scale
The next step is to scale/normalize each element by the square root of the dimension ‘d_k’. In our case the number is 3. Scaling down helps to keep the impact of the dimension on the matching score in check.
How does it do so? As per the original Transformer paper and going back to Probability 101, if two independent and identically distributed (i.i.d) variables q and k with mean 0 and variance 1 with dimension d are multiplied, the result is a new random variable with mean remaining 0 but variance changing to d_k.
Now imagine how the matching score would look if our dimension is increased to 32, 64, 128 or even 4960 for that matter. The larger dimension would make the variance higher and push the values into regions ‘unknown’.
To keep the calculation simple here, since sqrt [3] is approximately 1.73205, we replace it with [ floor(□/2) ].
Floor Function
The floor function takes a real number as an argument and returns the largest integer less than or equal to that real number.
Eg : floor(1.5) = 1, floor(2.9) = 2, floor (2.01) = 2, floor(0.5) = 0.
The opposite of the floor function is the ceiling function.
This the ‘scaled’ part of the scaled dot-product attention.
[4] Softmax
There are three parts to this step:
- Raise e to the power of the number in each cell (To make things easy, we use 3 to the power of the number in each cell.)
- Sum these new values across each column.
- For each column, divide each element by its respective sum (Normalize). The purpose of normalizing each column is to have numbers sum up to 1. In other words, each column then becomes a probability distribution of attention, which gives us our Attention Weight Matrix (A).
This Attention Weight Matrix is what we had obtained after passing our feature matrix through the QK-module in Step 2 in the Transformers section.
The Softmax step is important as it assigns probabilities to the score obtained in the previous steps and thus helps the model decide how much importance (higher/lower attention weights) needs to be given to each word given the current query. As is to be expected, higher attention weights signify greater relevance allowing the model to capture dependencies more accurately.
Once again, the scaling in the previous step becomes important here. Without the scaling, the values of the resultant matrix gets pushed out into regions that are not processed well by the Softmax function and may result in vanishing gradients.
[5] Matrix Multiplication
Finally we multiply the value vectors (Vs) with the Attention Weight Matrix (A). These value vectors are important as they contain the information associated with each word in the sequence.
And the result of the final multiplication in this step are the attention weighted features Zs which are the ultimate solution of the self-attention mechanism. These attention-weighted features essentially contain a weighted representation of the features assigning higher weights for features with higher relevance as per the context.
Now with this information available, we continue to the next step in the transformer architecture where the feed-forward layer processes this information further.
And this brings us to the end of the brilliant self-attention technique!
Reviewing all the key points based on the ideas we talked about above:
- Attention mechanism was the result of an effort to better the performance of RNNs, addressing the issue of fixed-length vector representations in the encoder-decoder architecture. The flexibility of soft-length vectors with a focus on the relevant parts of a sequence was the core strength behind attention.
- Self-attention was introduced as a way to inculcate the idea of context into the model. The self-attention mechanism evaluates the same input sequence that it processes, hence the use of the word ‘self’.
- There are many variants to the self-attention mechanism and efforts are ongoing to make it more efficient. However, scaled dot-product attention is one of the most popular ones and a crucial reason why the transformer architecture was deemed to be so powerful.
- Scaled dot-product self-attention mechanism comprises the Query-Key module (QK-module) along with the Softmax function. The QK module is responsible for extracting the relevance of each element of the input sequence by calculating the attention scores and the Softmax function complements it by assigning probability to the attention scores.
- Once the attention-scores are calculated, they are multiplied with the value vector to obtain the attention-weighted features which are then passed on to the feed-forward layer.
To cater to a varied and overall representation of the sequence, multiple copies of the self-attention mechanism are implemented in parallel which are then concatenated to produce the final attention-weighted values. This is called the Multi-Head Attention.
Transformer in a Nutshell
This is how the inner-shell of the transformer architecture works. And bringing it together with the outer shell, here is a summary of the Transformer mechanism:
- The two big ideas in the Transformer architecture here are attention-weighting and the feed-forward layer (FFN). Both of them combined together allow the Transformer to analyze the input sequence from two directions. Attention looks at the sequence based on positions and the FFN does it based on the dimensions of the feature matrix.
- The part that powers the attention mechanism is the scaled dot-product Attention which consists of the QK-module and outputs the attention weighted features.
Transformers have been here for only a few years and the field of AI has already seen tremendous progress based on it. And the effort is still ongoing. When the authors of the paper used that title for their paper, they were not kidding.
It is interesting to see once again how a fundamental idea — the ‘dot product’ coupled with certain embellishments can turn out to be so powerful!
Image by author
P.S. If you would like to work through this exercise on your own, here are the blank templates for you to use.
Blank Template for hand-exercise
Now go have some fun with the exercise while paying attention to your Robtimus Prime!
Related Work:
Here are the other articles in the Deep Dive by Hand Series:
- Deep Dive into Vector Databases by Hand ✍ that explores what exactly happens behind-the-scenes in Vector Databases.
- Deep Dive into Sora’s Diffusion Transformer (DiT) by Hand ✍ that explores the secret behind Sora’s state-of-the-art videos.
- Deep Dive into Transformers by Hand ✍ that explores the power behind the power of transformers.
- Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
- Bahdanau, Dzmitry, Kyunghyun Cho and Yoshua Bengio. “Neural Machine Translation by Jointly Learning to Align and Translate.” CoRR abs/1409.0473 (2014).
Deep Dive into Self-Attention by Hand✍︎ was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.