Pushing RL Boundaries: Integrating Foundational Models, e.g. LLMs and VLMs, into Reinforcement Learning
In-Depth Exploration of Integrating Foundational Models such as LLMs and VLMs into RL Training Loop
Authors: Elahe Aghapour, Salar Rahili
Overview:
With the rise of the transformer architecture and high-throughput compute, training foundational models has turned into a hot topic recently. This has led to promising efforts to either integrate or train foundational models to enhance the capabilities of reinforcement learning (RL) algorithms, signaling an exciting direction for the field. Here, we’re discussing how foundational models can give reinforcement learning a major boost.
Before diving into the latest research on how foundational models can give reinforcement learning a major boost, let’s engage in a brainstorming session. Our goal is to pinpoint areas where pre-trained foundational models, particularly Large Language Models (LLMs) or Vision-Language Models (VLMs), could assist us, or how we might train a foundational model from scratch. A useful approach is to examine each element of the reinforcement learning training loop individually, to identify where there might be room for improvement:
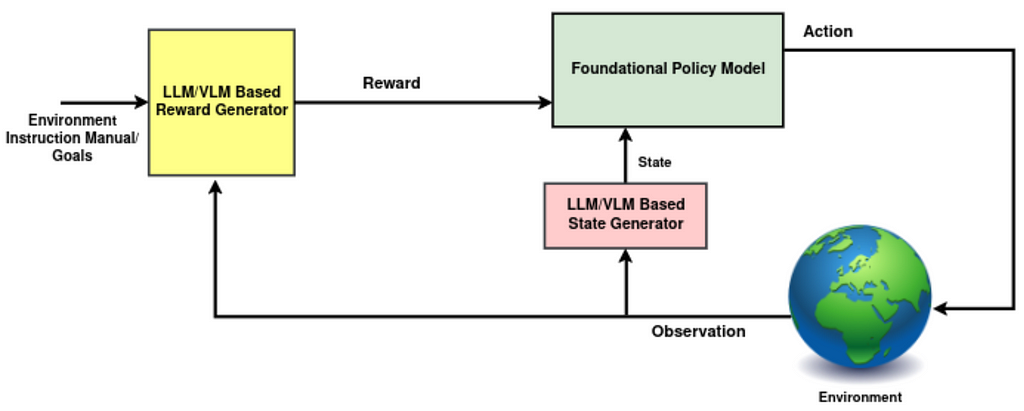
Fig 1: Overview of foundation models in RL (Image by author)
1- Environment: Given that pre-trained foundational models understand the causal relationships between events, they can be utilized to forecast environmental changes resulting from current actions. Although this concept is intriguing, we’re not yet aware of any specific studies that focus on it. There are two primary reasons holding us back from exploring this idea further for now.
2- State (LLM/VLM Based State Generator): While experts often use the terms observation and state interchangeably, there are distinctions between them. A state is a comprehensive representation of the environment, while an observation may only provide partial information. In the standard RL framework, we don’t often discuss the specific transformations that extract and merge useful features from observations, past actions, and any internal knowledge of the environment to produce “state”, the policy input. Such a transformation could be significantly enhanced by employing LLMs/VLMs, which allow us to infuse the “state” with broader knowledge of the world, physics, and history (refer to Fig. 1, highlighted in pink).
3- Policy (Foundational Policy Model): Integrating foundational models into the policy, the central decision-making component in RL, can be highly beneficial. Although employing such models to generate high-level plans has proven successful, transforming the state into low-level actions has challenges we’ll delve into later. Fortunately, there has been some promising research in this area recently.
4- Reward (LLM/VLM Based Reward Generator): Leveraging foundational models to more accurately assess chosen actions within a trajectory has been a primary focus among researchers. This comes as no surprise, given that rewards have traditionally served as the communication channel between humans and agents, setting goals and guiding the agent towards what is desired.
1- Foundational models in reward
It is challenging to use foundational models to generate low level control actions as low level actions are highly dependent on the setting of the agent and are underrepresented in foundational models’ training dataset. Hence, the foundation model application is generally focused on high level plans rather than low level actions. Reward bridges the gap between high-level planner and low level actions where foundation models can be used. Researchers have adopted various methodologies integrating foundation models for reward assignment. However, the core principle revolves around employing a VLM/LLM to effectively track the progress towards a subgoal or task.
1.a Assigning reward values based on similarity
Consider the reward value as a signal that indicates whether the agent’s previous action was beneficial in moving towards the goal. A sensible method involves evaluating how closely the previous action aligns with the current objective. To put this approach into practice, as can be seen in Fig. 2, it’s essential to:
- Generate meaningful embeddings of these actions, which can be done through images, videos, or text descriptions of the most recent observation.
- Generate meaningful representations of the current objective.
- Assess the similarity between these representations.
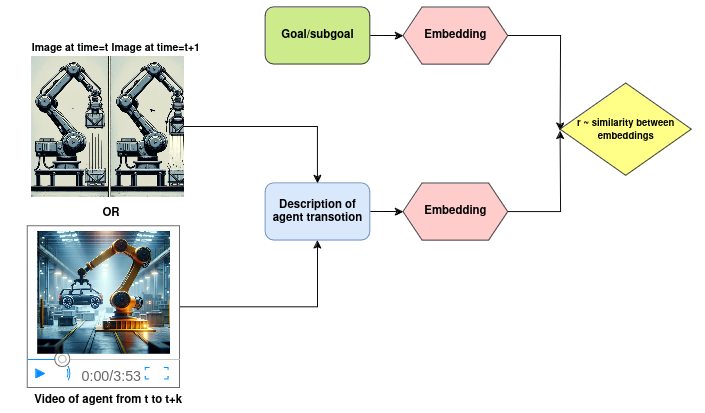
Fig 2. Reward values based on similarity (Image by author).
Let’s explore the specific mechanics behind the leading research in this area.
Dense and well-shaped reward functions enhance the stability and training speed of the RL agent. Intrinsic rewards address this challenge by rewarding the agent for novel states’ exploration. However, in large environments where most of the unseen states are irrelevant to the downstream task, this approach becomes less effective. ELLM uses background knowledge of LLM to shape the exploration. It queries LLM to generate a list of possible goals/subgoals given a list of the agent’s available actions and a text description of the agent current observation, generated by a state captioner. Then, at each time step, the reward is computed by the semantic similarity, cosine similarity, between the LLM generated goal and the description of the agent’s transition.
LiFT has a similar framework but also leverages CLIP4Clip-style VLMs for reward assignment. CLIP4Clip is pre-trained to align videos and corresponding language descriptions through contrastive learning. In LiFT, the agent is rewarded based on the alignment score, cosine similarity, between the task instructions and videos of the agent’s corresponding behavior, both encoded by CLIP4CLIP.
UAFM has a similar framework where the main focus is on robotic manipulation tasks, e.g., stacking a set of objects. For reward assignment, they measure the similarity between the agent state image and the task description, both embedded by CLIP. They finetune CLIP on a small amount of data from the simulated stacking domain to be more aligned in this use case.
1.b Assigning rewards through reasoning on auxiliary tasks:
In scenarios where the foundational model has the proper understanding of the environment, it becomes feasible to directly pass the observations within a trajectory to the model, LLM/VLM. This evaluation can be done either through straightforward QA sessions based on the observations or by verifying the model’s capability in predicting the goal only by looking at the observation trajectory.
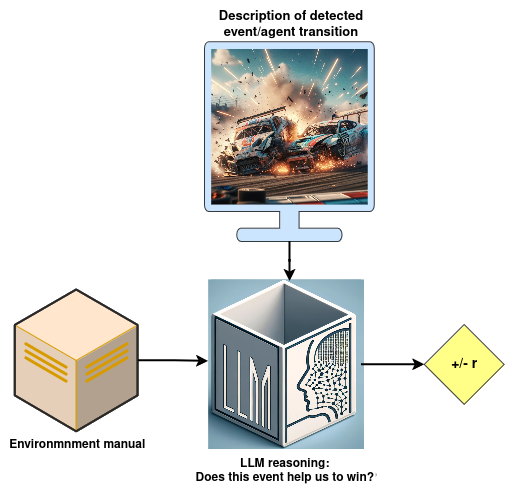
Fig 3. Assigning reward through reasoning (Image by author).
Read and Reward integrates the environment’s instruction manual into reward generation through two key components, as can be seen in Fig. 3:
EAGER introduces a unique method for creating intrinsic rewards through a specially designed auxiliary task. This approach presents a novel concept where the auxiliary task involves predicting the goal based on the current observation. If the model predicts accurately, this indicates a strong alignment with the intended goal, and thus, a larger intrinsic reward is given based on the prediction confidence level. To achieve this goal, To accomplish this, two modules are employed:
(P.S. Although this work does not utilize a foundational model, we’ve included it here due to its intriguing approach, which can be easily adapted to any pre-trained LLM)
1.c Generating reward function code
Up to this point, we’ve discussed generating reward values directly for the reinforcement learning algorithms. However, running a large model at every step of the RL loop can significantly slow down the speed of both training and inference. To bypass this bottleneck, one strategy involves utilizing our foundational model to generate the code for the reward function. This allows for the direct generation of reward values at each step, streamlining the process.
For the code generation schema to work effectively, two key components are required:
1- A code generator, LLM, which receives a detailed prompt containing all the necessary information to craft the code.
2- A refinement process that evaluates and enhances the code in collaboration with the code generator.
Let’s look at the key contributions for generating reward code:
R2R2S generates reward function code through two main components:
Text2Reward develops a method to generate dense reward functions as an executable code within iterative refinement. Given the subgoal of the task, it has two key components:
Auto MC-Reward has a similar algorithm to Text2Reward, to generate the reward function code, see Fig. 4. The main difference is in the refinement stage where it has two modules, both LLMs:
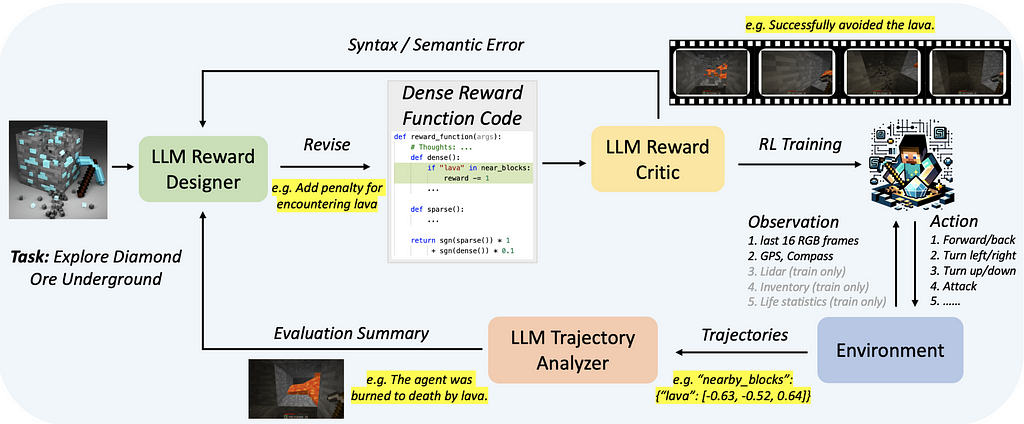
Fig 4. Overview of Auto MC-Reward (paper taken from Auto MC-Reward paper)
EUREKA generates reward code without the need for task-specific prompting, predefined reward templates, or predefined few-shot examples. To achieve this goal, it has two stages:
Within these two steps, EUREKA is able to generate reward functions that outperform expert human-engineered rewards without any task specific templates.
1.d. Train a reward model based on preferences (RLAIF)
An alternative method is to use a foundational model to generate data for training a reward function model. The significant successes of Reinforcement Learning with Human Feedback (RLHF) have recently drawn increased attention towards employing trained reward functions on a larger scale. The heart of such algorithms is the use of a preference dataset to train a reward model which can subsequently be integrated into reinforcement learning algorithms. Given the high cost associated with generating preference data (e.g., action A is preferable to action B) through human feedback, there’s growing interest in constructing this dataset by obtaining feedback from an AI agent, i.e. VLM/LLM. Training a reward function, using AI-generated data and integrating it within a reinforcement learning algorithm, is known as Reinforcement Learning with AI Feedback (RLAIF).
MOTIF requires access to a passive dataset of observations with sufficient coverage. Initially, LLM is queried with a summary of desired behaviors within the environment and a text description of two randomly sampled observations. It then generates the preference, selecting between 1, 2, or 0 (indicating no preference), as seen in Fig. 5. This process constructs a dataset of preferences between observation pairs. Subsequently, this dataset is used to train a reward model employing preference based RL techniques.
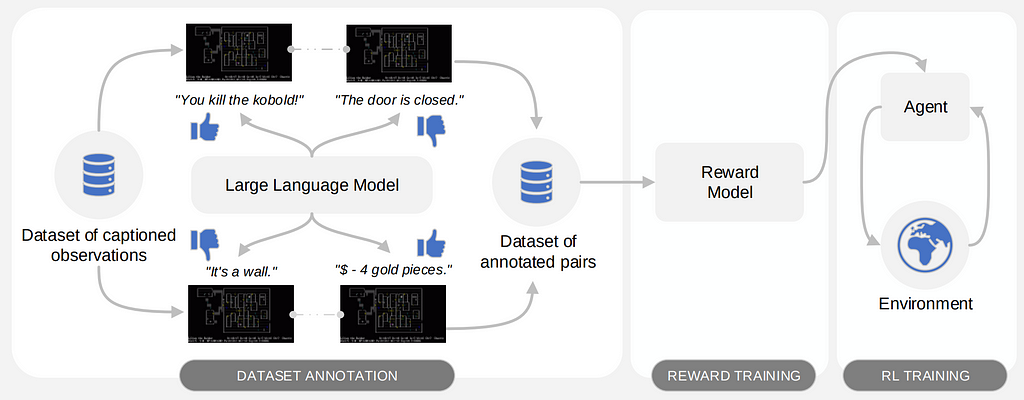
Fig 5. A schematic representation of the three phases of MOTIF (image taken from MOTIF paper)
2- Foundation models as Policy
Achieving the capability to train a foundational policy that not only excels in tasks previously encountered but also possesses the ability to reason about and adapt to new tasks using past learning, is an ambition within the RL community. Such a policy would ideally generalize from past experiences to tackle novel situations and, through environmental feedback, achieve goals previously unseen with human-like adaptability.
However, several challenges stand in the way of training such agents. Among these challenges are:
Up to now, it’s mostly been teams with substantial resources and top-notch setups who’ve really pushed the envelope in this domain.
AdA paved the way for training an RL foundation model within the X.Land 2.0 3D environment. This model achieves human time-scale adaptation on held-out test tasks without any further training. The model’s success is founded on three ingredients:
RT-2 introduces a method to co-finetune a VLM on both robotic trajectory data and vision-language tasks, resulting in a policy model called RT-2. To enable vision-language models to generate low-level actions, actions are discretized into 256 bins and represented as language tokens.
By representing actions as language tokens, RT-2 can directly utilize pre-existing VLM architectures without requiring substantial modifications. Hence, VLM input includes robot camera image and textual task description formatted similarly to Vision Question Answering tasks and the output is a series of language tokens that represent the robot’s low-level actions; see Fig. 6.
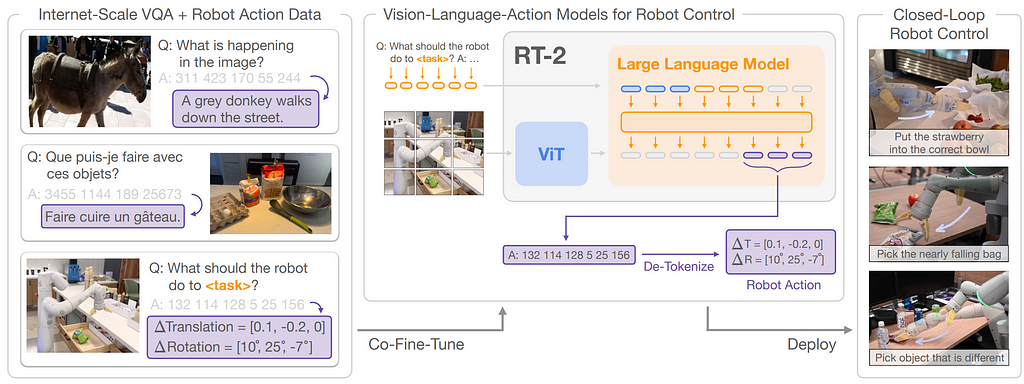
Fig 6. RT-2 overview (image taken from RT-2 paper)
They noticed that co-finetuning on both types of data with the original web data leads to more generalizable policies. The co-finetuning process equips RT-2 with the ability to understand and execute commands that were not explicitly present in its training data, showcasing remarkable adaptability. This approach enabled them to leverage internet-scale pretraining of VLM to generalize to novel tasks through semantic reasoning.
3- Foundation Models as State Representation
In RL, a policy’s understanding of the environment at any given moment comes from its “state” which is essentially how it perceives its surroundings. Looking at the RL block diagram, a reasonable module to inject world knowledge into is the state. If we can enrich observations with general knowledge useful for completing tasks, the policy can pick up new tasks much faster compared to RL agents that begin learning from scratch.
PR2L introduces a novel approach to inject the background knowledge of VLMs from internet scale data into RL.PR2L employs generative VLMs which generate language in response to an image and a text input. As VLMs are proficient in understanding and responding to visual and textual inputs, they can provide a rich source of semantic features from observations to be linked to actions.
PR2L, queries a VLM with a task-relevant prompt for each visual observation received by the agent, and receives both the generated textual response and the model’s intermediate representations. They discard the text and use some or all of the models intermediate representation generated for both the visual and text input and the VLM’s generated textual response as “promptable representations”. Due to the variable size of these representations, PR2L incorporates an encoder-decoder Transformer layer to embed all the information embedded in promptable representations into a fixed size embedding. This embedding, combined with any available non-visual observation data, is then provided to the policy network, representing the state of the agent. This innovative integration allows the RL agent to leverage the rich semantic understanding and background knowledge of VLMs, facilitating more rapid and informed learning of tasks.
References:
[1] ELLM: Du, Yuqing, et al. “Guiding pretraining in reinforcement learning with large language models.” 2023.
[2] Text2Reward: Xie, Tianbao, et al. “Text2reward: Automated dense reward function generation for reinforcement learning.” 2023.
[3] R2R2S: Yu, Wenhao, et al. “Language to rewards for robotic skill synthesis.” 2023.
[4] EUREKA: Ma, Yecheng Jason, et al. “Eureka: Human-level reward design via coding large language models.” 2023.
[5] MOTIF: Klissarov, Martin, et al. “Motif: Intrinsic motivation from artificial intelligence feedback.” 2023.
[6] Read and Reward: Wu, Yue, et al. “Read and reap the rewards: Learning to play atari with the help of instruction manuals.” 2024.
[7] Auto MC-Reward: Li, Hao, et al. “Auto MC-reward: Automated dense reward design with large language models for minecraft.” 2023.
[8] EAGER: Carta, Thomas, et al. “Eager: Asking and answering questions for automatic reward shaping in language-guided RL.” 2022.
[9] LiFT: Nam, Taewook, et al. “LiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers.” 2023.
[10] UAFM: Di Palo, Norman, et al. “Towards a unified agent with foundation models.” 2023.
[11] RT-2: Brohan, Anthony, et al. “Rt-2: Vision-language-action models transfer web knowledge to robotic control.” 2023.
[12] AdA: Team, Adaptive Agent, et al. “Human-timescale adaptation in an open-ended task space.” 2023.
[13] PR2L: Chen, William, et al. “Vision-Language Models Provide Promptable Representations for Reinforcement Learning.” 2024.
[14] Clip4Clip: Luo, Huaishao, et al. “Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.” 2022.
[15] Clip: Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” 2021.
[16] RoBERTa: Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” 2019.
[17] Preference based RL: SWirth, Christian, et al. “A survey of preference-based reinforcement learning methods.” 2017.
[18] Muesli: Hessel, Matteo, et al. “Muesli: Combining improvements in policy optimization.” 2021.
[19] Melo, Luckeciano C. “Transformers are meta-reinforcement learners.” 2022.
[20] RLHF: Ouyang, Long, et al. “Training language models to follow instructions with human feedback, 2022.

Pushing RL Boundaries: Integrating Foundational Models, e.g. was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.
In-Depth Exploration of Integrating Foundational Models such as LLMs and VLMs into RL Training Loop
Authors: Elahe Aghapour, Salar Rahili
Overview:
With the rise of the transformer architecture and high-throughput compute, training foundational models has turned into a hot topic recently. This has led to promising efforts to either integrate or train foundational models to enhance the capabilities of reinforcement learning (RL) algorithms, signaling an exciting direction for the field. Here, we’re discussing how foundational models can give reinforcement learning a major boost.
Before diving into the latest research on how foundational models can give reinforcement learning a major boost, let’s engage in a brainstorming session. Our goal is to pinpoint areas where pre-trained foundational models, particularly Large Language Models (LLMs) or Vision-Language Models (VLMs), could assist us, or how we might train a foundational model from scratch. A useful approach is to examine each element of the reinforcement learning training loop individually, to identify where there might be room for improvement:
Fig 1: Overview of foundation models in RL (Image by author)
1- Environment: Given that pre-trained foundational models understand the causal relationships between events, they can be utilized to forecast environmental changes resulting from current actions. Although this concept is intriguing, we’re not yet aware of any specific studies that focus on it. There are two primary reasons holding us back from exploring this idea further for now.
- While the reinforcement learning training process demands highly accurate predictions for the next step observations, pre-trained LLMs/VLMs haven’t been directly trained on datasets that enable such precise forecasting and thus fall short in this aspect. It’s important to note, as we highlighted in our previous post, that a high-level planner, particularly one used in lifelong learning scenarios, could effectively incorporate a foundational model.
- Latency in environment steps is a critical factor that can constrain the RL algorithm, especially when working within a fixed budget for training steps. The presence of a very large model that introduces significant latency can be quite restrictive. Note that while it might be challenging, distillation into a smaller network can be a solution here.
2- State (LLM/VLM Based State Generator): While experts often use the terms observation and state interchangeably, there are distinctions between them. A state is a comprehensive representation of the environment, while an observation may only provide partial information. In the standard RL framework, we don’t often discuss the specific transformations that extract and merge useful features from observations, past actions, and any internal knowledge of the environment to produce “state”, the policy input. Such a transformation could be significantly enhanced by employing LLMs/VLMs, which allow us to infuse the “state” with broader knowledge of the world, physics, and history (refer to Fig. 1, highlighted in pink).
3- Policy (Foundational Policy Model): Integrating foundational models into the policy, the central decision-making component in RL, can be highly beneficial. Although employing such models to generate high-level plans has proven successful, transforming the state into low-level actions has challenges we’ll delve into later. Fortunately, there has been some promising research in this area recently.
4- Reward (LLM/VLM Based Reward Generator): Leveraging foundational models to more accurately assess chosen actions within a trajectory has been a primary focus among researchers. This comes as no surprise, given that rewards have traditionally served as the communication channel between humans and agents, setting goals and guiding the agent towards what is desired.
- Pre-trained foundational models come with a deep knowledge of the world, and injecting this kind of understanding into our decision-making processes can make those decisions more in tune with human desires and more likely to succeed. Moreover, using foundational models to evaluate the agent’s actions can quickly trim down the search space and equip the agent with a head start in understanding, as opposed to starting from scratch.
- Pre-trained foundational models have been trained on internet-scale data generated mostly by humans, which has enabled them to understand worlds similarly to humans. This makes it possible to use foundational models as cost-effective annotators. They can generate labels or assess trajectories or rollouts on a large scale.
1- Foundational models in reward
It is challenging to use foundational models to generate low level control actions as low level actions are highly dependent on the setting of the agent and are underrepresented in foundational models’ training dataset. Hence, the foundation model application is generally focused on high level plans rather than low level actions. Reward bridges the gap between high-level planner and low level actions where foundation models can be used. Researchers have adopted various methodologies integrating foundation models for reward assignment. However, the core principle revolves around employing a VLM/LLM to effectively track the progress towards a subgoal or task.
1.a Assigning reward values based on similarity
Consider the reward value as a signal that indicates whether the agent’s previous action was beneficial in moving towards the goal. A sensible method involves evaluating how closely the previous action aligns with the current objective. To put this approach into practice, as can be seen in Fig. 2, it’s essential to:
- Generate meaningful embeddings of these actions, which can be done through images, videos, or text descriptions of the most recent observation.
- Generate meaningful representations of the current objective.
- Assess the similarity between these representations.
Fig 2. Reward values based on similarity (Image by author).
Let’s explore the specific mechanics behind the leading research in this area.
Dense and well-shaped reward functions enhance the stability and training speed of the RL agent. Intrinsic rewards address this challenge by rewarding the agent for novel states’ exploration. However, in large environments where most of the unseen states are irrelevant to the downstream task, this approach becomes less effective. ELLM uses background knowledge of LLM to shape the exploration. It queries LLM to generate a list of possible goals/subgoals given a list of the agent’s available actions and a text description of the agent current observation, generated by a state captioner. Then, at each time step, the reward is computed by the semantic similarity, cosine similarity, between the LLM generated goal and the description of the agent’s transition.
LiFT has a similar framework but also leverages CLIP4Clip-style VLMs for reward assignment. CLIP4Clip is pre-trained to align videos and corresponding language descriptions through contrastive learning. In LiFT, the agent is rewarded based on the alignment score, cosine similarity, between the task instructions and videos of the agent’s corresponding behavior, both encoded by CLIP4CLIP.
UAFM has a similar framework where the main focus is on robotic manipulation tasks, e.g., stacking a set of objects. For reward assignment, they measure the similarity between the agent state image and the task description, both embedded by CLIP. They finetune CLIP on a small amount of data from the simulated stacking domain to be more aligned in this use case.
1.b Assigning rewards through reasoning on auxiliary tasks:
In scenarios where the foundational model has the proper understanding of the environment, it becomes feasible to directly pass the observations within a trajectory to the model, LLM/VLM. This evaluation can be done either through straightforward QA sessions based on the observations or by verifying the model’s capability in predicting the goal only by looking at the observation trajectory.
Fig 3. Assigning reward through reasoning (Image by author).
Read and Reward integrates the environment’s instruction manual into reward generation through two key components, as can be seen in Fig. 3:
- QA extraction module: it creates a summary of game objectives and features. This LLM-based module, RoBERTa-large, takes in the game manual and a question, and extracts the corresponding answer from the text. Questions are focused on the game objective, and agent-object interaction, identified by their significance using TF-IDF. For each critical object, a question as: “What happens when the player hits a <object>?” is added to the question set. A summary is then formed with the concatenation of all non-empty question-answer pairs.
- Reasoning module: During gameplay, a rule-based algorithm detects “hit” events. Following each “hit” event, the LLM based reasoning module is queried with the summary of the environment and a question: “Should you hit a <object of interaction> if you want to win?” where the possible answer is limited to {yes, no}. A “yes” response adds a positive reward, while “no” leads to a negative reward.
EAGER introduces a unique method for creating intrinsic rewards through a specially designed auxiliary task. This approach presents a novel concept where the auxiliary task involves predicting the goal based on the current observation. If the model predicts accurately, this indicates a strong alignment with the intended goal, and thus, a larger intrinsic reward is given based on the prediction confidence level. To achieve this goal, To accomplish this, two modules are employed:
- Question Generation (QG): This component works by masking all nouns and adjectives in the detailed objective provided by the user.
- Question Answering (QA): This is a model trained in a supervised manner, which takes the observation, question masks, and actions, and predicts the masked tokens.
(P.S. Although this work does not utilize a foundational model, we’ve included it here due to its intriguing approach, which can be easily adapted to any pre-trained LLM)
1.c Generating reward function code
Up to this point, we’ve discussed generating reward values directly for the reinforcement learning algorithms. However, running a large model at every step of the RL loop can significantly slow down the speed of both training and inference. To bypass this bottleneck, one strategy involves utilizing our foundational model to generate the code for the reward function. This allows for the direct generation of reward values at each step, streamlining the process.
For the code generation schema to work effectively, two key components are required:
1- A code generator, LLM, which receives a detailed prompt containing all the necessary information to craft the code.
2- A refinement process that evaluates and enhances the code in collaboration with the code generator.
Let’s look at the key contributions for generating reward code:
R2R2S generates reward function code through two main components:
- LLM based motion descriptor: This module uses a pre-defined template to describe robot movements, and leverages Large Language Models (LLMs) to understand the motion. The Motion Descriptor fills in the template, replacing placeholders e.g. “Destination Point Coordinate” with specific details, to describe the desired robot motion within a pre-defined template.
- LLM based reward coder: this component generates the reward function by processing a prompt containing: a motion description, a list of functions with their description that LLM can use to generate the reward function code, an example code of how the response should look like, and constraints and rules the reward function must follow.
Text2Reward develops a method to generate dense reward functions as an executable code within iterative refinement. Given the subgoal of the task, it has two key components:
- LLM-based reward coder: generates reward function code. Its prompt consists of: an abstract of observation and available actions, a compact pythonic style environment to represent the configuration of the objects, robot, and callable functions; a background knowledge for reward function design (e.g. “reward function for task X typically includes a term for the distance between object x and y”), and a few-shot examples. They assume access to a pool of instruction, and reward function pairs that top k similar instructions are retrieved as few-shot examples.
- LLM-Based Refinement: once the reward code is generated, the code is executed to identify the syntax errors and runtime errors. These feedbacks are integrated into subsequent prompts to generate more refined reward functions. Additionally, human feedback is requested based on a task execution video by the current policy.
Auto MC-Reward has a similar algorithm to Text2Reward, to generate the reward function code, see Fig. 4. The main difference is in the refinement stage where it has two modules, both LLMs:
- LLM-Based Reward Critic: It evaluates the code and provides feedback on whether the code is self-consistent and free of syntax and semantic errors.
- LLM-Based Trajectory Analyser: It reviews the historical information of the interaction between the trained agent and the environment and uses it to guide the modifications of the reward function.
Fig 4. Overview of Auto MC-Reward (paper taken from Auto MC-Reward paper)
EUREKA generates reward code without the need for task-specific prompting, predefined reward templates, or predefined few-shot examples. To achieve this goal, it has two stages:
- LLM-based code generation: The raw environment code, the task, generic reward design and formatting tips are fed to the LLM as context and LLM returns the executable reward code with a list of its components.
- Evolutionary search and refinement: At each iteration, EUREKA queries the LLM to generate several i.i.d reward functions. Training an agent with executable reward functions provides feedback on how well the agent is performing. For a detailed and focused analysis of the rewards, the feedback also includes scalar values for each component of the reward function. The LLM takes top-performing reward code along with this detailed feedback to mutate the reward code in-context. In each subsequent iteration, the LLM uses the top reward code as a reference to generate K more i.i.d reward codes. This iterative optimization continues until a specified number of iterations has been reached.
Within these two steps, EUREKA is able to generate reward functions that outperform expert human-engineered rewards without any task specific templates.
1.d. Train a reward model based on preferences (RLAIF)
An alternative method is to use a foundational model to generate data for training a reward function model. The significant successes of Reinforcement Learning with Human Feedback (RLHF) have recently drawn increased attention towards employing trained reward functions on a larger scale. The heart of such algorithms is the use of a preference dataset to train a reward model which can subsequently be integrated into reinforcement learning algorithms. Given the high cost associated with generating preference data (e.g., action A is preferable to action B) through human feedback, there’s growing interest in constructing this dataset by obtaining feedback from an AI agent, i.e. VLM/LLM. Training a reward function, using AI-generated data and integrating it within a reinforcement learning algorithm, is known as Reinforcement Learning with AI Feedback (RLAIF).
MOTIF requires access to a passive dataset of observations with sufficient coverage. Initially, LLM is queried with a summary of desired behaviors within the environment and a text description of two randomly sampled observations. It then generates the preference, selecting between 1, 2, or 0 (indicating no preference), as seen in Fig. 5. This process constructs a dataset of preferences between observation pairs. Subsequently, this dataset is used to train a reward model employing preference based RL techniques.
Fig 5. A schematic representation of the three phases of MOTIF (image taken from MOTIF paper)
2- Foundation models as Policy
Achieving the capability to train a foundational policy that not only excels in tasks previously encountered but also possesses the ability to reason about and adapt to new tasks using past learning, is an ambition within the RL community. Such a policy would ideally generalize from past experiences to tackle novel situations and, through environmental feedback, achieve goals previously unseen with human-like adaptability.
However, several challenges stand in the way of training such agents. Among these challenges are:
- The necessity of managing a very large model, which introduces significant latency into the decision-making process for low-level control actions.
- The requirement to collect a vast amount of interaction data across a wide array of tasks to enable effective learning.
- Additionally, the process of training a very large network from scratch using RL introduces extra complexities. This is because backpropagation efficiency inherently is weaker in RL compared to supervised training methods .
Up to now, it’s mostly been teams with substantial resources and top-notch setups who’ve really pushed the envelope in this domain.
AdA paved the way for training an RL foundation model within the X.Land 2.0 3D environment. This model achieves human time-scale adaptation on held-out test tasks without any further training. The model’s success is founded on three ingredients:
- The core of the AdA’s learning mechanism is a Transformer-XL architecture from 23 to 265 million parameters, employed alongside the Muesli RL algorithm. Transformer-XL takes in a trajectory of observations, actions, and rewards from time t to T and outputs a sequence of hidden states for each time step. The hidden state is utilized to predict reward, value, and action distribution π. The combination of both long-term and short-term memory is critical for fast adaptation. Long-term memory is achieved through slow gradient updates, whereas short-term memory can be captured within the context length of the transformer. This unique combination allows the model to preserve knowledge across multiple task attempts by retaining memory across trials, even though the environment resets between trials.
- The model benefits from meta-RL training across 1⁰⁴⁰ different partially observable Markov decision processes (POMDPs) tasks. Since transformers are meta-learners, no additional meta step is required.
- Given the size and diversity of the task pool, many tasks will either be too easy or too hard to generate a good training signal. To tackle this, they used an automated curriculum to prioritize tasks that are within its capability frontier.
RT-2 introduces a method to co-finetune a VLM on both robotic trajectory data and vision-language tasks, resulting in a policy model called RT-2. To enable vision-language models to generate low-level actions, actions are discretized into 256 bins and represented as language tokens.
By representing actions as language tokens, RT-2 can directly utilize pre-existing VLM architectures without requiring substantial modifications. Hence, VLM input includes robot camera image and textual task description formatted similarly to Vision Question Answering tasks and the output is a series of language tokens that represent the robot’s low-level actions; see Fig. 6.
Fig 6. RT-2 overview (image taken from RT-2 paper)
They noticed that co-finetuning on both types of data with the original web data leads to more generalizable policies. The co-finetuning process equips RT-2 with the ability to understand and execute commands that were not explicitly present in its training data, showcasing remarkable adaptability. This approach enabled them to leverage internet-scale pretraining of VLM to generalize to novel tasks through semantic reasoning.
3- Foundation Models as State Representation
In RL, a policy’s understanding of the environment at any given moment comes from its “state” which is essentially how it perceives its surroundings. Looking at the RL block diagram, a reasonable module to inject world knowledge into is the state. If we can enrich observations with general knowledge useful for completing tasks, the policy can pick up new tasks much faster compared to RL agents that begin learning from scratch.
PR2L introduces a novel approach to inject the background knowledge of VLMs from internet scale data into RL.PR2L employs generative VLMs which generate language in response to an image and a text input. As VLMs are proficient in understanding and responding to visual and textual inputs, they can provide a rich source of semantic features from observations to be linked to actions.
PR2L, queries a VLM with a task-relevant prompt for each visual observation received by the agent, and receives both the generated textual response and the model’s intermediate representations. They discard the text and use some or all of the models intermediate representation generated for both the visual and text input and the VLM’s generated textual response as “promptable representations”. Due to the variable size of these representations, PR2L incorporates an encoder-decoder Transformer layer to embed all the information embedded in promptable representations into a fixed size embedding. This embedding, combined with any available non-visual observation data, is then provided to the policy network, representing the state of the agent. This innovative integration allows the RL agent to leverage the rich semantic understanding and background knowledge of VLMs, facilitating more rapid and informed learning of tasks.
Also Read Our Previous Post: Towards AGI: LLMs and Foundational Models’ Roles in the Lifelong Learning Revolution
References:
[1] ELLM: Du, Yuqing, et al. “Guiding pretraining in reinforcement learning with large language models.” 2023.
[2] Text2Reward: Xie, Tianbao, et al. “Text2reward: Automated dense reward function generation for reinforcement learning.” 2023.
[3] R2R2S: Yu, Wenhao, et al. “Language to rewards for robotic skill synthesis.” 2023.
[4] EUREKA: Ma, Yecheng Jason, et al. “Eureka: Human-level reward design via coding large language models.” 2023.
[5] MOTIF: Klissarov, Martin, et al. “Motif: Intrinsic motivation from artificial intelligence feedback.” 2023.
[6] Read and Reward: Wu, Yue, et al. “Read and reap the rewards: Learning to play atari with the help of instruction manuals.” 2024.
[7] Auto MC-Reward: Li, Hao, et al. “Auto MC-reward: Automated dense reward design with large language models for minecraft.” 2023.
[8] EAGER: Carta, Thomas, et al. “Eager: Asking and answering questions for automatic reward shaping in language-guided RL.” 2022.
[9] LiFT: Nam, Taewook, et al. “LiFT: Unsupervised Reinforcement Learning with Foundation Models as Teachers.” 2023.
[10] UAFM: Di Palo, Norman, et al. “Towards a unified agent with foundation models.” 2023.
[11] RT-2: Brohan, Anthony, et al. “Rt-2: Vision-language-action models transfer web knowledge to robotic control.” 2023.
[12] AdA: Team, Adaptive Agent, et al. “Human-timescale adaptation in an open-ended task space.” 2023.
[13] PR2L: Chen, William, et al. “Vision-Language Models Provide Promptable Representations for Reinforcement Learning.” 2024.
[14] Clip4Clip: Luo, Huaishao, et al. “Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning.” 2022.
[15] Clip: Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” 2021.
[16] RoBERTa: Liu, Yinhan, et al. “Roberta: A robustly optimized bert pretraining approach.” 2019.
[17] Preference based RL: SWirth, Christian, et al. “A survey of preference-based reinforcement learning methods.” 2017.
[18] Muesli: Hessel, Matteo, et al. “Muesli: Combining improvements in policy optimization.” 2021.
[19] Melo, Luckeciano C. “Transformers are meta-reinforcement learners.” 2022.
[20] RLHF: Ouyang, Long, et al. “Training language models to follow instructions with human feedback, 2022.
Pushing RL Boundaries: Integrating Foundational Models, e.g. was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.